Google DeepMind gaat een miljoen oogscans analyseren om met behulp van machine learning oogaandoeningen die tot blindheid kunnen leiden, in een vroeg stadium te kunnen detecteren. Google DeepMind werkt hiervoor samen met de Britse National Health Service.
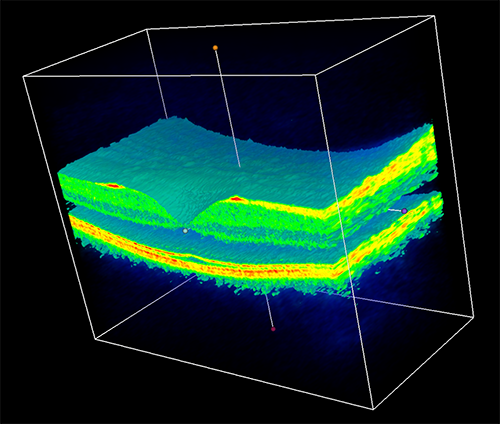 De geanonimiseerde oogscans worden samen met aanvullende informatie over de conditie van ogen aangeleverd door het Moorfields Eye Hospital. Specialisten gebruiken de digitale scans van het netvlies om oogaandoeningen te diagnosticeren en een behandelplan op te stellen.
De geanonimiseerde oogscans worden samen met aanvullende informatie over de conditie van ogen aangeleverd door het Moorfields Eye Hospital. Specialisten gebruiken de digitale scans van het netvlies om oogaandoeningen te diagnosticeren en een behandelplan op te stellen.
Daarbij gaat het om fundus-foto's, oftewel van het netvlies, en om optische coherentietomografie, waarbij dwarsdoorsnedes van ogen worden gevormd met behulp van interferometers. Het Moorfield Eye Hospital maakt wekelijks drieduizend scans op basis van optische coherentietomografie. De analyse is complex en tijdrovend, en methodes om dit werk met traditionele computersoftware te doorgronden, liepen op weinig uit volgens Google.
Google denkt dat de machine-learningalgoritmes die zijn dochterbedrijf DeepMind voor het project ontwikkelt, wel een belangrijke rol kunnen spelen bij de analyse van de oogaandoeningen, om detectie in een vroeg stadium mogelijk te maken. De analyses moeten de oogdeskundigen helpen bij het sneller vaststellen van een diagnose.
Het gaat daarbij om twee specifieke aandoeningen die tot gezichtsverlies kunnen leiden: diabetische retinopathie en leeftijdsgebonden maculadegeneratie. Diabetische retinopathie wordt veroorzaakt door suikerziekte en maculadegeneratie is de naam voor het afsterven van de lichtgevoelige kegeltjes in het oog. Wereldwijd zouden meer dan 100 miljoen mensen hiermee te maken krijgen.
Het onderzoek loopt vijf jaar en na die periode belooft Google DeepMind alle data die ontvangen is als onderdeel van de overeenkomst te vernietigen. DeepMind kreeg vooral bekendheid met zijn AlphaGo-programma dat Zuid-Koreaanse wereldkampioen Lee Sedol bij het bordspel Go wist te verslaan.
Google zet machine learning voor steeds meer diensten in, onder andere voor spraakherkenningssoftware, voor het bouwen van de afbeeldingenzoeker voor Google Photo en het automatisch voorzien van bijschriften bij foto's. De technologie wordt ook gebruikt voor SmartReply in Inbox. Google nam DeepMind begin 2014 over.
![]() Helaas!
Helaas!
De video die je probeert te bekijken is niet langer beschikbaar op Tweakers.net.

/i/2001673275.png?f=fpa)
/i/2000658159.png?f=fpa)
/i/1233670851.png?f=fpa)
/i/2001015047.png?f=fpa)
:strip_exif()/i/1322564626.jpeg?f=fpa)
:strip_exif()/i/1297759428.gif?f=fpa)
:strip_icc():strip_exif()/u/218679/Michael_Melgar_LiquidArt_resize_droplet.jpg?f=community)
:strip_exif()/u/220180/Animation11.gif?f=community)
/u/380683/crop5848673f28e5a.png?f=community)
/u/277712/crop5f2ffda303aff_cropped.png?f=community)
/u/441020/crop577ad2276cade.png?f=community)
/u/135684/crop5857da1567fae_cropped.png?f=community)
:strip_icc():strip_exif()/u/43153/octopus.jpg?f=community)
/u/152864/crop59af8ee117886_cropped.png?f=community)