Google heeft een nieuwe stap gezet met het deeplearningalgoritme van DeepMind. Een nieuwe variant daarvan genaamd MuZero kan niet alleen spellen leren door deze veel te spelen, maar ook zonder de regels vooraf te kennen. MuZero kan zelfs visuele spellen spelen.
MuZero is een nieuwe AI van Googles machinelearningalgoritme die door dochterbedrijf DeepMind is gemaakt. Het algoritme is een spirituele opvolger van AlphaGo en AlphaZero, dat spellen als Go en schaken leerde en daarmee wereldkampioenen versloeg. MuZero kan schaken en Go leren, maar ook complexere visuele spellen van Atari. Google zegt bovendien dat MuZero de regels van het spel zelf kan leren door bepaalde strategieën te proberen.
Volgens Googles wetenschappers maakt MuZero gebruik van een model based planning-model, in tegenstelling tot een lookahead search. Bij dat laatste neemt een AI een beslissing op basis van mogelijke uitkomsten van beslissingen, en dat is het model waar ook AlphaGo en AlphaZero gebruik van maken. Algoritmes op basis van dergelijke beslissingsbomen werken volgens de onderzoekers vooral goed op basis van voorgesorteerde modellen met gedefinieerde regels. Spellen zoals schaak en Go hebben zulke regels en daarom zijn AlphaGo en AlphaZero er zo goed in. Daarvoor moet het algoritme dus wel vooraf trainingdata over het op te lossen probleem hebben gekregen.
/i/2004080234.png?f=imagenormal)
In de 'echte wereld' hebben problemen volgens de onderzoekers niet zulke gedefinieerde regels. Daarom maakt MuZero gebruik van model based planning, maar wel op een eigen, beperkte manier. Daarbij maakt de AI eerst een model van een omgeving en de mogelijke acties, om op basis daarvan een keus te maken over de beste volgende stap.
Bij afgekaderde omgevingen zoals een spel als Go is dat nog wel te doen, maar bij visuele omgevingen zoals een computergame wordt dat moeilijker omdat er zoveel verschillende aspecten zijn om rekening mee te houden. "MuZero gebruikt een andere aanpak om over dat soort limieten heen te komen", schrijven de wetenschappers. "In plaats van een model van een complete omgeving te maken, creëert MuZero een model op basis van alleen