
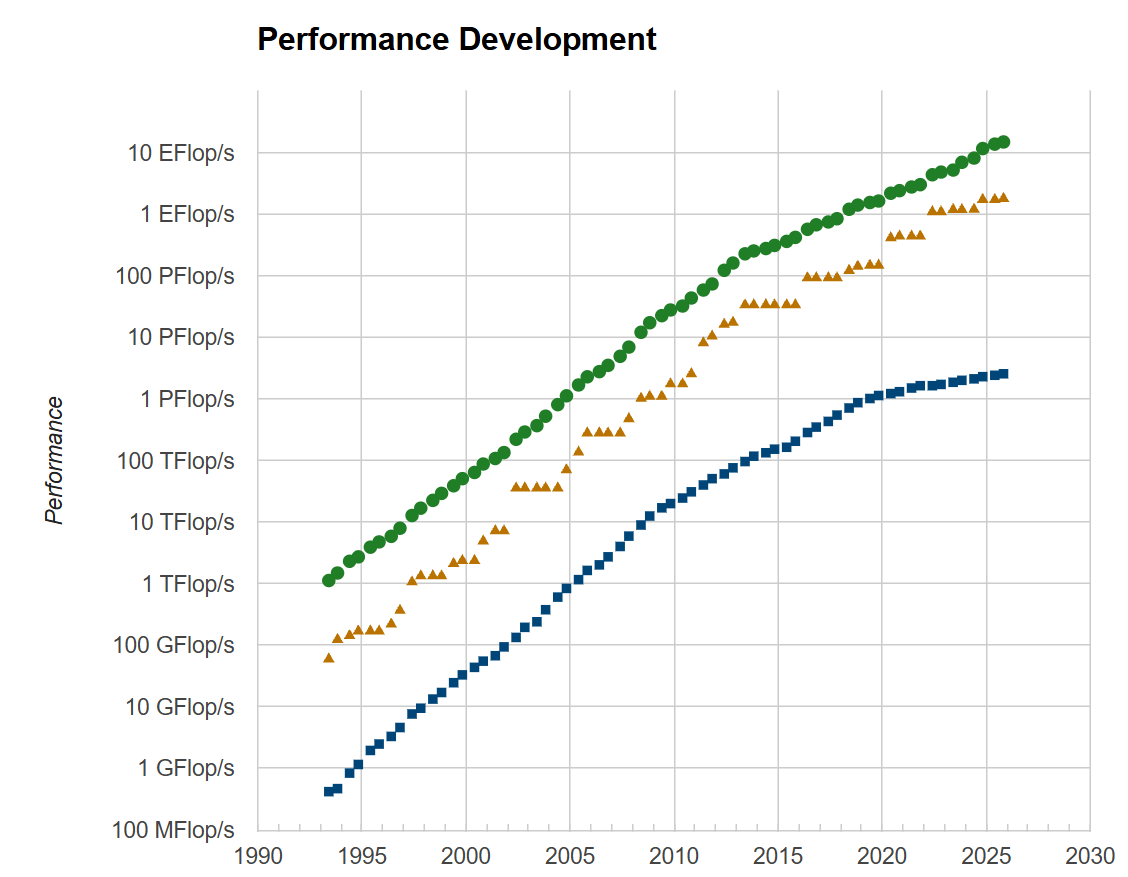
Met de introductie van de Duitse Jupiter was de eerste exascalesupercomputer van Europa vorig jaar een feit. Daarmee nam het rekenmonster, met een budget van meer dan 500 miljoen euro, ook meteen de vierde plaats in de prestigieuze TOP500-lijst, waarin de krachtigste supercomputers ter wereld worden gerangschikt. Alleen in de Verenigde Staten staan hpc-systemen die nog hoger scoren.
Nu is het natuurlijk leuk om te kunnen pochen met het feit dat Europa in staat is tot exascalecomputing, maar dat roept ook de vraag op in hoeverre zoveel rekenkracht daadwerkelijk een praktisch nut heeft. Waar wil Europa exascalecomputing voor gebruiken en welke doelen hoopt het Jülich Supercomputing Centre, waar Jupiter deel van uitmaakt, te bereiken met die miljard miljard flops?
EuroHPC
In Europa hebben de afgelopen decennia al veel supercomputers de revue gepasseerd. Sterker nog: in bijna alle Europese landen staat er wel een, denk bijvoorbeeld aan Snellius, de nationale supercomputer van Nederland. "Die werden nog veelal op nationaal niveau ontworpen", vertelt Andreas Herten van het Jülich Supercomputing Centre aan Tweakers. "Je had wel samenwerkingsverbanden als PRACE, maar er was geen overkoepelende centrale structuur."
