Onderzoekers van de Universiteit van Amsterdam hebben een algoritme ontwikkeld dat voorspelt welke opkomende onderwerpen dusdanig in de belangstelling staan dat ze een eigen Wikipedia-artikel verdienen. Het algoritme maakt hiervoor gebruik van Twitter.
De Universiteit van Amsterdam maakte de bevindingen dinsdag bekend. De onderzoekers passen de bestaande named entity recognition-technologie toe in combinatie met een zelfontwikkeld algoritme om personen, locaties en organisaties te herkennen die nog niet op Wikipedia staan maar dat wel zouden verdienen. De software leest tweets uit en bepaalt eerst of de inhoud ervan al op Wikipedia terug te vinden is. Wanneer ze over al bekende zaken gaan en wat taalgebruik aangaat van een voldoende niveau zijn, worden ze door het algoritme doorgezet als voorbeelden van hoe Twittergebruikers over onderwerpen schrijven die al op Wikipedia staan.
Het algoritme kijkt onder andere naar zaken als hoofdlettergebruik en de lengte en volgorde van woorden om te leren hoe Twittergebruikers formuleren en bij welk Wikipedia-lemma die formuleringen horen. Hoe meer voorbeelden het algoritme aan het named entity recognition-systeem voorschotelt, hoe beter het in staat is de patronen te herkennen bij tweets die over voor Wikipedia onbekende onderwerpen gaan.
Deze kennis wordt vervolgens toegepast op Twitterberichten die niet herkend worden als tweets met een geassocieerd Wikipedia-lemma. Het door het algoritme gevoede nerc-model stelt daarna vast of een tweet over bijvoorbeeld een persoon, locatie of organisatie gaat. Op het moment dat een van die zaken vaak genoeg op dezelfde manier de revue passeert op Twitter, zal het nerc-model vaststellen dat het gaat om een onderwerp dat genoeg onder de aandacht van Twittergebruikers is gekomen om een eigen Wikipedia-lemma te rechtvaardigen.
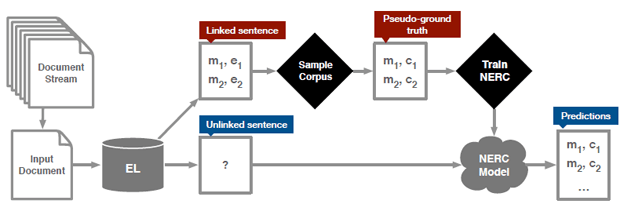
Het algoritme, dat als werktitel 'Unsupervised Pseudo-ground Truth' heeft, werkt op het moment bij personen, locaties en organisaties. Echter, met weinig aanpassingen kan het ook werken om bijvoorbeeld titels van boeken en films te herkennen. Het zal in de praktijk vooral nut hebben voor trendwatchers en mensen die bijdragen aan Wikipedia. David Graus, promovendus bij de Universiteit van Amsterdam en hoofdontwikkelaar van het algoritme, stelt tegenover Tweakers dat hij door wil gaan met de ontwikkeling en een live-versie van het algoritme online wil zetten, maar wanneer dat gaat gebeuren, is nog niet bekend. Ook zijn er plannen om in de toekomst het algoritme opensource te maken.

/i/1228729281.png?f=fpa)
:strip_exif()/i/1059519197.gif?f=fpa)
/i/1274283530.png?f=fpa)
/i/1337244622.png?f=fpa)
:strip_icc():strip_exif()/u/481839/e-resized.jpg?f=community)
/u/35505/flx_70x70.png?f=community)
:strip_icc():strip_exif()/u/186602/Genetai_Steam%2520_klein.jpg?f=community)
:strip_icc():strip_exif()/u/269508/crop55c9d5fae106a_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/47056/qasreshirin_mementomori11.jpg?f=community)
/u/152864/crop59af8ee117886_cropped.png?f=community)
:strip_exif()/u/327460/cowboy.gif?f=community)
/u/42648/crop635863345e4c0.png?f=community)
:strip_icc():strip_exif()/u/489435/crop68df75fbb4870_cropped.jpg?f=community)
:strip_exif()/u/29005/jackass.gif?f=community)
:strip_icc():strip_exif()/u/171690/crop5db00e7903620_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/162143/crop5b6d888e9cc79_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/492360/crop60076319881d9_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/571506/dier.jpg?f=community)