Het is raar om te beseffen, maar het is slechts iets meer dan anderhalf jaar geleden dat ChatGPT uitkwam. Plaatjesgenerators als Stable Diffusion kwamen pas twee jaar geleden uit. Het was al gauw duidelijk dat de AI-hype wel snel, maar toch geen intercity was; als een stoptrein doet hij elk station aan waar software is. Of anders gezegd: in veel van de programma's en diensten die we gebruiken, zit of komt generatieve kunstmatige intelligentie. Het is al sinds begin 2023 duidelijk dat grote techbedrijven op dat spoor zaten, maar nu zien we pas welk traject ze daarbij precies volgen.
Inmiddels dendert de AI-trein al anderhalf jaar door en kunnen we zien hoe de implementatie precies verschilt. De techgiganten hebben verschillende soorten functies bedacht, maar veel komen overeen. Nu Apple onlangs ook zijn grote presentatie over macOS Sequoia en iOS 18 heeft gegeven, hebben alle techgiganten in elk geval iets gezegd over hun plannen voor integratie van generatieve kunstmatige intelligentie.
Daarmee kunnen we de overeenkomsten en verschillen op een rij zetten. Wat doen Apple, Google, Meta en Microsoft verschillend, en wat doen ze hetzelfde? Bij techgiganten hoort normaal gesproken ook Amazon, maar vanwege het beperkte aantal diensten voor consumenten in Nederland hebben we dat weggelaten uit dit overzicht. Het gaat hier dus niet om de precieze functies die ze in gedachten hebben met generatieve AI, maar op welke manier ze het aanbieden en integreren van kunstmatige intelligentie hebben aangepakt.
Bannerafbeelding bovenaan en op frontpage: laremenko / Getty Images
Kunstmatige intelligentie
Het uitgangspunt
Wat belangrijk is, is de uitgangspositie van de diverse techgiganten toen de AI-hype eind 2022 met volle kracht begon. Daarom nemen we even door waar ze stonden met zaken die ertoe doen om van deze hype gebruik te kunnen maken: AI-onderzoek, capaciteit in datacenters, platforms om AI op uit te rollen en factoren als investeringen en samenwerkingen.
De grote AI-onderzoeker onder de techbedrijven is al jaren Google. Het noemde zichzelf vanaf 2016 een 'AI-first'-bedrijf en heeft al jaren diensten die sterk leunen op het eigen onderzoek naar kunstmatige intelligentie. Meer dan tien jaar geleden was daar Google Now, kaarten die op basis van informatie op de telefoon en algoritmes dingen weergaven waarvan de software dacht dat je ze nodig ging hebben. Ook de gezichtsherkenning in Google Foto's is een bekend voorbeeld daarvan, net als de mogelijkheid in Google Foto's om met woorden te zoeken naar objecten als 'coupé'. Google is ook de uitvinder van de transformer: de T in GPT.
Microsoft timmerde ook al langer aan de weg met AI-onderzoek, net als Meta. Dat gebeurde wel wat meer op de achtergrond. Een belangrijke overeenkomst is dat beide bedrijven toestaan dat onderzoekers die in dienst zijn, publiceren over hun werk. Dat is een argument voor onderzoekers om wel of niet voor een bepaald bedrijf te werken.
Apple heeft daar lang moeilijk over gedaan en daar heeft het bedrijf veel last van gehad. Een belangrijk voorbeeld is Siri. De stemassistent bestaat al sinds 2011, maar echt goed werd hij nooit. Siri kwam voort uit een overname van de ontwikkelaar van een app met die naam in 2010. Wel integreert Apple al jaren een neural engine in zijn socs voor machinelearningtaken, zoals beeldherkenning. Onder meer de Camera-app en Foto's-app hebben daarvan geprofiteerd.
Datacenters
Om AI-modellen te kunnen trainen en om AI-diensten te kunnen aanbieden die via een internetverbinding werken, is veel rekenkracht nodig. Dat gebeurt in datacenters en op dat gebied hadden Microsoft en Google de beste uitgangspositie. Dat komt door een heel andere divisie die zij hebben; beide bieden hostingdiensten aan via Azure en Google Cloud. Bovendien heeft Google voor YouTube toch al veel ruimte en bandbreedte nodig. Specifiek voor de Benelux hebben beide bedrijven de beste uitgangspositie, want de datacenters staan in Nederland. Beide bedrijven hebben datacenters in het Noord-Hollandse Middenmeer en Google bij de Groningse Eemshaven.
Meta en Apple moeten het doen met veel minder datacenters, die bovendien verder weg staan. Beide hebben de dichtstbijzijnde in Denemarken. Daarnaast heeft Meta locaties in Ierland en Zweden. Meta heeft het wel geprobeerd in Zeewolde. Apple heeft ook locaties in Denemarken en Ierland, maar het heeft wereldwijd niet zoveel locaties als de andere bedrijven.
