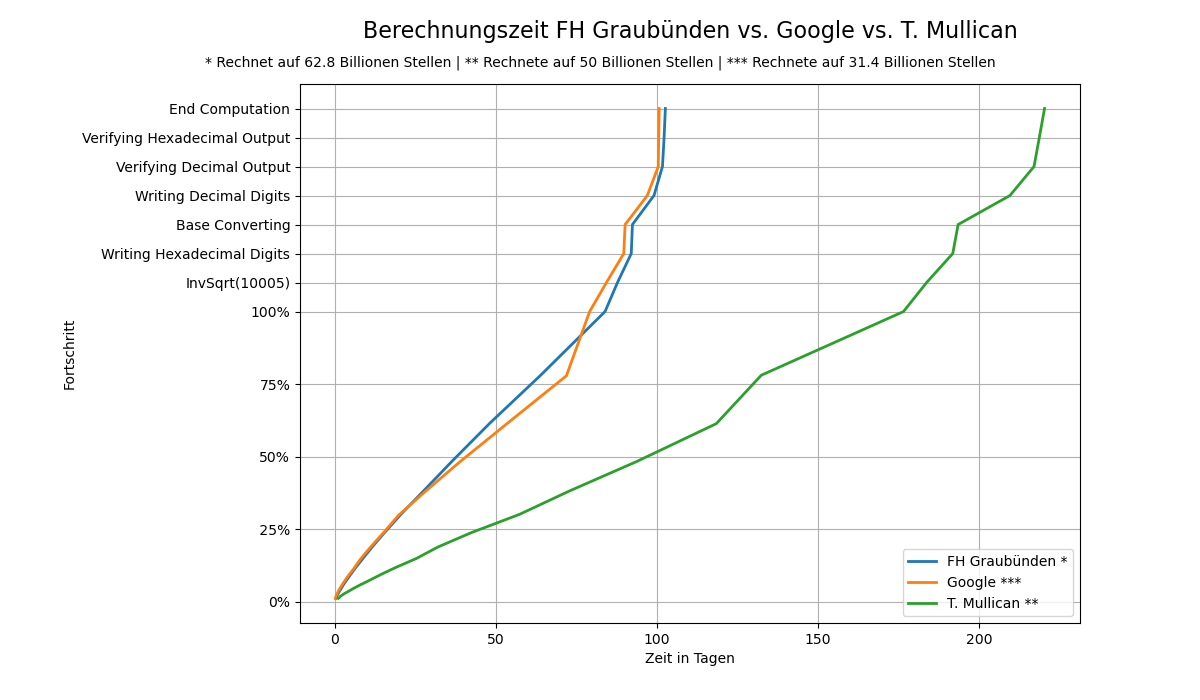
Een team van de Zwitserse Fachhochschule Graubünden heeft pi berekend tot een recordaantal cijfers achter de komma. Met twee AMD EPYC 7542-cpu's kwamen de studenten en onderzoekers na 108 dagen tot 62,8 biljoen decimalen.
De Zwitserse hogeschool gebruikte een systeem met twee AMD EPYC 7542-cpu's, die per stuk over 32 cores en 64 threads beschikken. Het berekenen van pi tot ver achter de komma vereist vooral veel geheugen; het gebruikte systeem was voorzien van 1TB ram en 510TB aan hdd's, die grotendeels ingezet werden als swapgeheugen. De configuratie bestond uit 38 hdd's in JBOD met een capaciteit van 16TB per stuk en een toerental van 7200rpm. Daarvan werden er 34 gebruikt als swapgeheugen en 4 voor de opslag van pi.
Het team gebruikte y-cruncher van ontwikkelaar Alexander Yee voor het berekenen van pi. Dat programma kan overweg met eigenschappen van moderne processors en is ook voor eerdere wereldrecordpogingen gebruikt. De Zwitsers gebruikten Ubuntu 20.04 en maakten diverse aanpassingen om de berekening van pi te versnellen. Zo werden beveiligingsfuncties en stroombesparingsfuncties uitgeschakeld.
Het doel van de onderzoekers en studenten van de Zwitserse hogeschool was om te laten zien dat ze met een beperkt budget, relatief eenvoudige hardware en een klein team het irrationale getal pi kunnen berekenen tot een recordaantal decimalen. Na 108 dagen en 9 uur kwam het team tot 62,8 biljoen cijfers achter de komma. Dat is 12,8 biljoen meer dan het vorige record.
