Backblaze heeft een nieuw rapport over de betrouwbaarheid van hdd's in zijn datacenters gepubliceerd. De aanbieder van clouddiensten is grotendeels overgestapt op 4TB-hdd's van Seagate, die veel betrouwbaarder blijken dan de 3TB-varianten.
Seagate kwam de afgelopen jaren regelmatig negatief in het nieuws vanwege de hoge uitvalpercentages van hdd's met opslagcapaciteit van 1,5TB en 3TB. Backblaze gebruikte duizenden van dergelijke hdd's in zijn Storage Pods in datacenters. In de loop van 2015 heeft Backblaze deze hdd's uitgefaseerd en vervangen door andere hdd's. Uit het nieuwe betrouwbaarheidsrapport blijkt dat Seagate-hdd's met een capaciteit van 4TB veel minder problematisch zijn.
Eind 2015 had Backblaze ruim 29.000 Seagate ST4000DM000-hdd's in gebruik, met een gemiddelde leeftijd van 12,2 maanden. Het uitvalpercentage bedroeg 2,99 procent. De hdd's van HGST zijn nog altijd het meest betrouwbaar volgens de statistieken. Het bedrijf gebruikt drie verschillende varianten van 4TB-hdd's van dat merk, in totaal bijna 13.000 stuks. De gemiddelde uitval is minder dan 1 procent. De reden dat Backblaze koos voor 4TB-hdd's van Seagate in plaats van de nog betrouwbaardere HGST's, is dat de modellen die de cloudaanbieder gebruikt niet meer verkrijgbaar zijn en vervangen zijn voor duurdere varianten.
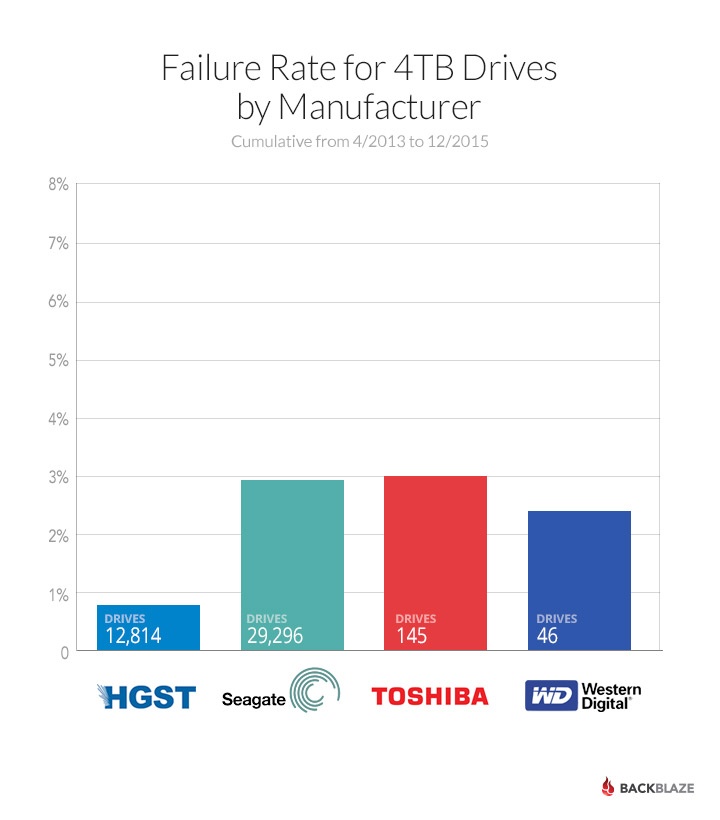

Ook de ST6000DX000-hdd van Seagate met capaciteit van 6TB doet het relatief goed in de test. Van de 1882 exemplaren die Backblaze dit jaar in gebruik heeft genomen is 1,89 procent uitgevallen. Daarmee doen de schijven het beter dan de WD60EFRX-hdd's van 6TB, die een uitvalpercentage van 5,81 procent hebben. Ondanks dat de Seagate 6TB-hdd's betrouwbaarder zijn dan de 4TB-varianten, zijn ze voor Backblaze niet interessant om in te zetten op grote schaal. De prijs per gigabyte is hoger en ook verbruiken de grotere hdd's gemiddeld zestig procent meer energie.