Googles datacenter in Eemshaven
Platforms
Waar kun je AI het best gebruiken? Idealiter heb je zowel de hardware als het besturingssysteem op een apparaat in handen, want dan kun je het meest uit AI halen. Daarom heeft Apple op dit gebied de beste uitgangspositie; het maakt de socs in zijn apparaten en ontwikkelt de besturingssystemen. Daarbij moeten we aanmerken dat de uitgangspositie goed was, maar dat Apple conservatief is geweest bij vooral zijn iPhones. Waar zijn Apple Intelligence zal werken op Macs en iPads sinds 2021, moet je een iPhone 15 Pro of Pro Max hebben, omdat op andere versies het werkgeheugen tekortschiet. Met hardware en OS in handen kan Apple wel als beste AI-diensten inbouwen en onder de aandacht brengen.
IPad Pro 2021 12,9"
Google heeft ook een goede uitgangspositie doordat het twee grote platforms heeft en eigen hardware. De eigen Tensor-socs in Pixel-apparaten hebben een geringe marktpositie, maar Google wil die wel optimaal uitbuiten en gebruikt AI-diensten al jaren als verkoopargument. Buiten dat heeft het Android, dat op het merendeel van de smartphones wereldwijd draait. Daarnaast heeft het Chrome en ChromeOS in handen. Als browser heeft Chrome een leidende positie op de desktop en daarin AI bouwen geeft Google ook de kans om het direct bij veel gebruikers onder de aandacht te brengen. Daarnaast heeft het met Workspace een aandeel op de zakelijke markt.
Microsoft heeft ook twee ijzers in het vuur. Windows is nog altijd het grootste besturingssysteem ter wereld en Microsoft 365 is groot op de zakelijke markt. Daarmee kan Microsoft dus AI-diensten integreren op een manier die veel gebruikers en klanten zullen tegenkomen.
Meta moet het hebben van apps: WhatsApp uiteraard, naast Instagram en Facebook. Het heeft verder met de Quest-headsets ook hardware, maar die markt is relatief klein. Meta heeft weliswaar veel gebruikte apps, maar de mogelijkheden voor integratie zijn beperkter dan bij een browser of besturingssysteem, dus als uitgangspositie is dat wel iets minder.
Trainingsdata
Hoe meer trainingsdata je kunt verkrijgen, hoe beter het is voor AI-modellen. Het zijn grote modellen die baat hebben bij zoveel mogelijk input. Daarvoor kun je het wereldwijde web leegplukken en dat hebben diverse bedrijven ook gedaan. In dat opzicht hebben alle bedrijven dus een gelijk speelveld, want hoewel nu duidelijk is dat het juridisch discutabel is, is dat wel wat er is gebeurd.
Er is echter ook veel menselijke communicatie niet openbaar en die kan eveneens trainingsdata zijn. De uitgangspositie van Google is daarbij goed. Niet per se omdat het met Gmail en Google Docs op een berg info zit; Google zegt dat het die data niet gebruikt. Geen van de bedrijven zegt privédata te gebruiken. Meta wilde dat wel, maar heeft dat plan in elk geval in de EU afgeblazen.
Google heeft nog altijd de beste toegang tot trainingsdata, omdat het bedrijf het web toch al afspeurt voor zijn zoekmachines. Met YouTube heeft het naast de populairste zoekmachine ook de een na populairste in handen. Microsoft heeft ook een zoekmachine en Meta heeft op veel pagina's een pixel staan. De enige die standaard geen manier heeft om het hele internet te scrapen, is Apple. Nu is daar een mouw aan te passen, maar het is wel een kleine achterstand als je begint met de ontwikkeling van een AI-model.
Investeringen
Soms gok je goed in het leven en Microsoft is al jaren investeerder in OpenAI. Inmiddels is Microsoft ook de eigen modellen aan het ontwikkelen, maar dankzij de samenwerking met OpenAI kon het zo snel Bing Chat en andere AI-diensten uitbrengen.
Apple heeft wel veel AI-bedrijven overgenomen, maar daarbij ging het altijd om kleine bedrijven die een klein deel van de AI-puzzel zouden kunnen leggen. Meta is afgelopen jaren vooral bezig geweest met de metaverse en had dus in eerste instantie de focus niet op generatieve AI. Google vertrouwde op eigen onderzoek en heeft dus weinig samenwerkingen met andere bedrijven op dit gebied.
Hoe het werkt
Alle grote techbedrijven hebben dus AI-functies aangekondigd, maar de werking ervan verschilt. Er zijn de verschillende platforms waarop het wordt aangeboden, de functionaliteit verschilt en er is het verschil tussen gratis en betaalde functionaliteit.
Bedrijf
Apple
Google
Meta
Microsoft
Offline?
Zoveel mogelijk
Een deel
Nee
Een deel
Betaald?
Nee
Een deel
Nee
Een deel
Opensource?
Nee, maar
Nee
Ja
Nee
Zakelijk gebruik?
Nee
Ja
Ja
Ja
Nederlands?
Nee
Ja
Een beetje
Ja
Offline werken
Apple is het bedrijf dat de meeste aandacht heeft besteed aan de offlinewerking van zijn modellen. Nu is het lastig te schatten hoeveel offline gebeurt, want de bèta waar dat in zit, is nog niet beschikbaar. Die komt vermoedelijk komende maand.
