DeepMind heeft AlphaStar Final getraind, een ai-agent die het Grandmaster-niveau bij rts StarCraft II heeft bereikt en beter speelt dan 99,8 procent van alle actieve spelers van het spel. De agent speelde anoniem online via Blizzards Battle.net-platform.
DeepMind gebruikte een combinatie van leren via reinforcement self-play, multi-agentgamepotjes via een eigen League en het imiteren van menselijke strategieën om van AlphaStar een Grandmaster te maken, het hoogste niveau dat op de StarCraft II-ladder te behalen is. Dat lukte de agent met de Terran, Zerg en Protoss, de drie facties in het spel.
Googles dochterbedrijf meldt dat de resultaten een sterk bewijs vormen dat dit soort algemene leertechnieken kunnen worden gebruikt om ai-systemen geschikt te maken voor werk in complexe, dynamische omgevingen met verschillende subjecten. Daarnaast verwacht het bedrijf dat de vorderingen kunnen helpen om kunstmatige intelligentie veiliger en robuuster te maken.
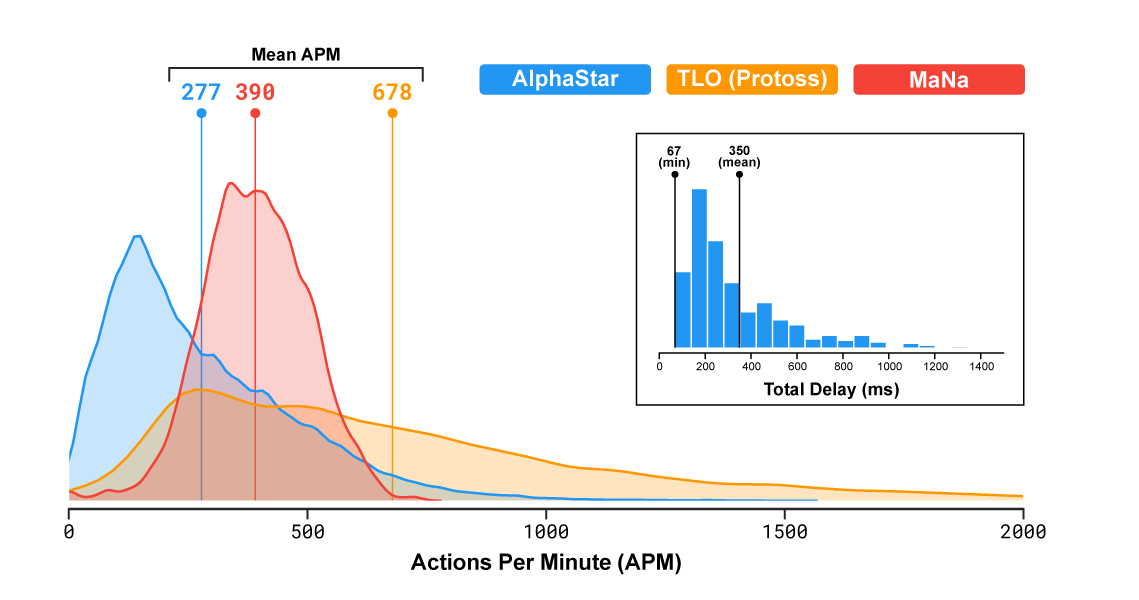
AlphaStar Final speelde ongemodificeerde StarCraft II-potjes op basis van een blikveld dat vergelijkbaar is met dat van mensen en met restricties om de action rate op het niveau van dat van menselijke spelers te brengen. Die snelheid van reageren is een van de eigenschappen waarmee machines gemakkelijk mensen kunnen overtreffen. Professionele StarCraft II-spelers hebben DeepMind geholpen bij het creëren van de beperkingen die tot evenwichtige omstandigheden moeten leiden. Het aantal acties per minute werd daarop gelimiteerd tot maximaal 22 per 5 seconden. Verder kan AlphaStar pas na 110ms een actie uitvoeren nadat een frame is waargenomen en kan hij vertraagd reageren op onverwachte situaties omdat agents vooruit beslissen waar ze gaan observeren.
DeepMind meldt dat het moeilijk is voor ai-agents om tot winnende strategieen te komen, doordat ze op elk moment in het spel meer dan 1026 mogelijke acties kunnen uitvoeren. Bovendien hebben de standaardleertechnieken hun eigen nadelen. Zo kan leren door tegen zichzelf te spelen leiden tot 'vergeetachtigheid', waarin een agent in een loop van terugkerende, winnende strategieën terechtkomt zonder iets nieuws te leren.
Tegen zichzelf spelen op basis van een willekeurige mix van eerdere strategieën, fictitious self-play genoemd, kan hierbij helpen. Alleen spelen om te winnen kan op zichzelf echter al beperkend zijn, claimt DeepMind. Daarom ontwikkelde het bedrijf exploiter agents die puur spelen om de zwakke plekken van een andere agent bloot te leggen. Verder werd AlphaStar slimmer door te leren op basis van imitatie. De kunstmatige intelligentie onderzocht daarbij het gebruik van strategieën van menselijke tegenstanders bij de potjes tegen zichzelf, waarbij onder andere analyses van openingszetten een rol speelden.
Professioneel speler Dario 'TLO' Wünsch zegt niet het gevoel te hebben gehad tegen een bovenmenselijke tegenstander te hebben gespeeld en Diego 'Kelazhur' Schwimer voegt daaraan toe dat spelen tegen de ai tot heel ongewone gameplay leidt en dat de agent geheel eigen speelstijlen en strategieën heeft.
De bevinding dat AlphaStar tot de beste spelers van StarCraft II kan behoren bij echte online gamerankings, volgt op een demonstratie in januari van dit jaar, toen een professionele speler van Team Liquid vijf wedstrijden verloor, maar een live wedstrijd won. Op die demonstratie kwam kritiek omdat de vergelijkingen van acties per minuut tussen mens en ai oneerlijk zouden zijn. Daarop zijn de restricties voor AlphaStar aangepast.
DeepMind publiceert de resultaten en de test in een artikel en op Nature met de titel Grandmaster level in StarCraft II using multi-agent reinforcement learning. Het bedrijf maakt alle replays van AlphaStar eveneens beschikbaar.

:fill(white):strip_exif()/i/2000845242.jpeg?f=thumbmedium)
:strip_exif()/i/2000845243.png?f=thumbmedium)
/i/2001673275.png?f=fpa)
:strip_exif()/i/2000560498.jpeg?f=fpa)
/i/1272959627.png?f=fpa)
:strip_exif()/i/1381178017.jpeg?f=fpa)
:strip_exif()/i/1238151812.jpeg?f=fpa)
:strip_exif()/i/1246286539.jpeg?f=fpa)
/i/2001015047.png?f=fpa)
:strip_exif()/u/99904/4100363.gif?f=community)
/u/594685/crop59b7f45a5e8f0.png?f=community)
:strip_icc():strip_exif()/u/259786/crop66d34575d79ce_cropped.jpg?f=community)
:strip_icc():strip_exif()/u/173388/crop5dbbf7660b2c7_cropped.jpeg?f=community)
/u/5360/crop65d3c045ca48f_cropped.png?f=community)
/u/869845/crop5914c62a4b458_cropped.png?f=community)
/u/478795/crop5db3b45de6668_cropped.png?f=community)
:strip_icc():strip_exif()/u/409490/crop5df407d7b44b6_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/1245508/crop5e4296e8a236f_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/41502/breezah.jpg?f=community)
{kind=link}
{kind=link}