De oudste hdd's die Backblaze nog in zijn datacenters heeft draaien zijn de 2TB-varianten van HGST. De 4489 hdd's hebben een gemiddelde leeftijd van bijna vijf jaar en een uitvalpercentage van 1,55 procent. Opvallend is dat de WD-hdd's over het algemeen slechter scoren dan die van HGST, terwijl WD het moederbedrijf is van laatstgenoemde.
Vorig jaar bleek uit het rapport betrouwbaarheidsonderzoek van Backblaze dat ruim vier op de tien 3TB-hdd's van Seagate de geest gaven. Ook de 1,5TB-varianten vertoonden opvallend veel gebreken, 23,5 procent van deze hdd's viel uit. Het rapport van de cloudaanbieder wordt door advocaten gebruikt in een class action-zaak die onlangs van start is gegaan tegen Seagate. Ook veel consumenten zouden last hebben gehad van problemen met de hdd's en door middel van de zaak willen ze hun geld terugkrijgen en bovendien eisen ze een schadevergoeding voor verloren data.
Net als veel andere cloudaanbieders gebruikt Backblaze reguliere hdd's in zijn datacenters. Hoewel deze schijven niet bedoeld zijn voor continu gebruik en daardoor eerder uit kunnen vallen, weegt dat in het geval van massaopslag op tegen de hogere kosten die speciale hdd's voor servers met zich meebrengen. Eind 2015 had Backblaze 56.224 hdd's in gebruik, begin dat jaar waren dat 39.690 schijven.

:strip_exif()/i/1275386826.jpeg?f=fpa)
:strip_exif()/i/1032120392.gif?f=fpa)
:strip_exif()/i/1187938065.gif?f=fpa)
/i/1253520173.png?f=fpa)
/i/1271057694.png?f=fpa)
:strip_exif()/i/1225830346.gif?f=fpa)
:strip_exif()/u/7013/spunky_main.gif?f=community)
:strip_icc():strip_exif()/u/216854/crop5c1bbcb02dcee_cropped.jpeg?f=community)
/u/27299/hoofd.png?f=community)
:strip_icc():strip_exif()/u/85892/hein.jpg?f=community)
/u/452542/crop57b8a2dd1446b_cropped.png?f=community)
:strip_icc():strip_exif()/u/6764/cergorach.jpg?f=community)
/u/1176/crop635f8931b2b68_cropped.png?f=community)
:strip_exif()/u/54579/Static.gif?f=community)
:strip_icc():strip_exif()/u/78725/train-icon3.jpg?f=community)
:strip_exif()/u/38813/holland.gif?f=community)
:strip_icc():strip_exif()/u/140070/kalief.jpg?f=community)
:strip_icc():strip_exif()/u/210110/crop5cb20f9251261_cropped.jpeg?f=community)
/u/26227/amdklein.JPG?f=community)
:strip_icc():strip_exif()/u/3550/S2462.jpg?f=community)
:strip_icc():strip_exif()/u/157053/crop574c68cea92df_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/430058/crop5fbc250c0c982_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/406693/nuke_supersmall.jpg?f=community)
/u/254093/crop678fb402f18f5_cropped.png?f=community)
/u/313859/crop5fe207cfa819e_cropped.png?f=community)
/u/75323/5procentoog.JPG?f=community)
/u/131439/417785s.png?f=community)
/u/472627/crop5c83fe498b36e_cropped.png?f=community)
:strip_icc():strip_exif()/u/29463/engessa1.jpg?f=community)
{kind=link}
{kind=link}