Dat veranderde zo'n tien jaar geleden, toen duidelijk werd dat de bouw van een exascalesupercomputer binnen handbereik was. "Om dat punt te bereiken, was het economisch gezien verstandig om de Europese middelen samen te brengen om zo gezamenlijk exascalecomputing mogelijk te maken." Daarvoor richtte de EU het EuroHPC Joint Undertaking op. In tegenstelling tot PRACE krijgt EuroHPC omvangrijke financiering vanuit de EU, waardoor het eenvoudiger werd voor lidstaten om samen te werken aan grootschalige projecten.
Vanuit EuroHPC werd een oproep geplaatst voor voorstellen voor het hosten van een exascalecomputer. Het voorstel met de meeste potentie zou financiering ontvangen voor de uitvoering ervan. Het concept van Jülich Supercomputing Centre werd door de onafhankelijke jury gekozen, al weet Herten ook niet precies wat de doorslag gaf. "Het zou kunnen doordat we al veel ervaring hebben met het beheer van largescalesystemen. We hebben al eerder enkele van de krachtigste machines in Europa in huis gehad. Ook hebben we een grote researchcommunity en veel computerwetenschappers."
:strip_exif()/i/2007998362.jpeg?f=imagegallery)
Toekomstige Europese exascalecomputer
Naast Jupiter is er nog een andere exascalesupercomputer in aanbouw. Het gaat om het Franse Alice Recoque, met AMD Epyc-cpu's van de Venice-generatie en Radeon Instinct MI430X‑gpu's. Deze chips moeten later dit jaar beschikbaar komen, maar het is nog niet duidelijk wanneer Alice Recoque operationeel wordt. De maker zegt dat de supercomputer 'soevereine AI' mogelijk moet maken.
Modulaire architectuur
Nadat Jülich tot hostlocatie werd gekozen, kwam het zelf met een oproep aan bedrijven die een dergelijke computer kunnen leveren. Uiteindelijk kwam een consortium van Eviden en ParTec als winnaar uit de bus. Volgens Herten was het bijzondere van het voorgestelde ontwerp, dat het systeem uit twee delen bestaat.
"We noemen dit een modulaire supercomputerarchitectuur, waarbij we verschillende soorten supercomputers combineren in een supersupercomputer." Volgens hem was het belangrijk dat de supercomputer zowel goed moet kunnen omgaan met programma's die beter werken op de cpu als met gpu-programma's.
Een van de delen, het cluster, is toegespitst op cpu-intensieve applicaties, terwijl de booster hetzelfde doet voor de gpu. Er is ook software aanwezig die een programma op beide onderdelen kan laten werken, indien een bepaald onderdeel goed werkt op de cpu en een ander deel van datzelfde programma juist baat heeft bij een gpu.
Van deze wisselwerking is momenteel trouwens nog geen sprake, want de cpu-cluster is nog helemaal niet gebouwd. De huidige prestaties komen allemaal voort uit de boostermodule, al levert deze dan ook veruit de meeste rekenkracht.
Jupiter haalt volgens de TOP500-lijst nu een pieksnelheid van 1,226 exaflops. Daarmee kan de supercomputer in theorie ruim 1 triljoen berekeningen per seconde uitvoeren. De cpu-cluster moet echter 'slechts' zo'n 10 petaflops aan rekenkracht halen. Ter vergelijking: de snelste supercomputer in Nederland is momenteel ISEG2 van Nebius, met een pieksnelheid van 338 petaflops. De Belgische topper heet Lucia en haalt volgens de TOP500-lijst een pieksnelheid van 2,7 petaflops.