De filosofie is in elk geval dat het drie miljard parameters tellende model op het apparaat zoveel mogelijk afhandelt. Dat is een klein model, dus de vraag is hoe nuttig het zal zijn. Bovendien is onbekend hoe de algoritmes werken die beslissen of een taak op het apparaat of via de cloud moet gaan.
Apple heeft drie tredes: op het apparaat, via Private Cloud Compute en via een AI-model van een externe partij; in de VS is dat ChatGPT van OpenAI. Apple heeft al gezegd dat bijvoorbeeld Google Gemini daar bij zou kunnen komen en het is mogelijk dat er in China bijvoorbeeld een andere aanbieder komt. Private Cloud Compute zijn machines in datacenters van Apple die voorzien zijn van Apple-chips en een hiervoor gemaakt besturingssysteem, en die voor deze taken zijn gemaakt. Daardoor kan niemand, ook Apple niet, privédata uit de prompt of de meegestuurde data halen. Het is een vernuftig systeem dat goed past bij het beleid van privacybescherming dat Apple in alle landen behalve China voert.
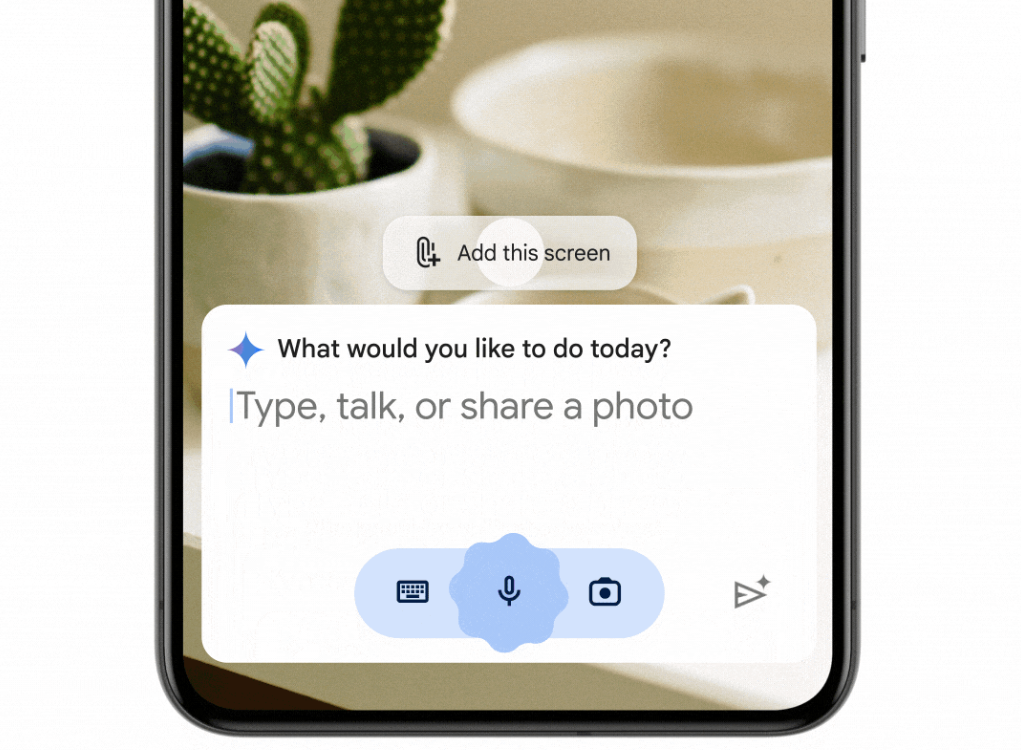
Google doet dat deels ook. Het zet op de eigen Pixel-telefoons het Gemini Nano-model, het kleinste model uit de Gemini-familie. Dat kan ook draaien op telefoons van andere fabrikanten en dat gebeurt ook; de Samsung Galaxy S24 draait Gemini Nano en er zouden meer telefoons gaan volgen.
Microsoft volgt diezelfde lijn, maar doet dat breder; er komen Copilot+-pc's die een neurale chip aan boord hebben die een minimale snelheid halen. Dat moet ook veel offlinefuncties mogelijk maken. Meta is de enige die daar geen gebruik van kan maken, omdat WhatsApp, Instagram en Facebook op zoveel verschillende soorten hardware moeten draaien.
Betaalde abonnementen
Google Gemini op Android
AI-diensten aanbieden is niet gratis, en Microsoft en Google kiezen voorlopig ongeveer hetzelfde pad. Een deel van de AI-functies is gratis te gebruiken en voor een deel is een betaald abonnement nodig. Bij Microsoft zit Copilot onder meer in Windows, browser Edge en zoekmachine Bing als gratis dienst, en is het betaald voor Word, PowerPoint en Excel bijvoorbeeld.
Google doet het iets anders. Het betaalde abonnement biedt meer opslag en een duurder abonnement biedt ook meer AI-functies, zoals toegang tot een betere versie van Gemini. Ook zit Gemini in Gmail en Docs voor het AI Premium-abonnement, dat ten opzichte van het normale Premium-abonnement 12 euro per maand duurder is.
