Het leverde nogal wat media-aandacht en ophef op: de oud-hoofdredacteur van NRC gebruikte verzonnen citaten die hem door een AI-chatbot werden aangereikt. Nogal een journalistieke canard, maar dat journalisten AI inzetten is dan weer niet heel gek. Het is een goed moment om eens te beschrijven hoe we bij Tweakers omgaan met AI.
Peter Vandermeersch heeft het verpest. De oud-hoofdredacteur gebruikte 53 keer een citaat in een artikel dat door een AI-chatbot bleek te zijn gehallucineerd. Niet fraai, zeker niet voor iemand met zo'n prestigieuze positie. Om te beginnen is het goed te weten wie Vandermeersch is en wat zijn rol bij de uitgever was, en hoe zich dat verhoudt tot DPG Media, waar Tweakers onder valt.
Vandermeersch was tussen 2010 en 2019 hoofdredacteur van NRC (toen nog formeel NRC Handelsblad), werd later ceo van Mediahuis Ierland, maar is nu een 'Fellow Journalism & Society' bij Mediahuis in de Benelux. Dat is een wat vage term die bij uitgevers niet heel gangbaar is; bij DPG bestaat zo'n titel bijvoorbeeld niet.
Onderzoeker
Als 'fellow' onderzoekt Vandermeersch nieuwe vormen van journalistiek, maar ook hoe journalistiek zich ontwikkelt binnen maatschappelijke stromingen en problemen. Denk daarbij aan wantrouwen richting de pers, afhankelijkheid van techbedrijven, en uiteraard ook kunstmatige intelligentie. Daarover schrijft hij blogs en nieuwsbrieven. Je kunt zijn functie dus een beetje zien als een hoogleraar aan een universiteit, maar dan binnen een journalistieke uitgever.
Dat laatste raakt aan deze blog. Want ook journalisten, ook wij, experimenteren met AI. Net zoals ontwikkelaars dat nu doen, of artsen, of bouwvakkers, of salarisadministrateurs, of zorgwerknemers, of eigenlijk iedere werkzame persoon.
:strip_exif()/i/2007988330.jpeg?f=imagenormal)
Cursussen en inspiratie
Ook binnen DPG wordt daarmee geëxperimenteerd. Normaal gesproken proberen we ver weg te blijven van wat er binnen onze uitgever gebeurt, want in de praktijk heeft die weinig invloed op ons redactionele werk. Maar nu is het wel enigszins relevant, want we leren wel van elkaar, ook van conculega's elders in het bedrijf.
Een 'fellow' zoals Peter Vandermeersch dat is, bestaat niet bij DPG. Maar er zijn wel degelijk overkoepelende afdelingen die bezig zijn met journalistieke vernieuwingen en dus ook AI. Zo is er de Campus, waar journalisten van DPG en dus ook Tweakers cursussen kunnen volgen. Soms gaan die over klassieke journalistieke onderwerpen zoals hoe je een goede titel maakt of een column schrijft, maar zeker in de afgelopen jaren zijn er steeds meer cursussen ontstaan rondom AI. Zo zijn er cursussen AI gebruiken in Photoshop, AI voor data-analyses, AI voor advertenties en ga zo maar door.
Die zijn soms voor ons relevant. De afbeeldingen boven onze nieuwsartikelen kunnen bijvoorbeeld met AI worden verbeterd. En als we artikelen schrijven op basis van Pricewatch-data, kan het nuttig zijn daar AI-analyses op los te laten.
Inspiratie, geen verplichting
Ook krijgen we regelmatig interne nieuwsbrieven waarin AI-experimenten van andere titels worden beschreven. Die kunnen voor ons dienen als inspiratie.
Dat betekent allemaal niet dat AI ons wordt opgelegd. Alle bovenstaande voorbeelden zijn optioneel, bedoeld om ons te inspireren of te helpen deze grote economische, maatschappelijke en sociale ontwikkeling te begrijpen en in te zetten in ons werk. Dat is niet gek. AI gaat namelijk onvermijdelijk invloed hebben op, heel plat, ons verdienmodel en daarmee ook ons (journalistieke) werk. Dat negeren zou dom zijn. Denk je maar eens in: waar onze Pricewatch nu een heel waardevolle bron van informatie is, is het voor potentiële kopers misschien wel heel handig om aan ChatGPT te vragen wat bijvoorbeeld de beste nas is. Daar moeten we op de lange termijn op voorbereid zijn.
Artikelen laten schrijven? Nee, liever niet
Maar de grote vraag is natuurlijk: gebruiken we AI ook voor het schrijven van artikelen? Nee, in de basis niet – ondanks wat sommige lezers ons regelmatig verwijten.
