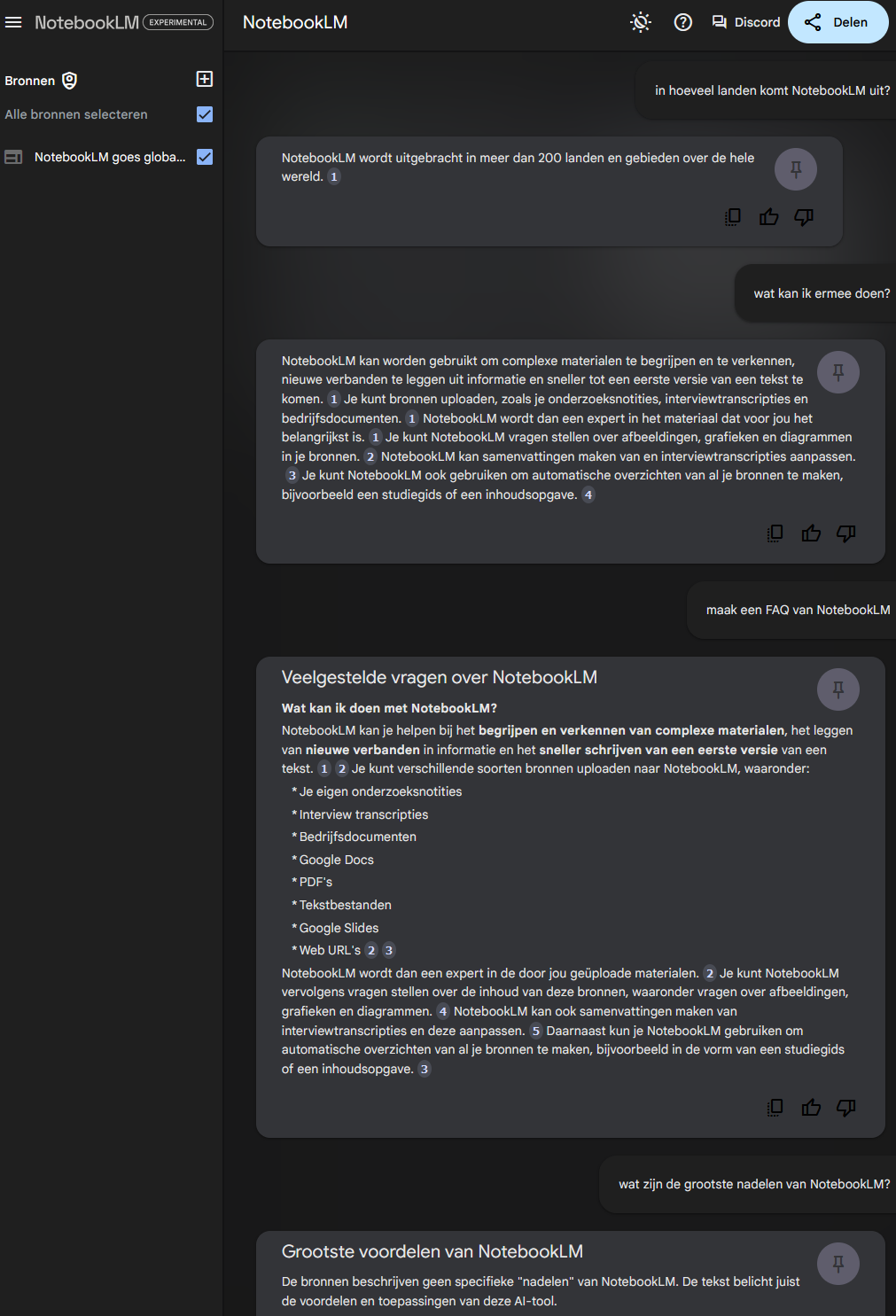
De chatbot geeft ondanks dat het alleen de bronnen gebruikt wel de melding dat het mogelijk onjuiste informatie geeft.
Vind het woord "ondanks", zeker misplaatst hier. Dat betekent dat als je uitgaat van 100% correcte bronnen er iets of iemand bestaat waarvan je met 100% zekerheid kunt stellen dat zij een correcte afgeleidde maken.
Inherent aan taal is dat wanneer je het afleidt dat je context verliest. Tijdens dit proces wordt er geïnterpreteerd wat tot op bepaalde hoogte subjectief is.
Taal is regelmatig vaag of er worden metaforen gebruikt, beeldspraak en wat dan ook (Ook ironie, sarcasme etc). Al deze dingen zorgen voor meerdere interpretaties die correct kunnen zijn. Hier bestaat een gigantisch onderzoeksveld voor wat Natural Language Processing heet waar al deze LLMs gretig gebruik van maken.
Taal kan dus inherent onduidelijk zijn en aangezien onduidelijke input = onduidelijke output is kan en mag je geen perfecte correctheid verwachten. Dat zou dus ook niet geïnsinueerd moeten worden.
Laat nou een van de grootste valkuilen van de huidige LLMs zijn dat ze zeer overtuigend en zelfverzekerd incorrect zijn. Het doel van deze LLM is om deze "hallucinaties" te verminderen. Oftewel de frequentie brengen ze omlaag door ander bronmateriaal maar ik vermoed niet de heftigheid van het hallucineren wat simpel weg in het model zit.
Edit toevoeging;
Ons land draait op deze imperfecties, vaagheden en interpretaties. Kijk naar het rechtssysteem, de interpretatie van de wet is hoe het land draait.
[Reactie gewijzigd door Horatius op 23 juli 2024 03:30]

/i/2008260276.png?f=fpa)
/i/2004612784.png?f=fpa)
:strip_exif()/i/2007387390.jpeg?f=fpa)
:strip_exif()/i/2005500190.jpeg?f=fpa)
/i/2006621506.webp?f=fpa)
:strip_exif()/i/2005393580.jpeg?f=fpa)
/i/2005833656.png?f=fpa)
:strip_icc():strip_exif()/u/572004/fox.jpg?f=community)
/u/2008130/crop6536ebba0daf2_cropped.png?f=community)
:strip_icc():strip_exif()/u/46576/playerspinup_small.jpg?f=community)