Meta zet zijn AI simpelweg in zijn diensten en vereist verder geen abonnement. Apple gaat hetzelfde doen; Apple Intelligence wordt gratis te gebruiken voor iedereen met een compatibel apparaat. De integratie met ChatGPT is ook kosteloos, maar voor geavanceerdere functies is het abonnement van OpenAI nodig.
Opensource
Meta is de enige die zijn belangrijkste model, Llama, als opensourceversie beschikbaar stelt. Llama 2 kwam vorig jaar al uit en dit jaar zal het gaan om Llama 3. Uiteraard zijn er diverse versies, maar het opensource beschikbaar stellen zorgt ervoor dat veel opensourcetoepassingen van AI ook gebruikmaken van Llama.
Apple heeft wel AxLearn, de library die het gebruikt om modellen te trainen, en AxLearn is wel opensource. Het bedrijf zet bovendien de nodige informatie over de modellen online, maar écht opensource is het niet. Microsoft heeft veel van Copilot gebaseerd op GPT-modellen van OpenAI, maar die zijn in tegenstelling tot wat de naam doet vermoeden, niet opensource en er is relatief weinig data beschikbaar over hoe het werkt. Google is ook niet zo open over hoe Gemini precies in elkaar steekt.
Zakelijk en Nederlands
Google en Microsoft zijn het actiefst op de zakelijke markt en pushen hun AI-diensten daar dan ook hard. Er zijn abonnementen voor verkrijgbaar en in veel software die de bedrijven leveren, is een variant van AI ingebakken. Meta doet ook wel wat op de zakelijke markt en gebruikt daar ook AI voor. Zo is er een dienst om eenvoudige vragen van klanten via WhatsApp door een AI-dienst te laten beantwoorden. Apple heeft tot nu toe geen enkele vorm van zakelijke AI aangekondigd.
Omdat Google en Microsoft het verst zijn met integratie van AI in alle diensten, is het ook logisch dat zij de meeste aandacht hebben voor talen. Beide hebben dan ook diensten die werken in het Nederlands. Llama van Meta doet dat standaard heel beperkt, al zit er wel wat Nederlandse training in. Apple Intelligence heeft vooralsnog geen ondersteuning voor Nederlands. Het bedrijf zegt dat meer talen volgend jaar volgen, maar wil niet zeggen of Nederlands daartussen zit.
Nederlandse taalmodellen
Tot slot
De uitgangspositie en implementatie van AI-diensten verschillen enorm tussen de techgiganten. De grootste overeenkomsten zitten daarbij tussen Google en Microsoft. Beide bedrijven hebben zakelijke diensten en consumententoepassingen, en kiezen voor een mix van gratis en betaalde functies. Bovendien hebben beide datacenters in Nederland en een besturingssysteem om die AI-diensten in te kunnen integreren.
Meta is een buitenbeentje, want het heeft geen eigen platforms. De status van underdog kun je ook aflezen aan het feit dat Llama opensource is. Dat maakt Meta voor AI-onderzoekers aantrekkelijker en leidt tot meer gebruik van Meta's modellen buiten de eigen apps om.
Apple kiest een aanpak die bij het eigen beleid past: gericht op AI op het apparaat draaien of op een daarvoor ingerichte server én gericht op consumenten gratis diensten aanbieden. Apple laat zich voorstaan op de integratie van hardware en software, en dat blijkt ook uit zijn AI-aanpak. Het is bovendien zoals zo vaak niet de eerste met nieuwe functionaliteit, maar het is wel gelijk een complete en geïntegreerde aanpak.
Niet alleen voor Apple, maar voor alle bedrijven is AI een verlengstuk van wat ze toch al deden. De filosofie en de verdienmodellen sluiten aan bij wat de techgiganten al deden en de implementatie past bij de focus die ze al hadden. Daarmee is AI voorlopig een geïntegreerd onderdeel geworden van de besturingssystemen, software en diensten die we gebruiken. Net zoals het spoor en de trein in de negentiende eeuw spannend en nieuw waren, is generatieve AI dat nu. De trein is gewoon infrastructuur, een van de manieren om van A naar B te komen. Straks is AI dat ook.
Render van een trein, geen generatieve AI. Illustratie: Getty Images
Wat ik nog wat mis is waar de concurrentie daadwerkelijk zit, want dat maakt het veel eenvoudiger om te zien wie waaraan wil werken.
Apple doet mee omdat ze op de desktop zien dat Microsoft op ieder moment kan stoppen met Office (incl Outlook en Teams) op Mac, of de Mac versies kan achterstellen. Daarnaast op mobiel concurreren ze met Google, waar het echter niet nog duidelijk is of GenAI op OS-niveau wel een rol heeft.
Kleinere concurrentiestrijd is er tussen Google en Microsoft op Search (waar GenAI echter niet lijkt te werken).
Google en Meta hebben hun primaire business in de advertentiemarkt, maar GenAI speelt daar volgens mij geen rol.
Meta heeft dus eigenlijk geen betekenisvolle concurrentie met de andere drie, daarom kunnen ze ook een heel eigen pad kiezen.
Echter is er ook nog de achtergrond. Apple is een hardwarebedrijf, de rest doen software en internetservices. De bedrijven zijn echter heel anders qua productportfolio.