Journalistiek en AI staan op gespannen voet met elkaar. Het werk van een journalist is namelijk dingen uitzoeken en zo correct mogelijk opschrijven. Dat is de hele raison d'être van de journalist, dat is waarom we het vak in zijn gegaan. Een AI doet precies het tegenovergestelde: het speculeert en voorspelt wat ongeveer het logische vervolg in een tekst is. Speculatie en aannames dus, de exacte tegenpolen van wat journalisten doen. Veel journalisten kijken daarom wat neerbuigend naar AI: waarom zou je een tool gebruiken die erom bekendstaat het tegenovergestelde te doen van jouw werk?
Tweakers heeft in het redactiestatuut niets staan over AI-gebruik in redactionele teksten
Veel media hebben inmiddels clausules opgenomen over het gebruik van AI in hun redactionele stijlboeken of redactiestatuten. Wij hebben dat nog niet. Ons redactiestatuut bevat daar geen informatie over en we hebben onderling geen harde regels afgesproken voor AI-gebruik.
Het belangrijkste deel van ons werk waar we AI inzetten én waar dat ook aantoonbaar extreem nuttig is, is eindredactie. Al onze teksten gaan eerst door ChatDPG heen. Dat is geen typfout (kan ook niet, want ook deze tekst is gecontroleerd!): ChatDPG is een afgesloten omgeving die volledig op DPG-servers draait en waarbij input dus niet gebruikt wordt voor het trainen van andere AI-modellen. De tool is vernoemd naar ChatGPT, bij de release het enige taalmodel dat werd ondersteund, maar inmiddels gebruiken we ook andere llm's zoals Gemini.
De eindredacteuren schaven constant aan de prompt, die wordt gevoed met onze stijlgids en schrijfwijzers. Zo kan ChatDPG voorafgaand aan publicatie d/t-fouten uit artikelen vissen, maar ook de manier waarop we termen als HTTP en Https schrijven (vier hoofdletters, maar één hoofdletter als de afkorting vijf letters is). Dit is ontzettend handig. Het aantal meldingen dat we krijgen in ons topic voor spel- en tikfoutjes is drastisch gekelderd sinds we dit inzetten. Dat betekent dat onze eindredacteuren zich vooral kunnen richten op het verfijnen van de eerdergenoemde stijlgids, het mooier maken van zinnen en het leesbaarder maken van teksten.
