Internetknooppunt AMS-IX heeft een storing en handelt een kwart van het normale verkeer op het tijdstip af. Er lijken verder geen grote problemen te ontstaan.
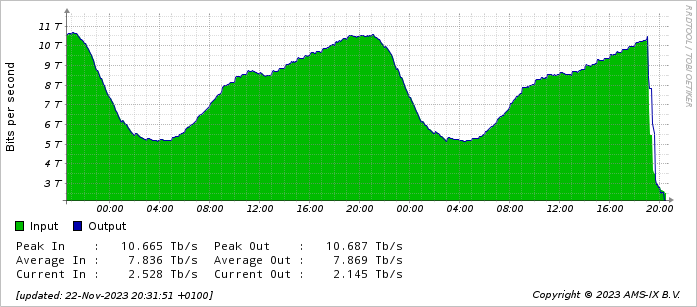
De storing is volgens informatie uit de mailinglijst ontstaan om 19.08u. De terugval in verkeer is duidelijk te zien in de openbare stats van het internetknooppunt. Waar rond dat tijdstip verkeer van rond 10Tbit/s normaal is, gaat het nu om 2,5Tbit/s. De grafiek begint niet bij 0, waardoor het in de stats lijkt of er geen verkeer over het knooppunt meer gaat, maar dat is dus onjuist.
Sommige klanten hebben een korte dip waargenomen, zo meldt AMS-IX. "We zijn nu bezig met het verzamelen van gegevens voor het oplossen van problemen om onze leverancier te helpen de hoofdoorzaak zo snel mogelijk te achterhalen."
Update, donderdag: De storing was woensdagavond rond elf uur opgelost.

:strip_exif()/i/2005501064.jpeg?f=fpa)
/i/2005034312.png?f=fpa)
/i/2006340568.png?f=fpa)
/u/62384/crop61891f444d6e9.png?f=community)
:strip_icc():strip_exif()/u/745575/crop5de1181b59fc4_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/580143/crop57d5827ebf8db_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/125182/crop5f773b38ac426_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/52072/crop5de51ebf91960_cropped.jpeg?f=community)
/u/3626/front-kabels.png?f=community)
/u/97978/crop60f5315bd7679_cropped.png?f=community)
:strip_icc():strip_exif()/u/521319/crop68bfc0d4c3484_cropped.jpg?f=community)
/u/298866/crop5ef045407bab9_cropped.png?f=community)
:strip_icc():strip_exif()/u/177406/crop5ca60c3b4a6c7_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/6764/cergorach.jpg?f=community)
:strip_icc():strip_exif()/u/457808/crop5686a95ab9c87_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/465740/wouterr.jpg?f=community)
:strip_icc():strip_exif()/u/464195/crop6304979c1a471_cropped.jpg?f=community)
/u/705840/crop566018173f5b4_cropped.png?f=community)
:strip_icc():strip_exif()/u/399334/crop5a6e1999e99b3_cropped.jpeg?f=community)
:fill(white):strip_exif()/f/image/OHkCT3DlaVeoF627BgoTTtlm.png?f=user_large){kind=link}