Gpu en cpu in harmonie
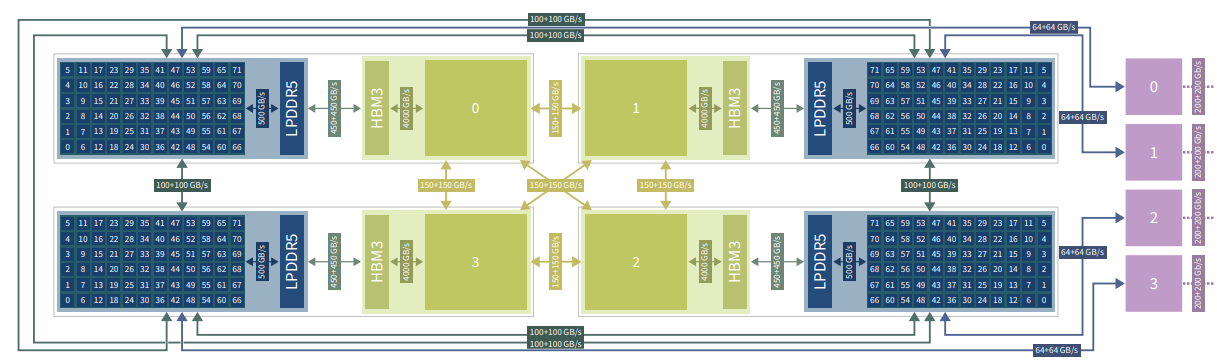
Het is de bedoeling dat de cpu-module gebruikmaakt van Europese processors. Het gaat om ruim 1300 SiPearl Rhea1-cpu's, ieder met 80 Arm Neoverse V1-cores en 64GB HBM. Toch is er voor de krachtigere boostermodule gekozen voor 24.000 Nvidia GH200-'superchips'. Iedere GH200 bestaat uit een Grace-cpu met 72 Arm Neoverse V2-cores, een Hopper-gpu met 16.896 CUDA-cores en 96GB HBM3. Volgens Herten was het een belangrijke eis dat de chips zowel een cpu als gpu bevatten; en dan ben je vooralsnog op een Amerikaanse fabrikant aangewezen.
"De gpu en cpu zijn nu sterk met elkaar verbonden via NVLink-C2C-interconnecttechnologie", legt Herten uit. "De cpu kan zo'n tien keer sneller gegevens overdragen naar de gpu dan bij een traditioneel systeem. Dat maakt complexere methodes en algoritmes mogelijk waarbij de samenwerking tussen cpu en gpu belangrijk is."
Als praktisch voorbeeld van waar deze technologie voor kan dienen, geeft Herten het runnen van klimaatmodellen. De computer kan een model draaien dat bestaat uit tientallen submodellen die allemaal gebruikmaken van een eigen programma. De algehele simulatie vindt plaats op de gpu, terwijl deze kleinere programmaatjes draaien op de cpu. Ondertussen wisselen ze continu data met elkaar uit.
Hiervoor heeft een team onderzoekers, waaronder van JSC, onlangs een Gordon Bell Prize for Climate Modelling gewonnen. Deze 'Nobelprijs voor supercomputing' wordt jaarlijks uitgereikt aan een vooruitstrevend project op het gebied van high-performance computing.
Laag energieverbruik
Herten beweert dat de Duitse supercomputer niet alleen erg snel is, maar ook energie-efficiënt. Dat komt mede door de koelmethode. Het datacenter bestaat uit circa vijftig containers waarin de serverracks, powerstations en koelsystemen zijn opgeslagen.
De TOP500-lijst is niet onomstreden
Niet iedereen hecht evenveel waarde aan de TOP500-lijst, die bijhoudt wat 's werelds krachtigste supercomputers zijn. Dat komt doordat de scores worden gebaseerd op één specifieke benchmark: High-Performance Linpack (HPL). Deze wordt gebruikt omdat HPL goed schaalt naar steeds grotere systemen en een simpele score oplevert om de computers mee te vergelijken.
Tegelijkertijd is de benchmark volgens critici niet representatief, omdat deze slechts een bepaald type berekening beoordeelt. Om een hoge score te behalen, is het dus een kwestie om de supercomputer precies zo te finetunen dat hij in HPL optimaal presteert. Sommige supercomputerfabrikanten weigeren om daaraan mee te werken, waardoor de TOP500-lijst niet alomvattend is.
De chips worden via een closed-loop gekoeld met water (direct liquid cooling). Het opgewarmde water wordt afgevoerd naar koelsystemen op het dak van de container, waar de warmte via een warmtewisselaar aan de buitenlucht wordt afgegeven. Onder normale omstandigheden is dit voldoende dankzij het gebruik van relatief warm koelwater. Op hete dagen kan ook adiabatische koeling worden ingezet, waarbij waterdamp wordt gebruikt om de lucht verder af te koelen.
Bij het behalen van exascalecomputing verbruikt het systeem volgens Herten nooit meer dan 17MW, met een gemiddelde van 15,7MW (op basis van de TOP500-benchmark). Het is daarmee tot dusver de exascalecomputer met het laagste energieverbruik. Volgens de TOP500-lijst verbruiken de andere drie systemen minstens gemiddeld 24MW.
Ook op de Green500-lijst van dezelfde partij staat Jupiter hoger dan zijn exascalegenootjes. Hierbij worden de supercomputers niet gerangschikt naar absolute rekenkracht, maar naar rekenkracht per watt.
