De Nederlandse Wetenschappelijke Raad voor het Regeringsbeleid concludeert dat de huidige regels burgers onvoldoende beschermen omdat deze zich alleen richten op het verzamelen en delen van gegevens. Er zijn nieuwe regels nodig, concludeert het adviesorgaan.
De WRR breekt big data-processen op in drie fasen: verzameling, analyse en gebruik van gegevens. Omdat de juridische regels zich op dit moment alleen richten op het verzamelen en delen van gegevens, vallen analyse en gebruik van de gegevens vooralsnog buiten de regels, waardoor de nieuwe regels nodig zijn. De raad wil niet adviseren de regelgeving rond het verzamelen van data te verzwaren, omdat dit een groot deel van de 'belofte van Big Data in de kiem zou smoren'.
De raad stelt daarom een aantal nieuwe kernbestanddelen voor bij het gebruik van big data, zoals het wettelijk vastleggen van de verantwoordelijkheid van een gegevensverwerkende partij en strikte handhaving van het verbod op geautomatiseerde besluitvorming en bestrijding van semi-geautomatiseerde besluitvorming in de gebruiksfase. Dat laatste betekent dat een systeem geen zelfstandige actie mag ondernemen aan de hand van eigen interpretatie van data. De voorkeur ligt voor de raad bij een combinatie van big-data-analyse en menselijke beoordeling. De raad noemt het Amerikaanse voorbeeld waarbij computers personen op een no-fly-lijst zetten zonder menselijk oordeel.
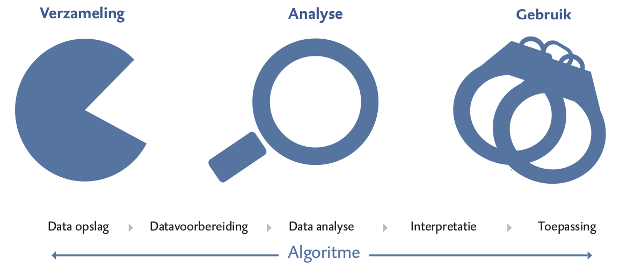
Ook moeten voor burgers en maatschappelijke organisaties, zoals burgerrechtenbewegingen, betere mogelijkheden komen om wetgeving en beleid rond big data-toepassing juridisch te laten toetsen. De WRR wil verder dat er nieuwe regels komen over de toelaatbare foutmarges bij het opstellen van profielen in de fase waarin gegevens worden geanalyseerd, onder andere door het verstevigen van toezicht op de gebruikte algoritmes voor de analyses.
De WRR geeft wel aan in het rapport dat het niet makkelijk is om in kaart te brengen "hoe en in welke mate big data zich in het Nederlandse veiligheidsdomein manifesteert." Dit komt doordat er vaak sprake is van geheimhouding en experimentele toepassingen.
Een van de kernbestanddelen uit het nieuwe kader moet ook zorgen voor meer duidelijkheid over wat instanties doen met de verwerking van gegevens die bedoeld zijn voor de veiligheid. Een van de zorgen is bijvoorbeeld dat data die verzameld zijn voor een bepaald doel, ook voor iets anders gebruikt worden. Dat alles vraagt ook om een extra investering in de kennis van de verweking van big data-analyses bij toezichthouders zoals de Autoriteit Persoonsgegevens en de Commissie van Toezicht op de Inlichtingen- en Veiligheidsdiensten. De WRR maakte het rapport op verzoek van het kabinet en is te downloaden via de website van het adviesorgaan.

/i/2004620466.png?f=fpa)
/i/2001714923.png?f=fpa)
:strip_exif()/i/1264755098.gif?f=fpa)
:strip_exif()/i/1296649242.gif?f=fpa)
/i/1257927236.png?f=fpa)
:strip_exif()/i/1034032919.jpg?f=fpa)
:strip_exif()/i/1298020644.gif?f=fpa)
:strip_exif()/u/777/pennywise.gif?f=community)
/u/148936/rcx.png?f=community)
:strip_exif()/u/36662/OddesE.gif?f=community)
:strip_exif()/u/70909/BlueKachina_60x60.gif?f=community)
/u/715027/crop6047c50ae8d4c.png?f=community)
:strip_icc():strip_exif()/u/541367/crop6679306ef1f8f_cropped.jpg?f=community)
:strip_icc():strip_exif()/u/489983/crop5db33928bbeea_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/269054/crop6064049cee9ab_cropped.jpg?f=community)
:strip_icc():strip_exif()/u/79614/Family-Guy-Victory-is-Ours.jpg?f=community)
/u/3626/front-kabels.png?f=community)
/u/99142/crop62758e978b3e3_cropped.png?f=community)