Daarnaast is Google de enige waarvoor AI altijd al hun business is geweest. Het bedrijf is letterlijk ontstaan vanuit het PageRank algoritme dat is ontworpen door de oprichters van Google tijdens hun doktoraat aan Stanford. Hiermee hebben ze het web toegankelijker gemaakt. Later zijn ze overgestapt naar Information Retrieval technieken omdat ze zo veel query+click data hadden dat de link-structuur van het web minder informatie bevatte dan het gezamenlijke zoekgedrag van mensen. Het mag duidelijk zijn dat Google een enorme voorsprong heeft qua focus om meer innovatie rond AI te brengen (bijv. transformers komen ook van hen), daarom was het des te verbazingwekkender dat OpenAI hen zo heeft kunnen verrassen. Na 1,5 jaar is het echter wel duidelijk dat Search maar beperkt te vrezen heeft van Chatbots, want als je betrouwbare informatie wil vinden is Search zonder GenAI de enige weg.
AI is veel meer dan alleen de huidige LLM hype. De titel zou beter zijn als "Iedere techgigant doet iets met LLM" gezien het voornamelijk daar over gaat.
Hier erger ik mij ook kapot aan. Er zijn zo veel meer toepassingen die extreem interessant zijn, naast die LLMs. Zo werkt een bedrijf in Belgie aan een AI die dmv retina foto's early onset Alzheimer's, Parkinson en andere degeneratieve hersenziektes zou moeten gaan herkennen. Onderzoekers stelden de vraag of AI dit zou kunnen nadat zij er per ongeluk achter kwamen dat AI in retina fotos ook het geslacht van de patiënt kon bepalen. We weten nog steeds niet hoe de AI dit kan, maar het is wel > 90% accuraat.
Dat iets 90% accuraat is, wil niet zeggen dat het goed is.
Van een Engels/Ierse professor geleerd, zij doet onderzoek naar dergelijke claim op basis van geneeskunde en wiskunde (wiskundige modellen)
Zij gebruikte volgende voorbeelden:
Voorspellen of iemand homo is of niet op basis van een foto.
Door iedereen als hetero te voten, haal je een score van ongeveer 90%. Dat is statistisch correct, maar maakt je niet bepaald goed in beoordelen van foto's en geaardheid
Idem met score voor M/V en zo had ze nog meer voorbeelden.
Het gaat er om hoe je aan die 90% komt en tevens hoe je false negatives of false positives eruit haalt zodat die alsnog menselijk beoordeeld worden.
Die genoemde 90% kan zowel juist heel matig zijn, of juist heel goed.. Laten we hopen op het laatste
Wat je aanhaalt is een interessant stukje wiskunde om de effectiviteit van medicijnen te bepalen.
Maar dat is in een sample waar de groepen ongelijk zijn. In dit geval is het 50/50 waardoor dit argument niet opgaat.
Het was in ieder geval goed genoeg om de AI in te zetten voor screening naar neurale degeneratieve ziektes. En ook al slagen ze er niet in, dat vind ik interessante toepassingen van machine learning.
In dit geval is het 50/50 waardoor dit argument niet opgaat.
Klopt dat? Snel zoekende op Pubmed
A large-scale study performed in the United States revealed that in diabetic patients over the age of 40 years, men show a 50% higher prevalence of diabetic retinopathy than women.
en
Men have a higher prevalence of diabetic retinopathy compared to women, suggesting that male sex may be a risk factor for retinopathy development.
Echter, niet alle studies komen tot dezelfde conclusie. De LALES-studie (ze vonden wel een hogere prevalentie van zichtbedreigende DR bij mannen) en de UKPDS 50-studie vonden geen statistisch significant verschil in de incidentie of prevalentie van de ziekte tussen man en vrouw. Andere onderzoeken wijzen echter op een hoger risico voor mannen, vaak in samenhang met hogere HbA1c-niveaus en bloeddrukwaarden.
[Reactie gewijzigd door jdh009 op 23 juli 2024 00:41]
Men haalt hier twee dingen door elkaar, en doet tegelijkertijd een hoop aannames. 50% is man en 50% is vrouw. AI kan met grote nauwkeurigheid het geslacht bepalen van gezonde retinascans. Bron
De markers waarmee de AI dit doet zijn voor ons niet bekend. Dus onderzoekers gaan nu ook zoeken naar markers degeneratieve hersenziektes, met AI. En daar heb ik al naar gelinkt in mijn eerdere bericht.
Hoezo is niet bekend welke proces-data een zeker verband heeft met een ziekte?
Volgens mij, als je iets relevants vindt mbv AI-chips en patroonherkenning ga je dat toch (langzaam) volledig inzichtelijk simuleren en zo een vermoedelijk zichtbaar kenmerk vaststellen?
Eens dat het goed is dat AI ingezet wordt, dat men leert en meer! Helemaal mee eens.
Hij gaat mij om de biased uitspraken die mensen daar aan koppelen.
Daarom ook jouw opmerking. 50/50. Zonder enige contecxt kun je niets met die opmerking.
* Stel je heb 50 vrouwen en 50 mannen in een sample groep.
* Alle 50 mannen roken, alle 50 vrouwen niet.
