Een systeem dat kunstmatige-intelligentiesoftware draaide met de naam Libratus heeft vier professionele Texas Hold'em-pokerspelers verslagen bij een toernooi dat twintig dagen duurde. In 2015 wisten menselijke spelers een ai-systeem nog te verslaan.
De Brains Vs. Artificial Intelligence: Upping the Ante-competitie begon 11 januari in het Rivers Casino in Pittsburgh. Vier pokerspeler gingen daar de strijd aan met Libratus bij Heads-Up, No-Limit Texas Hold’em-poker. De vier waren gespecialiseerd in deze vorm van poker voor twee personen en werden beschouwd als 's werelds beste spelers.
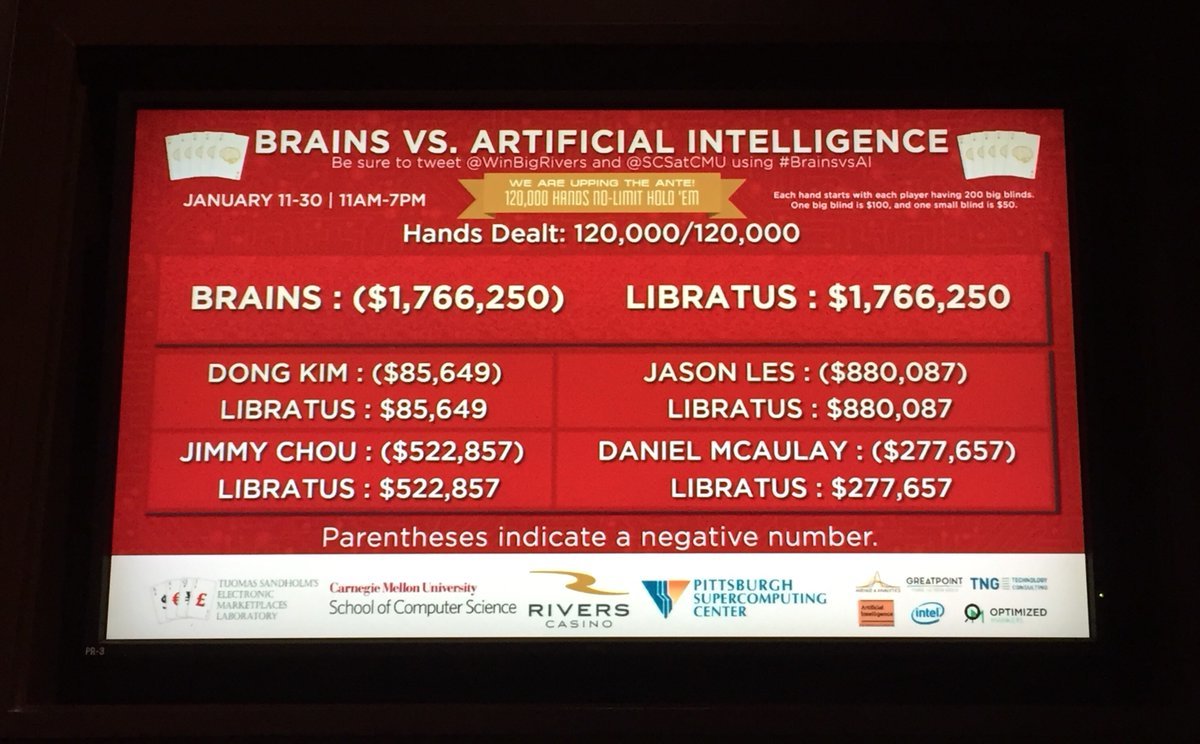
Naarmate het toernooi vorderde bleek al dat Libratus het initiatief naar zich toe trok. Aanvankelijk onderschatten de spelers het programma naar eigen zeggen. "De bot wordt elke dag beter en beter", zei een van hen anderhalve week geleden. In de nacht van maandag op dinsdag bleken ze verslagen te zijn. Daarmee lopen de vier 200.000 dollar mis.
Libratus, Latijn voor 'evenwicht', is ontwikkeld door Tuomas Sandholm, professor computerwetenschappen bij de Carnegie Mellon University, en de student Noam Brown. Het lastige voor de gekozen vorm van poker voor de ai is dat bluf een belangrijke rol speelt, evenals het nemen van beslissingen op basis van ontbrekende of misleidende informatie. Naarmate het toernooi vorderde, konden de algoritmes van Libratus de strategie verbeteren.
De berekeningen om zich aan te passen aan de speelwijze van de menselijke tegenstanders gebeurden 's nachts, na afloop van de wedstrijden van de dag in het Pittsburgh Supercomputing Center. Libratus draait daar vanaf het Bridge-cluster, dat in samenwerking met Hewlett Packard Enterprise is gebouwd. Het bestaat uit 800 nodes en beslaat daarmee 22.400 cores. Het programma kon 600 van die nodes, met elk 128GB ram, aan het werk zetten.
Volgens de onderzoekers hebben ze met de overwinning de lat voor kunstmatige intelligentie weer een stuk hoger gelegd. Uiteindelijk kunnen programma's als Libratus ingezet worden voor onderhandelingen over zakelijke overeenkomsten en het maken van medische behandelingen, verwachten ze.
Het is de zoveelste keer dat een ai een mens in een spel verslaat. Prominente eerdere overwinningen waren die van IBM's Deep Blue tegen Kasparov bij schaken en Googles DeepMind AlphaGo tegen LeeSe-dol bij Go.

:strip_exif()/i/1295870878.gif?f=fpa)
/i/2001673275.png?f=fpa)
/i/1261384058.png?f=fpa)
/i/1233670851.png?f=fpa)
:strip_exif()/i/1315896554.jpeg?f=fpa)
:strip_exif()/i/1240824097.jpeg?f=fpa)
/i/2001015047.png?f=fpa)
:strip_icc():strip_exif()/u/585680/olliolli-buttonjpg-df0ded_60w.jpg?f=community)
:strip_icc():strip_exif()/u/694150/crop59aeadc815d84_cropped.jpeg?f=community)
/u/349199/crop69f59caff1e30_cropped.png?f=community)
:strip_icc():strip_exif()/u/428264/t6vldloofbntjgsxehen.jpg?f=community)
:strip_exif()/u/7759/red_cat.gif?f=community)
:strip_exif()/u/27690/Misc_-_Boy.gif?f=community)
/u/30346/crop6571ad31b4cbc_cropped.png?f=community)
/u/333981/crop5959c7875e9d2_cropped.png?f=community)
:strip_icc():strip_exif()/u/321234/G8Tpp.jpg?f=community)
:strip_exif()/u/36662/OddesE.gif?f=community)
:strip_exif()/u/482870/crop576d9204a610b_cropped.gif?f=community)
:strip_exif()/u/777/pennywise.gif?f=community)
/u/3626/front-kabels.png?f=community)
/u/355158/crop575b478b97ccb.png?f=community)
:strip_icc():strip_exif()/u/98843/tmpgeel601.jpg?f=community)
:strip_icc():strip_exif()/u/1981/Image00001.jpg?f=community)
/u/49730/babby%2520tux.png?f=community)
:strip_icc():strip_exif()/u/14399/haanwcostfu.jpg?f=community)
:strip_icc():strip_exif()/u/335682/Hobbes.jpg?f=community)
:strip_icc():strip_exif()/u/105829/crop5dafb3f448ec1_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/109168/crop5c6ad3dc9bc0f_cropped.jpeg?f=community)