AI-ndredactie
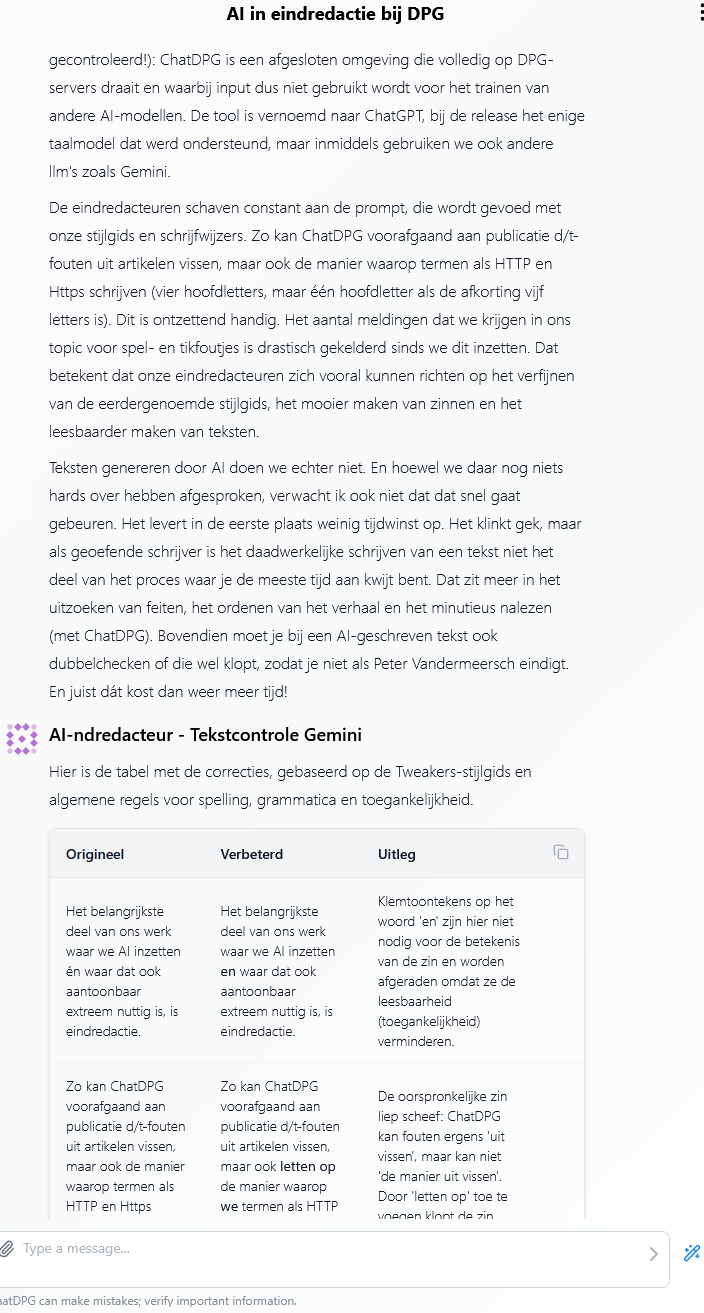 Teksten genereren door AI doen we echter niet. En hoewel we daar nog niets hards over hebben afgesproken, verwacht ik ook niet dat dat snel gaat gebeuren. Het levert in de eerste plaats weinig tijdwinst op. Het klinkt gek, maar als geoefende schrijver is het daadwerkelijke schrijven van een tekst niet het deel van het proces waar je de meeste tijd aan kwijt bent. Dat zit meer in het uitzoeken van feiten, het ordenen van het verhaal en het minutieus nalezen (met ChatDPG). Bovendien moet je bij een AI-geschreven tekst ook dubbelchecken of die wel klopt, zodat je niet als Peter Vandermeersch eindigt. En juist dát kost dan weer meer tijd!
Teksten genereren door AI doen we echter niet. En hoewel we daar nog niets hards over hebben afgesproken, verwacht ik ook niet dat dat snel gaat gebeuren. Het levert in de eerste plaats weinig tijdwinst op. Het klinkt gek, maar als geoefende schrijver is het daadwerkelijke schrijven van een tekst niet het deel van het proces waar je de meeste tijd aan kwijt bent. Dat zit meer in het uitzoeken van feiten, het ordenen van het verhaal en het minutieus nalezen (met ChatDPG). Bovendien moet je bij een AI-geschreven tekst ook dubbelchecken of die wel klopt, zodat je niet als Peter Vandermeersch eindigt. En juist dát kost dan weer meer tijd!
We gebruiken AI uiteraard wel voor onderzoek. Dat doen we op dezelfde manier als dat we Google gebruiken, of Wikipedia. Het is een bron van informatie die je vervolgens altijd moet verifiëren bij de originele bron. Een snelle vraag stellen aan ChatGPT of Claude is voor journalisten vaak hetzelfde als iets opzoeken op Google.
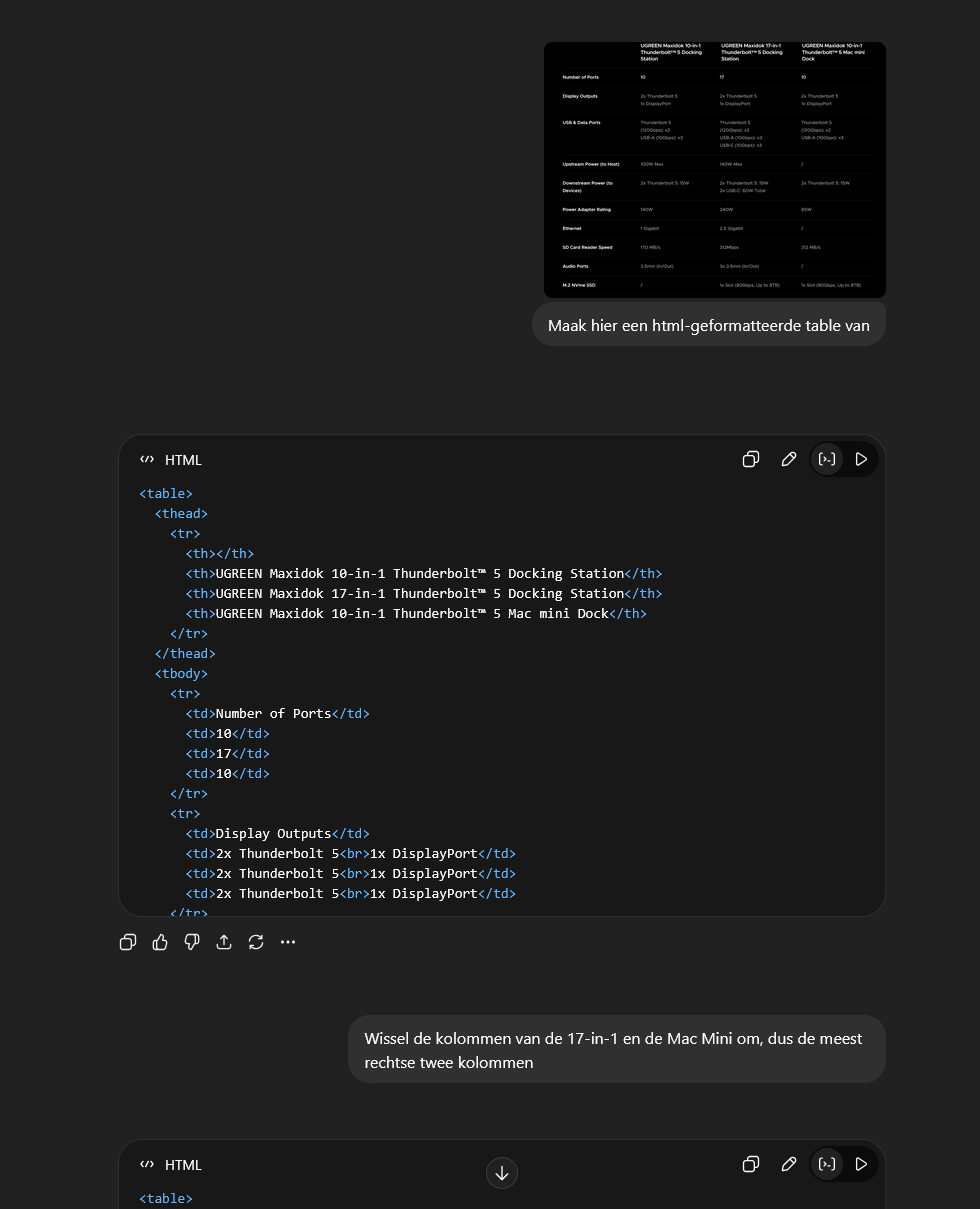
