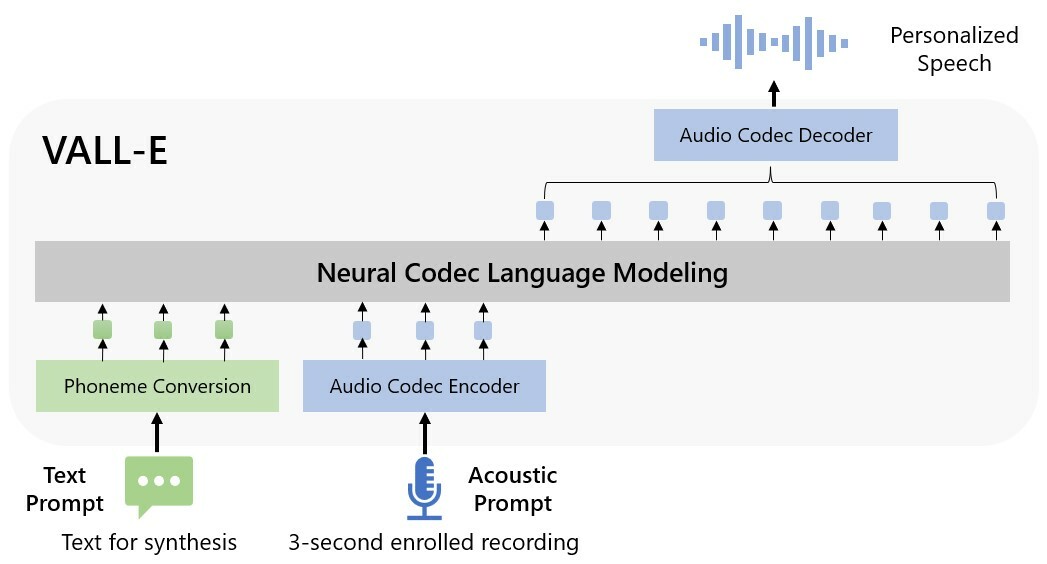
Microsoft toont een nieuw AI-model, genaamd Vall-E. Dit text-to-speechmodel kan volgens de techgigant gesproken zinnen in vrijwel ieder stemgeluid genereren na een sample van drie seconden gehoord te hebben. Het AI-model kan daarbij ook intonatie en emotie nabootsen.
Vall-E maakt gebruik van een taalmodel en is getraind met 60.000 uur aan Engelstalige spraakopnames, schrijven onderzoekers in een researchpaper. De tool kan volgens de makers een stemgeluid nadoen na een sample van drie seconden gehoord te hebben. Daarmee kan de tool vervolgens via een geschreven prompt audioclips produceren met de stem uit de input.
Het Vall-E-model is uitgeprobeerd door studenten van Cornell University, die een website met verschillende demo's publiceerden. Op deze webpagina zijn verschillende echte spraakopnames te horen, die zijn gebruikt als sample voor Vall-E. Bij iedere sample worden een of meer synthetische spraakopname gepubliceerd die door Vall-E zijn gegenereerd. De kwaliteit daarvan varieert; enkele opnames klinken overtuigend, terwijl bij andere opnames duidelijk is te horen dat deze door software zijn gegenereerd.
Onderzoekers stellen dat Vall-E in veel gevallen beter presteert dan huidige text-to-speech-modellen. De onderzoekers schrijven echter ook dat het AI-model op dit moment nog verschillende problemen heeft. Het kan bijvoorbeeld gebeuren dat bepaalde woorden uit het tekstprompt onduidelijk worden uitgesproken, volledig worden gemist of juist dubbel voorkomen in de output. Daarbij heeft het model momenteel nog moeite met het nadoen van bepaalde stemmen, vooral stemmen met een accent.
Dergelijke AI-modellen zijn verder omstreden, aangezien ze ook gebruikt kunnen worden om zonder toestemming iemands stemgeluid te imiteren. De onderzoekers erkennen in hun researchpaper dat het AI-model misbruikt kan worden. Ze stellen dat het mogelijk is om een detectiemodel te ontwikkelen dat kan herkennen of een geluidsfragment door Vall-E is gegenereerd.
Op dit moment is Vall-E nog niet openbaar beschikbaar. Microsoft heeft wel een Vall-E-repository op GitHub gezet, maar deze bevat momenteel alleen nog een beperkt readme-bestand. De techgigant zegt niet of en wanneer het tts-model breed beschikbaar komt.

:strip_exif()/i/2005547492.jpeg?f=fpa)
/i/2004765172.png?f=fpa)
:strip_exif()/i/2005559674.jpeg?f=fpa)
/i/2005490828.png?f=fpa)
:strip_exif()/i/2005477456.jpeg?f=fpa)
/i/2002509398.png?f=fpa)
:strip_exif()/i/2004816210.jpeg?f=fpa)
/i/1277037256.png?f=fpa)
:strip_exif()/u/1820/GoTicon.gif?f=community)
:strip_icc():strip_exif()/u/109144/IMG_2440.jpg?f=community)
:strip_icc():strip_exif()/u/140051/BSOD.jpg?f=community)
/u/107495/godzilla%252060x60.png?f=community)
/u/46032/74daijirox.GIF?f=community)
/u/47542/crop5835c0be871d0_cropped.png?f=community)
/u/1658128/crop617e9f5e512d6_cropped.png?f=community)
/u/143137/crop5d1c4f96268ca_cropped.png?f=community)
:strip_icc():strip_exif()/u/136442/crop6198f3130240d.jpg?f=community)
/u/349199/crop69f59caff1e30_cropped.png?f=community)
:strip_icc():strip_exif()/u/242946/toby2.jpg?f=community)
:strip_icc():strip_exif()/u/142393/crop672b6f0083761_cropped.jpg?f=community)
/u/1190644/crop5ca933f2c3575_cropped.png?f=community)
:strip_icc():strip_exif()/u/109773/ziltoid_fetid_70px.jpg?f=community)
:strip_icc():strip_exif()/u/401890/crop5697cd5801ab5_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/6764/cergorach.jpg?f=community)
/u/58518/crop55c9fb6f4244f_cropped.png?f=community)
/u/217510/crop660db19c1cf7b_cropped.png?f=community)
:strip_icc():strip_exif()/u/112202/lighthouse.jpg?f=community)
/u/1889266/crop64446ab4df1e2_cropped.png?f=community)
/u/357567/crop5dfcfaa04d0e8_cropped.png?f=community)
:strip_exif()/u/865/bj.gif?f=community)
/u/94596/crop643fb12fd4e6d.png?f=community)
/u/313319/crop59206934ce8e7_cropped.png?f=community)
:strip_exif()/u/69029/crop5cac7b8ae8078.gif?f=community)
:strip_exif()/u/23142/got.gif?f=community)
:strip_icc():strip_exif()/u/35296/crop58ee1af0aa1db.jpeg?f=community)
:strip_icc():strip_exif()/u/8379/crop568422c027ddc_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/92809/crop577f58c1b8795.jpeg?f=community)
:strip_icc():strip_exif()/u/39182/crop5ed2c334175a2_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/142317/crop5cbd9d51d7e14_cropped.jpeg?f=community)