Op internet zijn slides verschenen van een gddr5x-presentatie van Micron. De fabrikant schuift deze uitbreiding van de gddr5-standaard naar voren als de nieuwe generatie voor videogeheugen. Daarmee is het een concurrent voor high bandwidth memory.
Micron maakte begin september bekend aan gddr5x te werken en beloofde de technologie in 2016 officieel te onthullen, maar Expreview publiceert al een presentatie met details over de gddr5-uitbreiding. Het vergroten van de snelheid van gddr5 is een uitdaging, volgens Micron. Bij het ontwikkelen van de standaard was de verwachting dat de doorvoersnelheid op maximaal 5Gbit/s uit zou komen, maar die gaat nu al richting de 8Gbit/s. Daarnaast zou de kloksnelheid van het geheugen aan zijn maximum zitten en loopt ook het command/address-protocol tegen zijn grenzen aan.
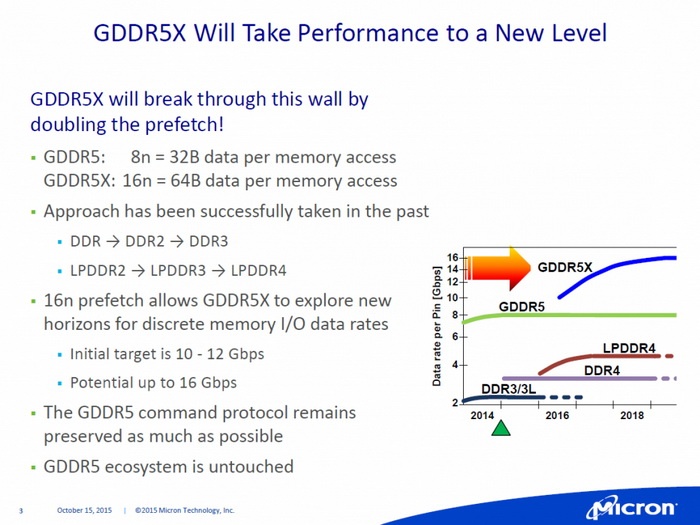
Waar echter nog wel rek in zit is de prefetchbuffer, claimt Micron. Door de grootte van de buffer te verdubbelen van acht 'datawoorden' per aanspreken van het geheugen, naar zestien 'datawoorden', zou een doorvoersnelheid van aanvankelijk zo'n 10 tot 12Gbit/s te realiseren zijn. Op termijn moet dan 16Gbit/s binnen handbereik komen. In combinatie met een 384 bits brede bus, levert dat een bandbreedte van in initieel 480GBps en in een later stadium 768GBps op.
Ter vergelijking: het bij AMD's Fury-gpu's gebruikte high bandwidth memory of hbm, komt bij gebruik van vier stacks met vier lagen met elk een datarate van 1Gbit/s op 512GBps uit. Bij hbm is echter veel ruimte voor verbetering, zowel wat betreft het aantal lagen als het aantal stacks. De nieuwe Radeon-generatie van AMD is met hbm uitgerust en ook toekomstige Nvidia-kaarten krijgen het, zodra de nieuwe generatie hbm gereed is. Volgens geruchten gaat Nvidia de mainstream-gpu's op basis van de komende Pascal-architectuur van gddr5x-geheugen voorzien.
In 2016 moeten de eerste videokaarten met gddr5x-geheugen op de markt verschijnen. Volgens Micron is het voordeel van het geheugen dat dezelfde formfactor gebruikt wordt, waardoor fabrikanten de huidige beproefde productiemethoden kunnen blijven hanteren.




/i/1217925693.png?f=fpa)
/i/2000820476.png?f=fpa)
:strip_exif()/i/1147882757.jpg?f=fpa)
/i/1349425400.png?f=fpa)
:strip_exif()/i/2000538328.jpeg?f=fpa)
/i/2000584654.png?f=fpa)
:strip_exif()/i/1380099265.jpeg?f=fpa)
/u/250559/crop561e31da23111_cropped.png?f=community)
:strip_exif()/u/296989/webicon.gif?f=community)
:strip_icc():strip_exif()/u/174878/SCKnightMicro.jpg?f=community)
:strip_icc():strip_exif()/u/322461/crop55d1c8e0d769f_cropped.jpeg?f=community)
-PCB.jpg){kind=link}