Het Duitse systeem staat momenteel op plek 14, met prestaties van 63,3 gigaflops per watt. Volgens Herten kan Jupiter in deze lijst nog zuiniger presteren, mits het bedrijf zijn supercomputer optimaliseert voor efficiëntie. Hij zegt dat de systemen die hoger staan in de lijst een toegewijde efficiëntierun hebben ingediend, terwijl de Green500-score van Jupiter gebaseerd is op precies dezelfde run als voor de TOP500-score. Volgens Herten is het nog onzeker of het team in de toekomst ook een toegewijde Green500-run zal indienen.
Early access
Hoewel Jupiter nog in aanbouw is, is de supercomputer de afgelopen maanden aan circa honderd onderzoeksteams beschikbaar gesteld als onderdeel van een earlyaccessprogramma. Wanneer de productie volledig van start gaat, wordt de beschikbare capaciteit verdeeld via een open beoordelingsprocedure, legt Herten uit. "Iedereen met een goed wetenschappelijk doel mag een onafhankelijke jury overtuigen om capaciteit te krijgen. Een aantal keer per jaar rouleren we de capaciteit weer."
De supercomputer is bereikbaar via een SSH-inlognode of via een Jupyter-portal. "We proberen gebruikers close to the metal te laten werken, want dan krijg je de meeste prestaties", zegt Herten. "Dat betekent dat we geen gebruikmaken van virtualisatie. Gebruikers dienen de rekentaak in via resourcemanagementtool Slurm en krijgen vervolgens een node toegewezen voor hun workload waarna ze hun programma kunnen uitvoeren." Het is wel mogelijk om containers te gebruiken, maar dat doet niet iedereen. Dat gebeurt via Apptainer (voorheen Singularity), een containerruntime die specifiek bedoeld is voor hpc-systemen. In tegenstelling tot het soortgelijke Docker is het hierbij niet mogelijk dat gebruikers toegang krijgen tot de rootrechten van het systeem.
Tijdens de early access wordt er vrijwel exclusief wetenschappelijk onderzoek mee uitgevoerd, zoals voor astro- en plasmafysica en voor computational fluid dynamics. Ook wordt de rekenkracht door scheikundigen ingezet voor het simuleren van moleculen. Het is de bedoeling dat er in de toekomst ook meer industrieel onderzoek mogelijk is met het systeem. Volgens Herten moet uiteindelijk een kwart van de capaciteit beschikbaar komen voor 'innovatieprojecten', vooral op het gebied van AI.
Overigens is het JSC al bezig met de doorontwikkeling van het systeem, dat daardoor voor meer usecases bruikbaar wordt. Zo geeft Herten aan dat het de bedoeling is dat er in de toekomst een derde module aan Jupiter wordt toegevoegd genaamd Jarvis. Deze wordt toegespitst op AI-inferencing, oftewel het toepassen van een getraind model op nieuwe data.
De boostermodule wordt dan verlicht en hoeft zich alleen nog bezig te houden met het trainen van AI-modellen. Dat is echter vooruitlopen op de feiten, eerst moet de boostermodule nog uit de earlyaccessfase komen, waarna de supercomputer overgaat op reguliere operaties. Het is de bedoeling dat deze mijlpaal een dezer dagen plaatsvindt.
Redactie: Kevin Krikhaar • Eindredactie: Monique van den Boomen
:strip_icc():strip_exif()/i/2008271054.jpeg?f=fpa_thumb)
:strip_icc():strip_exif()/i/2004673186.jpeg?f=fpa_thumb)
:strip_exif()/i/2008187916.jpeg?f=fpa)
:strip_exif()/i/2007907326.jpeg?f=fpa)
:strip_exif()/i/2007714636.jpeg?f=fpa)
/i/2004779058.png?f=fpa)
:strip_icc():strip_exif()/u/36378/crop5a3f931ecfec0_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/76079/crop59db67005c11d_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/320033/Joene60.jpg?f=community)
:strip_exif()/u/467778/crop5d7a5dd1f296a.gif?f=community)
/u/1308516/crop6a340a561505f.png?f=community)
/u/12436/p1_normal.png?f=community)
:strip_icc():strip_exif()/u/262645/Waldorf.jpg?f=community)
:strip_icc():strip_exif()/u/835039/crop674f95ad15331_cropped.jpg?f=community)
:strip_icc():strip_exif()/u/57655/SuperTeamLogo.jpg?f=community)
:strip_icc():strip_exif()/u/396403/crop5dcc11ba166fe_cropped.jpeg?f=community)
/u/438628/Brickster_LI1%2520-%2520Copy.png?f=community)
:strip_exif()/u/48440/crop6130a5af754ae_cropped.webp?f=community)