de aspecten die belangrijk zijn voor het beslissingsproces." De AI kijkt daarbij specifiek naar de waarde van de huidige positie, de waardeberekening van wat de beste actie is om uit te voeren, en vervolgens een waarde van het resultaat van de vorige actie. Op die manier kan MuZero ook werken in een omgeving waarbij het vooraf niet weet wat de parameters en beperkingen zijn.
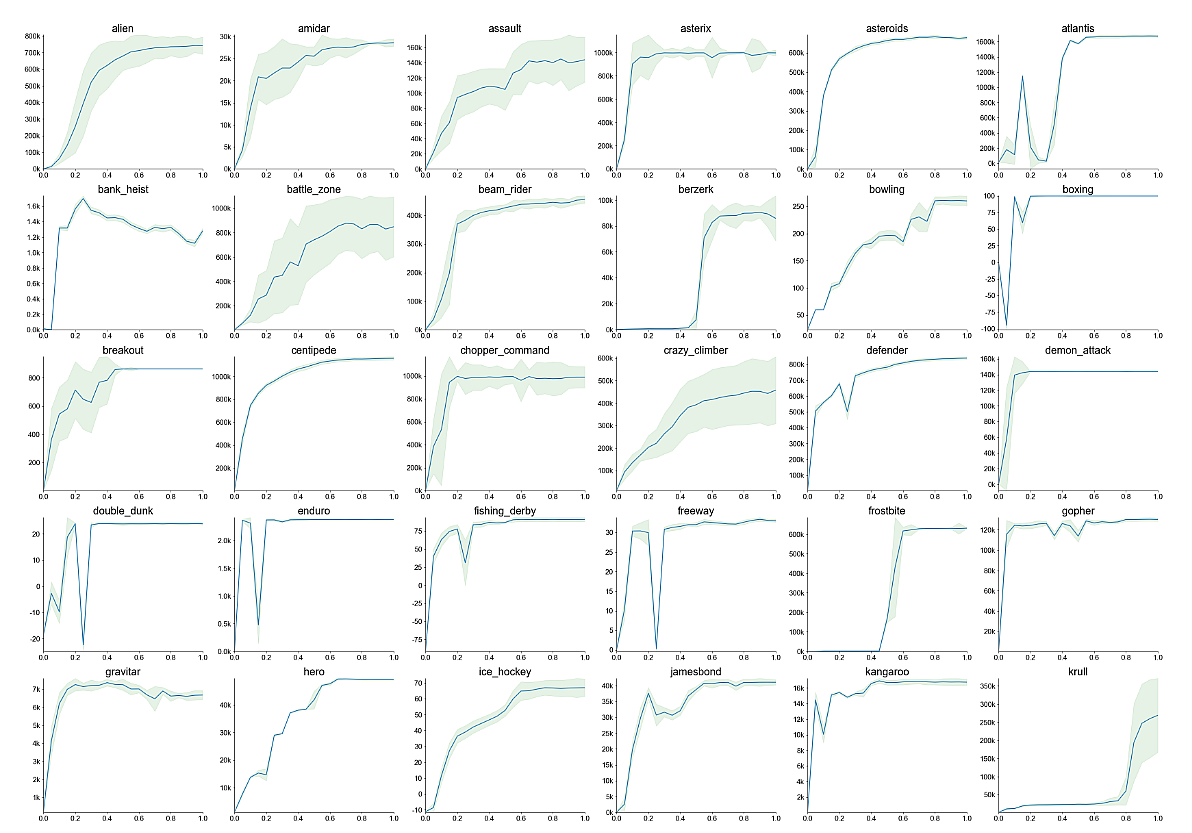
De onderzoekers lieten MuZero vervolgens los op enkele visuele spellen van Atari, waaronder Ms Pac-Man. Daar moest de AI zelf leren wat de beste acties waren om te nemen. Het resultaat is volgens de onderzoekers dat hoe meer trainingen MuZero zelf kan uitvoeren, hoe slimmer de AI het spel kan spelen. In totaal lieten de onderzoekers MuZero 57 Atari-games spelen, waaronder Defender, Alien, Space Invaders en Yars Revenge, blijkt uit de tijdelijke paper die vorig jaar al verscheen.

/i/2006234860.webp?f=fpa)
/i/2005643082.png?f=fpa)
/i/2001673275.png?f=fpa)
/i/2004767628.png?f=fpa)
:strip_exif()/i/2002668286.jpeg?f=fpa)
/i/1272967164.png?f=fpa)
/u/11182/peertop.png?f=community)
:strip_icc():strip_exif()/u/223002/crop6061dc6b02d4e_cropped.jpg?f=community)
:strip_exif()/u/25889/boes.gif?f=community)
:strip_icc():strip_exif()/u/604726/crop5f3b635b14ae7_cropped.jpeg?f=community)
/u/263454/crop69528a83920d8.png?f=community)
:strip_icc():strip_exif()/u/418482/crop66d2c0318683d_cropped.jpg?f=community)
:strip_icc():strip_exif()/u/10917/crop562b75f07b9fd_cropped.jpeg?f=community)
:strip_exif()/u/26289/ahxp68H.gif?f=community)
/u/3626/front-kabels.png?f=community)
:strip_icc():strip_exif()/u/81611/headcrop.jpg?f=community)
/u/465331/MeControlXXLUserTile2.png?f=community)
:strip_exif()/u/27690/Misc_-_Boy.gif?f=community)
:strip_exif()/u/106680/LOY_kleinerder.gif?f=community)
:strip_icc():strip_exif()/u/376677/crop57a323960b3ec_cropped.jpeg?f=community)
/u/411173/Untitled.png?f=community)
:strip_icc():strip_exif()/u/83932/crop69569239a5694_cropped.jpg?f=community)
:strip_icc():strip_exif()/u/3477/crop55bcb1b0d76b6_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/629386/crop64ff4ce891e4b_cropped.jpg?f=community)