* Een onderzoek naar longkanker kun je dan uitleggen dat je 50/50 sample van V/M klopt. Je onderzoek toch niet lekker zijn. Sterker nog, zoals @jdh009 aandraagt; je heb zelfs verschillen door het verschil tussen vrouw en man.
Hoe nuttig het ook is om discussie soms te overdrijven, of juist iets zwarter/witter neer te zetten, komt dat wel disclaimers en toelichting. (Alhoewel het best leuk kan zijn voor de discussie, om te simplificeren)
10 afbeeldingen van een appel.
9 keer zegt het systeem "ja, het is een appel", en 1 keer "nee, het is geen appel".
Dat is 90% maar een compleet ander resultaat dan 9 keer een antwoord "het is een appel", en 1 keer "het is een ballon".
En dan heb je nog de test van 1000 afbeeldingen waarvan er 10 een appel zijn.
Het systeem vindt 9 van de 10 appels, dus 90% gevonden. Maar zoals je zegt, de false positives, hoeveel andere afbeeldingen waren geselecteerd als appel. Misschien werden er wel 900 afbeeldingen als appel geselecteerd.
Of was het 1 afbeelding waarvan het systeem 90% overtuigd was dat het een appel was, 60% een ballon, etc.
Het is essentieel om te weten wat de test set was, elke toets uitgevoerd was, en wat de goede en foute antwoorden waren.
Leuke bijdrage. Zo grap ik vaak tegen vrienden dat ik nog nooit een Wimbledon-finale heb verloren. Of dat ik een test heb ontworpen die 100% nauwkeurig (geen false negatives) kan bepalen of je een bepaalde ziekte hebt; iedereen test positief.
Vooral in de medische wereld (maar eigenlijk overal) moet je heel voorzichtig zijn met cijfers en statistiek en goed nadenken wat je nou eigenlijk zegt.
Voor meer gekkigheid over biases en statistiek raad ik de boeken van Nassim Nicholas Taleb aan, of het boek “Thinking fast or slow” van Daniel Kahneman.
Je hebt daar in het algemeen gelijk in, maar die retina-scans in combinatie met patroonherkenning kan dus daarin dingen echt zien die wij als mens niet hebben ontdekt. Dat is robuust, redelijk goed begrepen en waar (dit zijn geen ondoorgrondelijke extreem grote modellen maar gewoon simpele computervisie). Het lost dus een echt medisch probleem op.
Het is zo dat er heel veel machine learning papers met medische toepassingen worden gepubliceerd die uiteindelijk allemaal nutteloos blijken omdat de studies niet goed zijn opgezet en/of er gewoon niets extra’s in de data te vinden was. Maarten van Smeden van het UMC is een leuke bron op Twitter om te volgen hierover.
Klopt, maar AI is eenmaal de misbruikte term voor LLM tegenwoordig😊
AI is natuurlijk geen afgekaderde definitie. De een gebruikt het voor LLM (Zoals ChatGPT), de ander voor een paar scriptjes die keuzes maken op basis van sleutelwoorden (zoals Apple Siri), weer een ander voor Machine Learning, weer een ander houdt de sci-fi definitie aan, dus dat er een zekere mate van ‘(zelf)bewustzijn’ moet zijn.
Het is eigenlijk net zoals de term ‘smart’, wat in dagelijkse taal betekend “doet iets op het internet” en/of “heeft een app”, waar smart nog veel meer kan betekenen. Bijvoorveeld: “Slim of Goed doordacht”
Ergens kan je wel stellen dat de LLMs de term een beetje gekaapt hebben en dat het in de media heel moeilijk is om meer specifieke termen geintroduceerd te krijgen zoals generatieve kunstmatige intelligentie wat de lading wat mij betreft dan weer beter dekt dan gewoon een LLM daar de huidige hype ook afbeeldingen en zelfs filmpjes kan genereren.
Wetenschappelijke conferenties hanteren wel een definitie om hun scope te bepalen. Onder AI vallen systemen die redeneren (middels logica en/of probabiliteit) en/of leren, plus nieuwe en impactvolle toepassingen daarvan. Chatbots zijn een (uitdagende) toepassing van AI technieken.
Hoewel ik het volledig met je eens ben is taal een voortdurend evoluerend proces, en is de term AI inmiddels onlosmakelijk verbonden met LLMs. Wat we vroeger AI noemden is nu AGI (G staat voor General) en hoewel LLMs zeker een plek hebben in de implementatie van AGI, is het slechts 1 component, en geen complete oplossing. Dit in tegenstelling tot wat men ons probeert wijs te maken.
Precies dit! AI voor nuttige zaken als herkenning van kanker geloof ik in. Maar al die overhyped LLM gimmicks onder de noemer "AI", ik word er af en toe een beetje moe van. Copilot van MS bijvoorbeeld: plaatjes genereren in Paint, automatische ondertitels bij filmpjes, een log van alle activiteiten doorzoeken, who cares?
