
Als alles volgens plan verloopt, trekt SURF op 1 september de stekker uit Cartesius. Het high performance computing-systeem heeft er dan meer dan acht jaar trouwe rekendienst opzitten als de nationale supercomputer van Nederland. In die hoedanigheid konden wetenschappers op Cartesius vertrouwen voor complex rekenwerk dat ze voor hun onderzoek moesten verrichten. Daarvoor kunnen ze vanaf 1 september nog steeds terecht bij de nationale supercomputer, maar die titel wordt dan gedragen door een geheel ander systeem. Dat systeem heeft de naam Snellius gekregen en wordt in opdracht van SURF door Lenovo gebouwd.
:fill(white):strip_exif()/i/2004338964.jpeg?f=imagemedium) De naam Snellius komt van Willebrord Snel van Royen, een vooraanstaand wiskundige die leefde van 1580 tot 1626. Zoals veel wetenschappers uit die tijd was hij ook thuis in andere onderzoeksgebieden, waaronder landmeetkunde, navigatie, hydrografie en astronomie. Zijn grootste bekendheid kreeg hij op het gebied van optica, met de naar zijn Latijnse naam genoemde wet van Snellius, die aangeeft hoe lichtstralen worden gebroken op de overgang van het ene naar het andere medium. In Frankrijk spreken ze overigens van de wet van Descartes, die de brekingswet onafhankelijk van Snellius beschreef. De Latijnse naam van Descartes is dan weer Cartesius, de naam van de voorgaande nationale supercomputer. Dat alles staat los van de keuze van de naam Snellius; die is mede gekozen vanwege de associatie met 'snel'.
De naam Snellius komt van Willebrord Snel van Royen, een vooraanstaand wiskundige die leefde van 1580 tot 1626. Zoals veel wetenschappers uit die tijd was hij ook thuis in andere onderzoeksgebieden, waaronder landmeetkunde, navigatie, hydrografie en astronomie. Zijn grootste bekendheid kreeg hij op het gebied van optica, met de naar zijn Latijnse naam genoemde wet van Snellius, die aangeeft hoe lichtstralen worden gebroken op de overgang van het ene naar het andere medium. In Frankrijk spreken ze overigens van de wet van Descartes, die de brekingswet onafhankelijk van Snellius beschreef. De Latijnse naam van Descartes is dan weer Cartesius, de naam van de voorgaande nationale supercomputer. Dat alles staat los van de keuze van de naam Snellius; die is mede gekozen vanwege de associatie met 'snel'.
Want snel moet de nieuwe supercomputer worden. SURF streeft naar een initiële pieksnelheid van 6,1 petaflops, met hogere pieksnelheden in de jaren erna door uitbreidingen. Daarmee moet de nationale supercomputer weer in de pas lopen met de overige supercomputers in de wereld. De vijfhonderd krachtigste systemen ter wereld bemachtigen een plek in de Top500-lijst, maar een notering in die prestigieuze lijst is ook weer geen doel van SURF, vertelt Walter Lioen, domain manager research services bij SURF. "De huidige lijstaanvoerder is de Japanse Fugaku met 537 petaflops pieksnelheid, meer dan twintig keer zo krachtig als Snellius uiteindelijk zal zijn, maar die kost ook zo'n 800 miljoen euro. Wij hadden maar 20 miljoen euro. We richten ons veel meer op bruikbaarheid voor de wetenschappers."
/i/2004340074.png?f=imagearticlefull)
Waarom Lenovo?
Om met een actuele kwestie te beginnen: de VS heeft diverse Chinese supercomputerfabrikanten op de zwarte lijst gezet en Lenovo is een Chinees bedrijf. Heeft SURF geopolitieke ontwikkelingen meegewogen in de beslissing welk bedrijf het in de arm zou nemen voor het systeem?
