Meta heeft de derde generatie van zijn Llama-AI-model voorgesteld. De huidige versies hebben 8 miljard en 70 miljard parameters, later zal nog een groter model volgen met 400 miljard parameters. Die is nog met training bezig.
De dataset voor training van Llama 3 is zeven keer zo groot als bij Llama 2 van vorig jaar, claimt Meta. Er zit vier keer zoveel code in de data. Daarnaast is de tokenizer om taal te coderen veel efficiënter, wat moet leiden tot betere prestaties. Ook gebruikt Meta iets dat 'grouped query attention' om de efficiëntie te verbeteren.
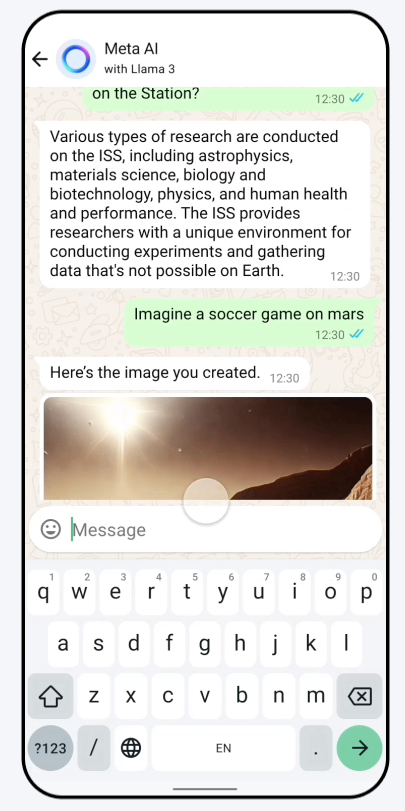
Tussen de trainingsdata is 95 procent in het Engels en dat leidt tot verminderde prestaties in de dertig andere talen die Meta AI ondersteunt. Llama 3 komt vanaf nu onder meer in diensten als WhatsApp en Instagram, zo claimt het bedrijf. Dat gebeurt in de vorm van een AI-assistent. Dat gebeurt vooralsnog alleen in het Engels, in de Verenigde Staten, Australië, Canada, Ghana, Jamaica, Malawi, Nieuw-Zeeland, Nigeria, Pakistan, Singapore, Zuid-Afrika, Oeganda, Zambia en Zimbabwe.

:strip_exif()/i/2007292382.jpeg?f=fpa)
:strip_exif()/i/2004743102.jpeg?f=fpa)
/i/2004608956.png?f=fpa)
/i/2005182236.png?f=fpa)
/i/1243859159.png?f=fpa)
:strip_exif()/i/2004743100.jpeg?f=fpa)
/u/298866/crop5ef045407bab9_cropped.png?f=community)
:strip_icc():strip_exif()/u/149541/crop619ca134be210_cropped.jpg?f=community)
/u/88794/dj_henk4b.png?f=community)
:strip_icc():strip_exif()/u/754479/crop668e454bcff2e_cropped.jpg?f=community)
/u/325014/Inter3-play.png?f=community)
/u/1785734/crop6447a2e290e74_cropped.png?f=community)
:strip_icc():strip_exif()/u/230241/crop5db74093e7dc1_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/126804/crop60008216c7eb0_cropped.jpeg?f=community)
/u/95528/crop5af15e0d92966_cropped.png?f=community)
/u/208006/Zagor%2520small.JPG?f=community)
/u/45967/android-1.png?f=community)
/u/423200/crop5654dd6c439b0_cropped.png?f=community)
:strip_icc():strip_exif()/u/227665/th_petey_rawrs.jpg?f=community)
/u/12436/p1_normal.png?f=community)
:strip_exif()/u/211274/bestabstractwallpapers5.gif?f=community)
:strip_exif()/u/79817/muziek.gif?f=community)
/u/207598/radioheadbear.png?f=community)
{kind=link}
{kind=link}