Wat ik me al lezend wel afvroeg is hoe dit zich verhoudt tot inspanningen elders, dus buiten de VS? En dan natuurlijk vooral die van de paar grote bedrijven in China, wat de rest van de wereld, en zeker de EU, doet er op dit gebied niet toe (misschien Japan, Korea en straks India nog iets voor hun lokale markt?). En dan dus ook in welke mate Chinese bedrijven hinder hebben van de export restricties op ICs en IC-technologie.
Om eerlijk te zijn vind ik dit helemaal geen interessant artikel. Er staat veel maar het zegt bijzonder weinig over wat de bedrijven er nu echt mee doen. Tot nu toe heb ik ook alleen maar halfbakken implementaties gezien die weinig tot geen meerwaarde bieden ten opzichte van wat het kost. Het enige dat ik merk van AI is dat het halve internet is vern**kt door SEO scumming en dat klanten over elkaar struikelen om ons Copilot te laten implementeren. Als er dan gevraagd wordt wat men er nu eigenlijk mee kan, dan komen er allemaal lulverhalen over het optimaliseren van processen en dat je je halve support organisatie de deur uit kunt sturen omdat AI het beter kan. De enige meerwaarde die ik zelf zie is dat het vrij goed is in het condenseren van management bullshit en dat als het een beetje vlotter gaat werken uiteindelijk je dataclassificatie nauwkeuriger wordt (voor governance)
Men doet alsof 'AI' het antwoord is op alle problemen, maar het is in essentie een geavanceerd woordenboek. Het zal een plek hebben in de moderne wereld, en is een sprong vooruit, maar we lopen hard tegen de limieten aan en binnenkort is de hype voorbij.
De enige meerwaarde die ik zelf zie is dat het vrij goed is in het condenseren van management bullshit
Dat zou grappig zijn: de hoge manager gebruikt ChatGPT om een 1 of 2 korte nieuwtjes op te blazen naar een complete mail van 500 woorden, en de medewerkers gebruiken ChatGPT om het weer te reduceren tot die 1 of 2 korte nieuwtjes
Het geldt ook voor alles wat je leest op internet. Veel nieuwsberichten worden (mede) gegenereerd door generatieve tools. Het lezen ervan wordt ook makkelijker met dergelijke tools, als deze daar beter in worden.
Niet alleen nieuwsberichten, als je iets zoekt in een zoekmachine dan zijn de top 20 websites vaak 'antwoord op je vraag' en als je dan klikt krijg je 800 pagina's gegenereerde onzin over de historie en toepassingen van hetgeen waar je naar op zoek bent, daartussen staat ergens een half antwoord wat een copy paste is van 200 andere websites die precies hetzelfde doen. Weet je nog toen we nog wel nuttige informatie konden vinden? Pepperidge farm remembers..
Er staat veel maar het zegt bijzonder weinig over wat de bedrijven er nu echt mee doen
Helaas ben ik dat met je eens. Het is een klein overzicht van welke bedrijven op welke manieren hun LLMs kunnen inzetten en trainen, met heel veel vulling. Toen ik de titel zag hoopte ik op een mooi stukje diepgang bij de zondagsochtendkoffie, maar dat zat er eigenlijk niet in. Ook het weglaten van Amazon is een groot gemis wat mij betreft, ze mogen dan niet veel consumentendiensten in Nederland hebben, met AWS zijn ze wel de grootste cloud provider en kunnen ze een sleutelrol spelen voor andere bedrijven die AI willen inzetten.
Tevens wordt er totaal niet uitgelegd hoe er precies getraind wordt, wat de toekomstplannen zijn en wat de exacte huidige staat is van de LLMs en andere technieken per aanbieder. Een zijspoor naar gebruik van AI anders dan LLMs of plaatjesmakers had ik ook gewaardeerd.
Het artikel suggereert dat MS goed heeft gegokt met de investeringen in OpenAi, maar is dat niet te vroeg om nu te zeggen? Ik heb bing de eerste paar keer gebruikt, maar daarna nooit meer de behoefte gevoeld.
Eerste reviews zoals die van LTT over de nieuwe qualcomm windows ai laptops zijn ook niet erg enthousiast. De grootste beweging is momenteel op de beurs te zien, waar iedereen net zoals bij blockchain en crypto over elkaar heen duikelt om er iets mee te doen en die koersen dan ook hard stijgen.
Ik ben benieuwd naar de echt vernieuwende toepassing met AI die van toegevoegde waarde gaat zijn voor ons. Iets dat ons leven verrijkt en ons zelf niet alleen dommer en/of luier maakt of gebruikt wordt om de boel te flessen.
Wanneer je naar de reviews kijkt van Qualcomm gebasseerde systemen dan zijn de resultaten over het algemeen gematigd positief, maar met een zeer belangrijke voetnoot. Het is voor de meeste mensen te vroeg om over te stappen omdat vele software nog niet klaar is voor het platform. Maar als je relatief lichte taken en gewoon kantoorwerk doet, dan heb je met die laptops een winnaar in huis, zeker wat betreft batterijduur.
AI staat uiteindelijk los van die SoC, en we zullen later dit jaar of volgend jaar ook gewoon Copilot+ PCs zien met een Intel of AMD chip.