Lioen: "Natuurlijk, dit gaat niet langs ons heen. We hebben voor de aanbesteding een prekwalificatie gedaan en op dat moment bleek dat Lenovo zich zou kunnen inschrijven als kandidaat en niet als enige Chinese leverancier. "In overleg met de overheid is beoordeeld of er reden was om Chinese bedrijven bij voorbaat uit te sluiten; die is er niet"
In overleg met de overheid is beoordeeld of er reden was om Chinese bedrijven bij voorbaat uit te sluiten; die is er niet. Dat betekent niet dat we naïef zijn. Het borgen van veiligheid staat altijd hoog op de agenda, dus ook nu. Als je echter kijkt naar de Top500, is Lenovo een van de grootste leveranciers. Het is een Chinees bedrijf, maar ook aan de beurs genoteerd. Het moet aan alle toezichthouders verantwoording afleggen. Iedereen kent het verhaal van de IBM ThinkPad; dat is een Lenovo ThinkPad geworden. Op een vergelijkbare manier is de HPC-tak van Lenovo ontstaan uit de op Intel gebaseerde HPC-tak van IBM. We krijgen nu ook de Lenovo ThinkSystems. De mensen waarmee we praten, zijn oud-IBM’ers en die kennen we ook in die hoedanigheid. Verder is Lenovo nergens uitgesloten bij aanbestedingen. Het mag tot op de dag van vandaag leveren aan Defensie van de VS."
SURF streefde bij de keuze voor het systeem vooral naar de meeste waar voor zijn geld, dus hoeveel onderzoek het kan faciliteren met de supercomputer, maar ook maatschappelijk ondernemen speelde een rol. Lioen: "We hebben niet alleen naar snelheid gekeken, maar ook naar energiegebruik. Daarbij meet je niet de time-to-solution, maar de energy-to-solution, dus hoeveel kWh kost het om bepaalde sommetjes te doen." Om de prestaties en het verbruik te voorspellen en beloften van leveranciers te analyseren, gebruikt de organisatie de SURF Application Benchmark Suite 2020. Daarin heeft ze de acht meestgebruikte codes opgenomen die wetenschappers op Cartesius draaiden. Die vertegenwoordigen tezamen 45 procent van het gebruik van dat cluster. Verder zijn benchmarks voor gpu, big data en machinelearning toegevoegd om een zo breed mogelijk beeld te krijgen hoe de komende nationale supercomputer zou kunnen presteren bij komend gebruik door Nederlandse wetenschappers. "Daarnaast speelde een belangrijke rol hoe de potentiële leveranciers omgaan met het gebruik van grondstoffen, verpakkingsmaterialen, afvoer van e-waste en de hele supplychain, dat er geen kinderarbeid aan te pas komt bijvoorbeeld", vertelt Lioen.
De keuze viel uiteindelijk op Lenovo, omdat dit bedrijf veel meer nodes voor het bedrag bood dan concurrerende bedrijven. Dat betreft de tweede en derde fase van de bouw van Snellius, die in respectievelijk 2022 en 2023 afgerond moeten worden. Daarnaast scoorde Lenovo volgens Lioen ook het best op het gebied van social responsibility. Op 1 februari van dit jaar werd daarop het definitieve contract getekend en het Chinese bedrijf mag daarmee aan de slag met de bouw van de nieuwe generatie nationale supercomputer.
:strip_exif()/i/2001026879.jpeg?f=imagearticlefull)
Exit Cartesius
Na jarenlange trouwe dienst wordt daarmee na de zomer niet alleen de stekker uit Cartesius getrokken, maar wordt het hele cluster van Atos Bull ontmanteld. Cartesius werd begin 2013 in elkaar gezet en de laatste uitbreiding dateert van eind 2016. SURF zal de onderdelen wel zoveel mogelijk recyclen en hergebruiken. Hoewel het systeem misschien niet meer met de snelste meekan, kan Cartesius natuurlijk nog steeds een flink potje rekenen. Waarom laat SURF het systeem niet gewoon doordraaien?
