Wetenschappers van de Amerikaanse Universiteit van Washington hebben kunstmatige-intelligentiealgoritmes ontwikkeld aan de hand waarvan audio-opnames omgezet kunnen worden in realistische mondbewegingen. Zij demonstreren de werking met beelden van ex-president Obama.
De wetenschappers willen hun onderzoek, getiteld 'Synthesizing Obama: Learning Lip Sync from Audio', presenteren op de komende Siggraph-conferentie in Los Angeles. Zij kozen voor de voormalige Amerikaanse president omdat er veel publiek beschikbaar videomateriaal van hem te vinden is. Om hun systeem op te zetten, maakten zij gebruik van twee stappen. Bij de eerste stap trainden zij een neuraal netwerk om Obama-video's te bekijken en de geluiden om te zetten in mondbewegingen.
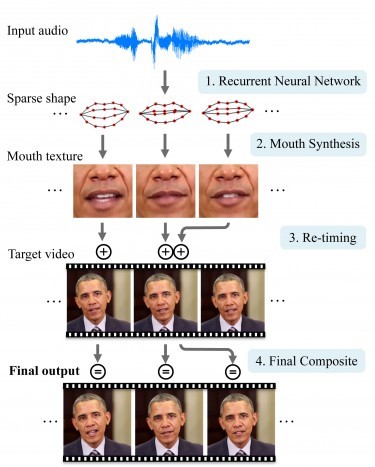 Bij de tweede stap maakten zij gebruik van eerder onderzoek om de bewegingen toe te voegen aan een bestaande referentievideo van de ex-president. Daarbij was het belangrijk dat het neurale netwerk door een korte vertraging de tijd kreeg om te anticiperen op de woorden van Obama. Het resultaat is dat er een realistische video van hem te zien is, waarbij hij woorden uitspreekt die voortkomen uit eerder opgenomen audio. Zo toont de demonstratievideo een opname uit 1990.
Bij de tweede stap maakten zij gebruik van eerder onderzoek om de bewegingen toe te voegen aan een bestaande referentievideo van de ex-president. Daarbij was het belangrijk dat het neurale netwerk door een korte vertraging de tijd kreeg om te anticiperen op de woorden van Obama. Het resultaat is dat er een realistische video van hem te zien is, waarbij hij woorden uitspreekt die voortkomen uit eerder opgenomen audio. Zo toont de demonstratievideo een opname uit 1990.
Er zijn volgens de wetenschappers verschillende toepassingen denkbaar voor de techniek. Zo is het bijvoorbeeld mogelijk om videochats te verbeteren. Deze hebben volgens een van de onderzoekers vaak last van slechte beeldkwaliteit, wat ondervangen kan worden door beeld te genereren aan de hand van het geluid. De benodigde beelden voor het trainen van het model zouden verkregen kunnen worden door eerdere videochatopnames. Een andere toepassing is het verifiëren van de echtheid van een bepaalde video. Dit zou mogelijk zijn door het proces om te draaien en het netwerk te voorzien van video in plaats van audio. Dit kan bijvoorbeeld een manier zijn om door kunstmatige intelligentie gegenereerde video's te herkennen, zoals beschreven in een recent artikel in Wired.
De gebruikte techniek zou dermate realistisch zijn, dat er geen sprake is van het uncanny valley-verschijnsel. Dat houdt in dat als een menselijke verschijning zeer realistisch overkomt, maar toch kleine gebreken vertoont, er een soort afkeer ontstaat bij de kijker. Volgens onderzoeker Supasorn Suwajanakorn ligt het gebied rond de mond en de kin wat dit betreft bijzonder gevoelig.
Demonstratievideo

:strip_exif()/i/1234902603.gif?f=fpa)
/i/1233670851.png?f=fpa)
/i/2001458235.png?f=fpa)
/i/1210945675.png?f=fpa)
:strip_exif()/i/1265625822.gif?f=fpa)
:strip_exif()/i/1298020644.gif?f=fpa)
/i/1351507873.png?f=fpa)
/u/70251/crop637cd55cef4e2_cropped.png?f=community)
:strip_icc():strip_exif()/u/888513/crop59395c817ede5_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/170876/crop60feac2476182_cropped.jpg?f=community)
:strip_icc():strip_exif()/u/282943/crop5871f50f1a61a_cropped.jpeg?f=community)
/u/298895/crop5620d9e595c62.png?f=community)
:strip_icc():strip_exif()/u/46233/art_planet_60x60.jpg?f=community)
:strip_exif()/u/12754/gif_gifsicle_140_gif_50x50_f91778.gif?f=community)
:strip_icc():strip_exif()/u/349538/crop5f49f8770b3f6.jpeg?f=community)
:strip_exif()/u/8825/tweakersNEW.gif?f=community)
:strip_icc():strip_exif()/u/621125/crop65cd0fde312bc_cropped.jpg?f=community)
:strip_icc():strip_exif()/u/116283/crop5814e3224425d_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/110760/ava.jpg?f=community)
:strip_icc():strip_exif()/u/541367/crop6679306ef1f8f_cropped.jpg?f=community)
:strip_exif()/u/381734/crop55e07ff7d28fa_cropped.gif?f=community)
:strip_icc():strip_exif()/u/671360/crop59c0fc364bef0_cropped.jpeg?f=community)
:strip_exif()/u/865/bj.gif?f=community)
:strip_icc():strip_exif()/u/155904/crop5ab030145f248_cropped.jpeg?f=community)
:strip_exif()/u/341057/minibeevatar.gif?f=community)
:strip_icc():strip_exif()/u/57655/SuperTeamLogo.jpg?f=community)