Overklokker Bianbao heeft een ddr4-geheugensnelheid van 6666,6 megatransfers per seconde gehaald. Dat is een nieuw wereldrecord. De overklokker haalde deze snelheid met een Crucial Ballistix Max-geheugenmodule en een Renoir-apu van AMD.
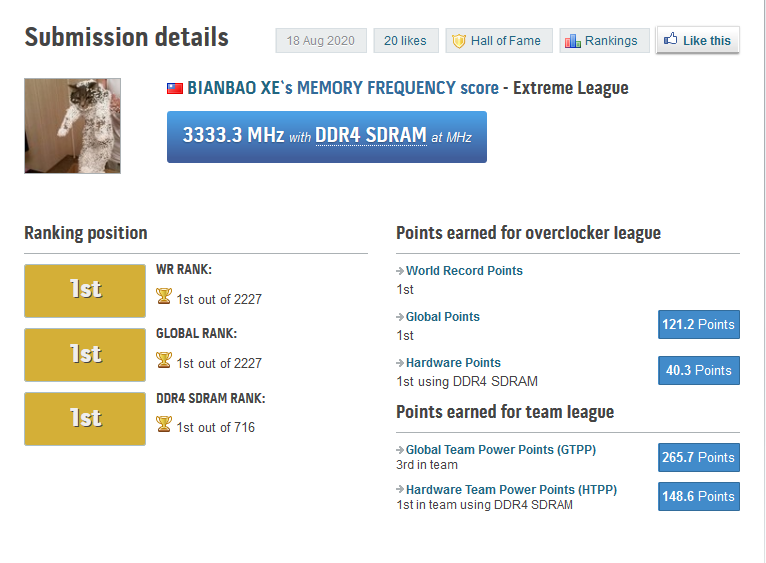
De Taiwanese overklokker gebruikte een systeem met een AMD Ryzen 7 4700GE-apu, een ROG Strix B550-I Gaming-moederbord van Asus, en een enkele Crucial-geheugenmodule van 8GB. Hiermee werd een snelheid van 3333,3MHz behaald, wat gelijkstaat aan 6666,6MT/s.
De gebruikte timings bij de overklok bedroegen 30-27-27-58-127-1. De kloksnelheid van de cpu werd daarnaast verlaagd naar ongeveer 1,89GHz, terwijl de standaard kloksnelheid van een 4700GE 3,10GHz bedraagt. Tegelijkertijd bedroeg de Vcore 1,5V. De overklokker publiceerde het resultaat op HWBot en CPU-Z ter validatie.
Het nieuwe overklokrecord is behaald met behulp van LN2-koeling. Het vorige ddr4-snelheidsrecord bedroeg 6665,4MT/s en stond ook op naam van Bianbao. De overklokker haalde deze snelheid in mei, in combinatie met een Intel Core i9-10900K en G.Skill Trident Z RGB-geheugen. In september 2019 werd voor het eerst een geheugensnelheid van 6000MT/s behaald door Toppc, een andere overklokker.
:strip_exif()/i/2003582984.jpeg?f=imagenormal)
Het Crucial-geheugen in kwestie

:fill(white):strip_exif()/i/2003457858.jpeg?f=thumbmedium)
:fill(white):strip_exif()/i/2003582540.jpeg?f=thumbmedium)
/i/2004611226.png?f=fpa)
:fill(white):strip_exif()/i/2003582984.jpeg?f=thumbmedium)
:strip_exif()/i/2004697878.jpeg?f=fpa)
:strip_exif()/i/2004697890.jpeg?f=fpa)
:strip_exif()/i/2001033895.jpeg?f=fpa)
:strip_exif()/i/2003761796.jpeg?f=fpa)
/i/2001458127.png?f=fpa)
/i/2003059028.png?f=fpa)
:strip_exif()/u/106005/animated%2520garfield.gif?f=community)
:strip_exif()/u/15310/tomato60%252072%2520frames%25205%2520deg%2520per%2520frame%2520optimized%252026%2520colors.gif?f=community)
/u/484268/crop61e4788571a3c_cropped.png?f=community)
/u/103959/crop60e1dda829172_cropped.png?f=community)
/u/533588/crop5c477836e5227_cropped.png?f=community)
:strip_icc():strip_exif()/u/259786/crop66d34575d79ce_cropped.jpg?f=community)
:strip_icc():strip_exif()/u/109168/crop5c6ad3dc9bc0f_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/249917/jaapschaap.jpg?f=community)
/u/605844/crop59996fc59ce42_cropped.png?f=community)
:strip_icc():strip_exif()/u/83337/countess6-nice.jpg?f=community)
/u/205997/crop59f99586a75c5.png?f=community)
:strip_icc():strip_exif()/u/960045/crop5f2039497fd10_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/80624/crop56269c878c330.jpeg?f=community)
:strip_icc():strip_exif()/u/262333/crop55e7812829401.jpeg?f=community)
/u/62384/crop61891f444d6e9.png?f=community)
:strip_icc():strip_exif()/u/147791/crop56e423ed8d794_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/715918/crop6270f596785bb_cropped.jpg?f=community)
:strip_icc():strip_exif()/u/299039/dv3.jpg?f=community)
/u/69397/crop5b20ed488c1d9_cropped.png?f=community)
/u/330720/crop57ef85670bb82_cropped.png?f=community)