Lioen: "Dat is niet rendabel. Bij vervanging krijgen we meer rekenkracht, ergens tussen een factor acht en twaalf, en de energie die dat kost, neemt wel wat toe, maar dan heb je het hooguit over een factor anderhalf. Je energie-efficiëntie groeit eigenlijk mee met de wet van Moore." Als de eerste fase van de bouw is afgerond, trekt Snellius zelfs minder vermogen dan Cartesius, 620kW versus 884kW, terwijl de piekprestatie 3,4 keer zo hoog ligt. Lioen: "In de praktijk zie je dat de systemen 70 tot 85 procent van die hoeveelheden kW verbruiken. Deze waardes zie je alleen als ze bijvoorbeeld de Linpack-benchmark voor hpc draaien, zoals ook gebruikt voor de Top500."
| SURFsara nationale supercomputers | ||||
|---|---|---|---|---|
| Jaar | Systeem | RPeak Gflops | kW | Gflops/kW |
| 1984 | CDC Cyber205-611 | 0,1 | 250 | 0,0004 |
| 1988 | CDC Cyber205-642 | 0,2 | 250 | 0,0008 |
| 1991 | CrayY-MP4/464 | 1,33 | 200 | 0,0067 |
| 1994 | Elsa: Cray C98/4256 | 4 | 300 | 0,0133 |
| 1997 | Elsa: CrayC916/121024 | 12 | 500 | 0,024 |
| 2000 | Teras: SGI Origin 3800 | 1024 | 300 | 3,4 |
| 2004 | Teras + Aster: SGI Origin 3800 +SGI Altix 3700 | 3200 | 500 | 6,4 |
| 2007 | Huygens: IBM p575 Power5+ | 14.592 | 375 | 39 |
| 2008 | Huygens: IBM p575 Power6 | 62.566 | 540 | 116 |
| 2009 | Huygens: IBM p575 Power6 | 64.973 | 560 | 116 |
| 2013 | Cartesius: Bull bullx B710 + R428 E3 | 270.950 | 245 | 1106 |
| 2014 | Cartesius: + Bull bullx B515 (Nvidia K40m) | 480.883 | 289 | 1662 |
| 2014 | Cartesius: + Bull bullx (+B720) | 1.559.155 | 791 | 1971 |
| 2016 | Cartesius: + Bull sequana X1110 + X1210 | 1.843.140 | 884 | 2085 |
| 2021 | Snellius: Lenovo ThinkSystem SR/SD | 6.100.000 | 620 | 9839 |
| 2022 | Snellius: + Lenovo ThinkSystem ? | 11.200.000 | 1200 | 9333 |
| 2023 | Snellius: + Lenovo ThinkSystem ? | max. 21.500.000 | max. 1430 | max. 15.035 |
De verschillende nationale supercomputers door de jaren heen
Lioen wijst op de exponentiële toename van rekenkracht versus de relatief geringe toename van het energiegebruik. "Als je dan kijkt naar hoeveel rekenbewerkingen je per seconde kunt doen per kW, dan zie je ook een exponentiële groei." Om de zoveel jaar een nieuw systeem voor hetzelfde budget aanschaffen, zou dan ook efficiënter zijn dan een verouderd systeem laten draaien. "De ordegrootte van de budgetten blijft gelijk; de vloeroppervlakte blijft gelijk. Tegenwoordig zijn het op racks gebaseerde systemen dus dat blijft gelijk, maar je rekenkracht groeit exponentieel."
Snellius en Cartesius komen in de zomer even naast elkaar te staan, in de Amsterdam Data Tower van Digital Realty op het Amsterdam Science Park. Op de vloer was nog plek doordat op de zaal van Cartesius maximaal 1MW geleverd kon worden. Lioen: "Dat was de beperkende factor voor uitbreiding, dus er was vrij veel ruimte over. Inmiddels is Digital Realty bezig met het upgraden van de elektriciteitsvoorziening. We kunnen beide systemen daardoor tegelijk laten werken."
