Wetenschappers van Google en gezondheidstechnologiebedrijf Verily, een dochter van Google, hebben een nieuwe manier ontwikkeld om via het scannen van de achterkant van het oog data af te leiden waarmee de kans op hart- en vaatziekten zoals een hartaanval kan worden voorspeld.
Door het scannen van het netvlies kan er data zoals de leeftijd, geslacht, bloeddruk en of de patiënt een roker is worden afgeleid. Dit kan dan worden gebruikt om te voorspellen hoe hoog het risico is op bepaalde hart- en vaatziekten. Het gaat hierbij om een foto van de vele bloedvaten aan de achterkant van het oog.
Tijdens het onderzoek zijn onder meer twee netvliesfoto's van twee verschillende patiënten gebruikt, waarbij een patiënt in de vijf jaar na de gemaakte foto's een hartprobleem kreeg. Googles algoritme bleek in staat om, zonder andere datapunten te gebruiken, in 70 procent van de gevallen de foto toe te schrijven aan de juiste patiënt. Een medicus van de Universiteit van Adelaide heeft tegen The Verge gezegd dat het om een degelijk onderzoek gaat dat het mogelijk maakt om meer uit de beschikbare data te halen dan tot nu toe kon.
Volgens de onderzoekers van Verily is een van de interessante aspecten van dit onderzoek dat er heatmaps zijn gemaakt waarbij bepaalde delen van het netvlies worden gemarkeerd die het meest hebben bijgedragen aan de voorspellingen van het algoritme. De onderzoekers stellen dat dit nieuwe inzichten kan opleveren en medici meer vertrouwen kan geven in het neurale netwerkmodel.
De deep learning-modellen van Google zijn getraind op data afkomstig van meer dan 284.000 patiënten. De data voor deze analyses betrof niet alleen oogscans maar ook algemene medische gegevens. Via een neuraal netwerk werden patronen herkend, waarbij data afkomstig van de oogscans kon worden geassocieerd met risicofactoren voor hart- en vaatproblemen. Volgens Google gevalideerd op basis van twee onafhankelijke datasets van 12.026 en 999 patiënten.
De onderzoekers erkennen wel dat hun studie nog een aantal beperkingen kent. Allereerst zijn er enkel afbeeldingen gebruikt met een beeldhoek van 45 graden. Daarnaast zeggen de wetenschappers dat de gebruikte grootte van de dataset relatief klein is voor deep learning. Ook zaten bepaalde belangrijke gegevens voor hart- en vaatziekten, zoals de hoeveelheid lipiden in iemands bloed, niet in de gebruikte datasets. Bovendien waren de gegevens over of iemand wel of niet rookte afkomstig van de patiënt zelf, waardoor ze misschien niet volledig betrouwbaar zijn.
Het onderzoek is gepubliceerd in het wetenschappelijke tijdschrift Nature Biomedical Engineering, onder de titel Prediction of cardiovascular risk factors from retinal fundus photographs via deep learning.
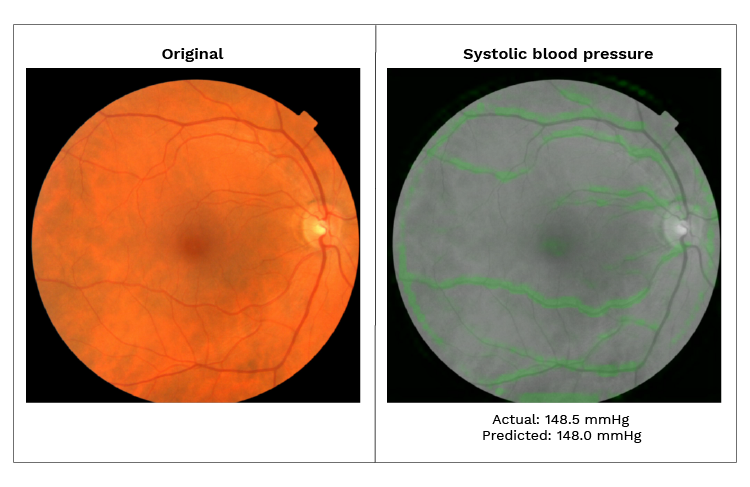
Een afbeelding van dezelfde retina, waarbij de linkerfoto de standaardafbeelding is. De tweede afbeelding toont een heatmap waarbij de bloedvaten in het groen zijn gemarkeerd die het algoritme heeft gebruikt voor het voorspellen van een hoge bloeddruk.

:strip_exif()/i/2002975184.jpeg?f=fpa)
/i/2000946919.png?f=fpa)
/i/2001306611.png?f=fpa)
/i/2000820476.png?f=fpa)
:strip_exif()/i/1329312935.jpeg?f=fpa)
/i/2000658159.png?f=fpa)
/i/2001673275.png?f=fpa)
:strip_exif()/i/1226520683.gif?f=fpa)
:strip_icc():strip_exif()/u/79859/crop562e258ce2088_cropped.jpeg?f=community)
:strip_exif()/u/99932/crop5dd2833d839d3.gif?f=community)
/u/117810/cupcake2.png?f=community)
:strip_icc():strip_exif()/u/242056/hellno%2520-%2520Copy.jpg?f=community)
:strip_icc():strip_exif()/u/449263/crop59b00bd24834c_cropped.jpeg?f=community)
/u/331213/crop56ef13408ff38_cropped.png?f=community)
/u/216161/crop5daf72732a011.png?f=community)
:strip_icc():strip_exif()/u/554690/crop56cf0303082a5_cropped.jpeg?f=community)
:strip_exif()/u/71609/avat.gif?f=community)
/u/90124/RedRobot%2520-%2520Nieuw.png?f=community)