:strip_exif()/i/2004539710.jpeg?f=imagegallery)
/i/2004539706.png?f=imagegallery)
:strip_exif()/i/2004539708.jpeg?f=imagegallery)
Afbeeldingen: Fachhochschule Graubünden
Naar eigen zeggen was de berekening van de Zwitserse hogeschool bijna twee keer zo snel als die van Google in 2019 en zo'n 3,5 keer sneller dan het laatst geregistreerde wereldrecord uit 2020. De onderzoekers zijn in afwachting van een bevestiging van het Guinness Book of Records. Als die binnen is, publiceren ze het volledige getal. Vooralsnog geven ze alleen de laatste tien cijfers van de uitkomst: 7817924264.
In het Guinness Book of Records staat de meest nauwkeurige berekening van pi momenteel nog op naam van de Amerikaan Timothy Mullican. Hij kwam begin 2020 na acht maanden tot 50 biljoen cijfers achter de komma. Hij gebruikte daarvoor een server met vier Intel Xeon E7-4880v2-cpu's, met 15 cores en 30 threads per stuk. Mullican verbrak met zijn poging het record van Google, dat in 2019 werd gevestigd door een medewerker van Google Cloud. Emma Haruka Iwao rekende op de datacenterhardware van Google pi uit tot 31,4 biljoen cijfers achter de komma. Daarvoor werd een instance met 96 Intel Skylake-cores gebruikt.

:fill(white):strip_exif()/i/2003019984.jpeg?f=thumbmedium)
:strip_exif()/i/2008062479.jpeg?f=fpa)
:strip_exif()/i/2006876144.jpeg?f=fpa)
:fill(black):strip_exif()/i/2000587763.jpeg?f=fpa)
/i/1220875234.png?f=fpa)
/i/2001439531.png?f=fpa)
/i/1281018219.png?f=fpa)
/u/683857/crop61570824d91bb.png?f=community)
/u/344640/crop5f2438e65f2fb_cropped.png?f=community)
:strip_icc():strip_exif()/u/138191/crop60dc7bf60f619_cropped.jpg?f=community)
:strip_icc():strip_exif()/u/20383/crop57de62db41c81.jpeg?f=community)
/u/741353/crop56d8016c31e07_cropped.png?f=community)
/u/103752/crop64db1cb2d56ce_cropped.png?f=community)
/u/176086/crop5f0823fa5e8d6_cropped.png?f=community)
:strip_icc():strip_exif()/u/85393/giant60x60.jpg?f=community)
:strip_exif()/u/67404/C64.gif?f=community)
:strip_icc():strip_exif()/u/136442/crop6198f3130240d.jpg?f=community)
:strip_icc():strip_exif()/u/294301/crop57601646bd092.jpeg?f=community)
/u/27299/hoofd.png?f=community)
/u/577079/crop56168fac8e119_cropped.png?f=community)
:strip_icc():strip_exif()/u/307279/60x60.jpg?f=community)
:strip_icc():strip_exif()/u/430617/crop601acfe4153b3_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/655152/crop605df075b5cea_cropped.jpg?f=community)
:strip_exif()/u/57661/icp4.gif?f=community)
/u/381607/have%2520a%2520nice%2520day%2520-%2520small.png?f=community)
/u/239221/crop5db17928dbd60_cropped.png?f=community)
:strip_icc():strip_exif()/u/361253/8c7870cbb9ccfe37b1f0b796a7a93c23.jpeg?f=community)
/u/51800/Porsche.png?f=community)
:strip_exif()/u/174875/crop5a47567761dca_cropped.gif?f=community)
/u/8/oog3.png?f=community)
:strip_exif()/u/26289/ahxp68H.gif?f=community)
/u/374193/M12VD.png?f=community)
:strip_icc():strip_exif()/u/72765/home60.jpg?f=community)
:strip_exif()/u/106680/LOY_kleinerder.gif?f=community)
:strip_icc():strip_exif()/u/630253/4b8001781ceab258b7bf40f76426913e.jpeg?f=community)
:strip_icc():strip_exif()/u/177567/crop5f8591cadf088_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/41502/breezah.jpg?f=community)