:strip_exif()/i/2003591014.jpeg?f=imagearticlefull)
3 petaflops aan gpu-rekenkracht
SURF zet het systeem gefaseerd neer. Het verschil in rekenkracht dat Snellius tegenover zijn voorganger gaat bieden, is daarmee in eerste instantie nog relatief beperkt: 6,1 versus 1,8 petaflops. Bij de opvolgende fasen neemt de rekenkracht toe, tot maximaal 21,5 petaflops halverwege 2023. Ook Cartesius kende upgrades en volgens Lioen is dat een logische strategie. "Het heeft weinig zin voor ons om op dag één een systeem neer te zetten dat tien keer zo groot is, want dan wordt dat op dag twee voor 10 procent gebruikt. Dat gebruik moet even 'ingroeien'. Als de toename een factor twee tot vier betreft, zien we dat het systeem met een jaar vol gegroeid is, oftewel volledig gebruikt wordt. Als we dat met een factor tien tot twintig doen, duurt het een paar jaar voordat het vol gegroeid is."
| Prestaties | |
|---|---|
| Cartesius | Snellius |
| Fase 1: | |
| 47.776 cores | 76.832 cores (1,6x) |
| 132 gpu's (210 teraflops) | 144 gpu's (3 petaflops, 14x) |
| Totale piekprestatie: 1,8 petaflops | Totale piekprestatie: 6,1 petaflops (3,4x) |
| Fase 1 + 2 samen: | |
| Totale piekprestatie: 11,2 petaflops (6,2x) | |
| Volledig systeem inclusief Fase 3-uitbreiding: | |
| Meer dan 200.000 cores ( > 4x) | |
| Totale piekprestatie: 13,6 - 21,5 petaflops (7,6 - 11,9x) | |
Fase 1 bestaat uit cpu-nodes met Lenovo ThinkSystem SR645- en SR665-systemen, en gpu-nodes op basis van de Lenovo ThinkSystem SD650. Alle cpu-nodes bevatten AMD EPYC-processors met 64 cores die hun werk op 2,6GHz doen. Het gaat om 504 nodes met 256GB ram en 72 zogenoemde fat nodes met 1TB werkgeheugen. Deze fat-nodesystemen hebben 6,4TB NVMe-opslag. Verder zijn er vier cpu-nodes met nog meer werkgeheugen: twee met 4TB en twee met 8TB.
Van de gpu-nodes komen er 36 en deze hebben Intel Xeons met Nvidia HGX A100-borden, waarop vier A100-accelerators met 40GB HBM2e geplaatst zijn. De gpu's zijn in een meshnetwerk geplaatst waarbij elke gpu met elke andere gpu kan communiceren. Dat gebeurt via de twaalf NVLink-interconnects per gpu. Elke NVLink biedt 50GB/s bandbreedte voor een totale gpu-naar-gpu-bandbreedte van 600GB/s. Anders dan bij de borden met acht HGX A100-accelerators is er bij de variant met vier gpu's geen NVSwitch aanwezig, wat scheelt in verbruik en kosten.


Lenovo ThinkSystem SR645 (links) en ThinkSystem SD650
"Gpu's die zes jaar oud zijn, die zijn bijna aftands"
Het is niet voor het eerst dat de nationale supercomputer een onderdeel met gpu's krijgt. Huygens had dat nog niet, maar Cartesius had al een gpu-eiland met Tesla K40M-accelerators. Lioen: "Bij Cartesius hebben we gezegd: we zetten een op cpu's gebaseerd systeem neer en als er voldoende vraag is, gaan we daar een kleine partitie gpu's bijzetten. Dat hebben we gedaan en die zien we goed gebruikt worden. Bij Snellius hebben we er bewust voor gekozen om een groter deel van de rekenkracht beschikbaar te stellen in de vorm van gpu's. We gebruiken een vergelijkbare hoeveelheid gpu's als in Cartesius, maar dat waren gpu's uit 2014 die in 2015 operationeel zijn geworden. Gpu's die zes jaar oud zijn, die zijn bijna aftands. Er zitten hier al twee generaties van architecturen tussen. We krijgen straks Nvidia-gpu's die op de Ampere-architectuur gebaseerd zijn. Die zijn met dezelfde hoeveelheid gpu's al veertien keer zo snel."