En ja, als we eenmaal over die piek heen zijn die vandaag bezig is geloof ik wel dat systemen zoals Copilot een vaste plaats gaan krijgen in ons leven, net zoals de vorige generatie dat ook gedaan heeft met Siri en Google Assistent.
Weet je of er plannen zijn bij CPU/GPU bouwers om NPU/Tensor cores in de TEE in te bouwen?
Bij drijven in de medische sector in Duitsland hebben steeds vaker de focus op TEE compute. Gelukkig ondersteunen alle gangbare ARM en Intel/AMD processoren dit al een jaar of 10, en kun je bij de grote cloud providers (AWS, Azure en GPC) hier zonder extra kosten gebruik van maken op de computer instances.
[Reactie gewijzigd door djwice op 23 juli 2024 00:41]
Google publiceerd haar modellen ook, alleen sommige zijn zo groot dat ze alleen op data center GPU's geladen kunnen worden i.v.m. de VRAM die nodig is.
Ook de tools zijn open https://ai.google.dev/gemma
Broncode publiceren is niet hetzelfde als onderzoek publiceren. Met broncode heb je een eindproduct in handen zonder dat je begrijpt waarom het gebouwd is op de manier waarop het gebouwd is. Waarom bepaalde keuzes zijn gemaakt en wat men allemaal heeft meegenomen om tot die keuze te komen.
AI is voorlopig een Gimmick. Veel grote corporaties zetten erop in omdat ze niet 2x de boot willen missen zoals velen het met internet gedaan hebben maar of er nou een boot te missen valt is nog niet te zien.
Veel zaken die door AI worden gedaan hebben een grote error tolerance of worden vaak na gecontroleerd door professionals (mensen).
Dat wil niet zeggen dat er geen nuttige productieve toepassingen zijn nu. Neem bijvoorbeeld de huidkanker scanners. Die kunnen visueel (zonder voelen) al veel beter huidkanker eruit halen dan dermatologen. Maar meeste AI is nu meer belofte dan meetbare winst.
De meesten likkebaarden vooral bij de gedachten medewerkers de laan uit te kunnen sturen. De droom van iedere CEO: Een bedrijf wat bestaat uit jaknikkende managers aangevuld met AI.
De ironie is dat het bij ons vooral de vervangbare managers zijn die nu op de hype springen. Dus mogelijk komt er toch nog wat goeds van.
@arnoudwokke Google heeft niet alleen datacenters in Nederland, maar ook in België. In St. Ghislain is er een campus met 5 datacenters en ze zijn er nog 1 aan het bijbouwen in Farciennes.
Ook Microsoft heeft ondertussen een belgium-central region, wat verspreid zou zitten over 3 datacenters in België.
[Reactie gewijzigd door Mortis__Rigor op 23 juli 2024 00:41]
Het is duidelijk dat bedrijven al een tijdje doorhebben dat AI een abonnement gedreven dienst ondersteunt.
In veel gevallen is het niet mogelijk om dergelijke diensten lokaal te draaien omwille van de enorme rekenkracht die nodig is of het closed source karakter ervan.
Nu zal het allemaal wel nog even gratis zijn, tot op het punt dat de technologie volwassen genoeg is.
Vanaf dat moment zal je als gebruiker toch echt moeten gaan betalen voor zaken als ChatGPT of andere diensten.
Apple zie ik het nog wel “gratis” aanbieden, maar alleen zolang je binnen hún ecosysteem blijft opereren.
Microsoft wil duidelijk waarde toevoegen aan hun O365 suite om de abo kostprijs te kunnen blijven verantwoorden.
Begrijp me niet verkeerd, AI heeft een geweldige toekomst, maar vooral de dienstverleners zullen er beter van worden.
Open source modellen zullen zwaar achterop hinken omwille van kleinere datasets en/of beperktere rekenkracht.

:strip_exif()/i/2001515511.jpeg?f=imagenormal)

:strip_exif()/i/2006406436.jpeg?f=imagegallery)
:strip_exif()/i/2004498016.jpeg?f=imagegallery)
:strip_exif()/i/2006786310.jpeg?f=imagenormal)
:strip_exif()/i/2006680970.jpeg?f=imagegallery)
:strip_exif()/i/2006802526.jpeg?f=imagegallery)
:strip_exif()/i/2007860918.jpeg?f=fpa)
/i/2005490828.png?f=fpa)
/i/2006258942.png?f=fpa)
:strip_icc():strip_exif()/u/147791/crop56e423ed8d794_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/58227/crop6626a7982351d_cropped.jpg?f=community)
/u/99142/crop62758e978b3e3_cropped.png?f=community)
/u/176086/crop5f0823fa5e8d6_cropped.png?f=community)
:strip_icc():strip_exif()/u/78725/train-icon3.jpg?f=community)
:strip_icc():strip_exif()/u/125182/crop5f773b38ac426_cropped.jpeg?f=community)
/u/62799/crop589e049deeb18_cropped.png?f=community)
/u/1957000/crop696cfa35c73d9_cropped.png?f=community)
:strip_icc():strip_exif()/u/109036/crop580efea56f6f9_cropped.jpeg?f=community)
/u/12436/p1_normal.png?f=community)
/u/236860/crop6936cd41d5b8c.png?f=community)