We zetten llm's verder ook wel eens in om specsheets of tabellen te maken. Dat kost vaak veel tijd (en is oersaai!), want je moet informatie van een pdf overtypen naar een tabel. Een screenshot uploaden en vragen daar een HTML-geformatteerde tabel van te maken, scheelt heel veel werk. We werken aan een prompt die ook Engelse termen zoals 'Battery' of 'Screen' automatisch vertaalt naar onze voorkeursvormen, Accu en Scherm, maar dat gaat nog veel mis en kost nog wat handwerk. Desondanks kan dit veel werk schelen. In de praktijk controleren we vaak wel of de tabel overeenkomt met de pdf, maar (en n is hier 1) dat gaat inmiddels heel vaak goed.
AI-gegenereerde teksten zul je in redactionele artikelen voorlopig dus niet tegenkomen. AI-gecontroleerde teksten wel, waaronder deze. Uiteindelijk is het antwoord dus best saai: we experimenteren met AI, maar het is niet zo alsof het al ons werk nu langzaam overneemt.
Maar laat me dit artikel over 5 jaar nog eens teruglezen...

/i/2007887364.png?f=fpa)
/i/2008058738.png?f=fpa)
/i/2008097178.webp?f=fpa)
:strip_exif()/i/2004648158.jpeg?f=fpa)
:strip_exif()/i/1333529431.gif?f=fpa)
/i/2007970208.png?f=fpa)
:strip_exif()/i/2007890706.jpeg?f=fpa)
:strip_exif()/i/2004673252.jpeg?f=fpa)
:strip_exif()/i/2007721774.jpeg?f=fpa)
/i/2007700920.png?f=fpa)
:strip_exif()/i/2005701904.jpeg?f=fpa)
:strip_icc():strip_exif()/u/448966/crop62a741840cd69_cropped.jpg?f=community)
:strip_icc():strip_exif()/u/269918/Cerberus60x60.jpg?f=community)
/u/176086/crop5f0823fa5e8d6_cropped.png?f=community)
:strip_icc():strip_exif()/u/270072/crop600be8fca1d4a.jpeg?f=community)
/u/1906/crop5dfd46928e003.png?f=community)
/u/155722/Looneytunes.png?f=community)
/u/325014/Inter3-play.png?f=community)
:strip_exif()/u/295799/cryava.gif?f=community)
/u/201305/Pig.png?f=community)
/u/12436/p1_normal.png?f=community)
:strip_icc():strip_exif()/u/383827/Untitled-2.jpg?f=community)
/u/1435570/crop672c9fd299184_cropped.png?f=community)
/u/217510/crop660db19c1cf7b_cropped.png?f=community)
/u/644186/froz0.png?f=community)