Onlineopslagdienst Backblaze heeft de uitvalcijfers van zijn harde schijven in 2016 gepubliceerd. De cijfers tonen aan dat de 8TB-modellen gemiddeld minder vaak uitvallen dan kleinere schijven. Het aantal defecte schijven over het algemeen is afgenomen ten opzichte van vorige jaren.
De dienst heeft zowel de cijfers van heel 2016 als de specifieke cijfers van het vierde kwartaal gedeeld. In dat kwartaal is 1,65 procent van de 8-terabyteschijven gesneuveld, tegenover het gemiddelde van 1,94 procent over alle schijven. Het overgrote deel van de 8-terabyteschijven die Backblaze gebruikt, zijn consumentenmodellen van Seagate, de ST8000DM002. De rest van de 8-terabytemodellen waren een model van HGST en een zakelijke schijf van Seagate. Deze twee modellen hebben in 2016 geen enkele uitvaller gehad.
/i/2001391575.jpeg?f=imagenormal) Backblaze heeft in 2016 besloten om alle schijven die kleiner dan 3TB zijn uit te faseren. Hierdoor zijn er voor deze cijfers geen statistieken meer. Een schijf die opvallend vaak stukgegaan is, is de ST4000DX000, met 13,57 procent. Deze schijf is echter gemiddeld wel al ruim drie jaar oud. Daartegenover staan wel verschillende 3-terabytemodellen van HGST, die ondanks een hogere gemiddelde leeftijd minder vaak stukgegaan zijn. Het bedrijf had eerder een groot aantal 3-terabyteschijven van Seagate in gebruik, waarvan een zeer groot aantal stukging. Dit heeft tot een rechtszaak tegen Seagate geleid.
Backblaze heeft in 2016 besloten om alle schijven die kleiner dan 3TB zijn uit te faseren. Hierdoor zijn er voor deze cijfers geen statistieken meer. Een schijf die opvallend vaak stukgegaan is, is de ST4000DX000, met 13,57 procent. Deze schijf is echter gemiddeld wel al ruim drie jaar oud. Daartegenover staan wel verschillende 3-terabytemodellen van HGST, die ondanks een hogere gemiddelde leeftijd minder vaak stukgegaan zijn. Het bedrijf had eerder een groot aantal 3-terabyteschijven van Seagate in gebruik, waarvan een zeer groot aantal stukging. Dit heeft tot een rechtszaak tegen Seagate geleid.
Ondanks dat Seagate door de uitvalpercentages flinke imagoschade heeft opgelopen, wordt de fabrikant dit jaar niet als het onbetrouwbaarst opgeschreven. Die kroon gaat naar Western Digital, van wie 3,88 procent van alle schijven stukging. HGST, die eigendom van WDC is, blijft de betrouwbaarste fabrikant, met een uitvalpercentage van 0,6 procent.
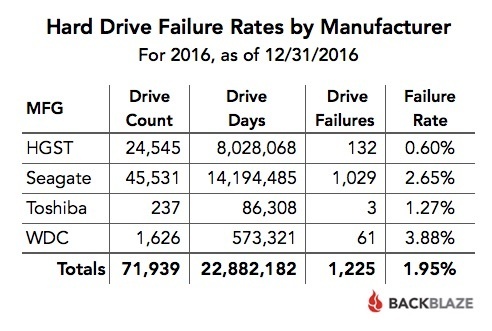 Over het algemeen lijken de harde schijven bij Backblaze minder vaak uit te vallen dan voorgaande jaren. Hoewel het lijkt alsof het uitvalpercentage van de 8-terabytemodellen sterk is afgenomen, geeft Backblaze aan dat er in 2015 slechts 45 schijven waren getest, waarvan er twee uitvielen. Backblaze geeft op 2 februari een online seminar waarin het dieper ingaat op de statistieken.
Over het algemeen lijken de harde schijven bij Backblaze minder vaak uit te vallen dan voorgaande jaren. Hoewel het lijkt alsof het uitvalpercentage van de 8-terabytemodellen sterk is afgenomen, geeft Backblaze aan dat er in 2015 slechts 45 schijven waren getest, waarvan er twee uitvielen. Backblaze geeft op 2 februari een online seminar waarin het dieper ingaat op de statistieken.
/i/2001391579.jpeg?f=imagenormal)

/i/2003033258.png?f=fpa)
:strip_exif()/i/1275386826.jpeg?f=fpa)
:strip_exif()/i/1282562328.jpeg?f=fpa)
:strip_exif()/i/1187938065.gif?f=fpa)
/i/1249829841.png?f=fpa)
/i/1271057694.png?f=fpa)
:strip_exif()/i/1225830346.gif?f=fpa)
/u/274113/N7.png?f=community)
:strip_exif()/u/38813/holland.gif?f=community)
/u/27299/hoofd.png?f=community)
:strip_icc():strip_exif()/u/235816/crop596740581e453_cropped.jpeg?f=community)
/u/326344/crop5cb84a028ec8d_cropped.png?f=community)
/u/69397/crop5b20ed488c1d9_cropped.png?f=community)
/u/98736/crop57f5f8979fbe3_cropped.png?f=community)
:strip_exif()/u/117880/911_gt3rs_60.gif?f=community)
/u/113545/no_wai.png?f=community)
/u/12037/crop5db5cb2525d0a_cropped.png?f=community)
:strip_icc():strip_exif()/u/105829/crop5dafb3f448ec1_cropped.jpeg?f=community)
/u/85941/crop61dd9b39bb021_cropped.png?f=community)
/u/108262/crop65ae40c6d24d8.png?f=community)
/u/349199/crop69f59caff1e30_cropped.png?f=community)
/u/416327/crop5dfb6ea68e892_cropped.png?f=community)
/u/34556/welles60x60.PNG?f=community)
:strip_icc():strip_exif()/u/493201/merc2.jpg?f=community)
/u/335336/crop6700d743324d0.png?f=community)
:strip_icc():strip_exif()/u/48297/diamond-2.jpg?f=community)
:strip_icc():strip_exif()/u/272160/PUNT.jpg?f=community)
:strip_exif()/u/467778/crop5d7a5dd1f296a.gif?f=community)
:strip_icc():strip_exif()/u/21712/crop668d500bcc980_cropped.jpg?f=community)
:strip_icc():strip_exif()/u/413832/crop599d5f783fd46_cropped.jpeg?f=community)
:strip_exif()/u/770835/crop577575510b25e_cropped.gif?f=community)
/u/385795/crop6a1e7a8def7ac_cropped.png?f=community)
{kind=link}