| Snellius Fase 1 (medio 2021) | |
|---|---|
| Cpu-nodes, piekprestatie: 3,1 petaflops | Gpu-nodes, piekprestatie: 3 petaflops |
| Alle nodes: 2x AMD EPYC 7H12 (Rome) met 64 cores op 2,6GHz | 36x Lenovo ThinkSystem SD650-N V2 met: |
| Thin nodes: 504x Lenovo ThinkSystem SR645, 256GB | 2x Intel Xeon (sku nog niet uitgebracht) |
| Fat nodes: 72x Lenovo ThinkSystem SR645, 1TB, 6,4TB NVMe | 1x Nvidia HGX A100 (4x A100-gpu, 40GB, Ampere) |
| High-memory nodes: 2x Lenovo ThinkSystem SR665, 4TB | 512GB ram |
| High-memory nodes: 2x Lenovo ThinkSystem SR665, 8TB | |
De tweede fase betreft een uitbreiding met alleen cpu-nodes. Het gaat halverwege 2022 dan om systemen met EPYC-processors van een generatie die AMD nog niet heeft aangekondigd. Hoe fase drie ingevuld wordt, moet nog besloten worden. Lioen: "We bekijken hoe het gebruik van de gpu's zich ontwikkeld. Als dat heel erg aantrekt, willen we gpu's gaan neerzetten. Als dat achter zou blijven, gaan we toch voor cpu-uitbreidingen."
| Snellius Fase 2 (medio 2022) |
|---|
| Uitbreiding met alleen cpu-nodes, thin nodes, totale piekprestatie: 5,1 petaflops. Totale piekprestatie voor Fase 1 en 2 samen: 11,2 petaflops. |
| AMD EPYC-cpu's van toekomstige generatie, 2GB per core |
| Snellius Fase 3 (medio 2023) |
|---|
| Drie keuzes voor uitbreiding (afhankelijk van gebruik/vraag). Totale piekprestatie voor alle fases samen: tussen 13,6 en 21,5 petaflops. |
| 1. Cpu-nodes, AMD EPYC-cpu's van toekomstige generatie, 2,4 petaflops |
| 2. Gpu-nodes, Nvidia-gpu's van toekomstige generatie, 10,3 petaflops |
| 3. Nog te bepalen hoeveelheid opslag |
Volgens de SURF-medewerker is het gebruik van gpu's voor wetenschappelijk rekenwerk niet triviaal. "Je moet er veelal compleet nieuwe implementaties van je software voor maken. Als je het over bekende grote pakketten hebt waar wetenschappers mee rekenen, bijvoorbeeld die voor quantumchemische berekeningen, dan heb je het over pakketten van honderdduizenden tot een miljoen regels code. Als je rekenwerk wilt offloaden naar de gpu, dan pak je de rekenintensieve delen. De wet van Amdahl beschrijft dat als je 90 procent kunt optimaliseren voor gpu's, de maximale winst een factor tien betreft. Als je heel groot wilt opschalen, is dat iets wat je tegenhoudt."
Ook bij supercomputers is de trend zichtbaar dat Arm en fpga's in opkomst zijn. SURF kiest hier vooralsnog niet voor. "Arm en fpga's zijn hartstikke relevant, maar als je naar de Top500 kijkt, zie je dat de meeste systemen, zo'n 70 procent, op cpu's gebaseerd zijn. Wat op accelerators gebaseerde systemen betreft, zeven van de top tien, gaat het meestal om gpu's. Er is een aantal systemen met custom accelerators, met name in Azië. De Japanse Fugaku heeft inderdaad Arm-chips, maar met speciaal ontworpen vectorinstructies, vergelijkbaar met de AVX-instructies die Intel-cpu's hebben."
Van 14 naar 800Gbit/s?
Niet alleen op het gebied van cpu's en gpu's maakt de nationale supercomputer een sprong voorwaarts, maar ook met de interconnect, de verbindingen tussen de verschillende nodes. Cartesius-nodes beschikten bij hun ingebruikname over Mellanox Infiniband FDR, met een bandbreedte van 56Gbit/s, opgebouwd uit vier kanalen van 14Gbit/s. Een latere uitbreiding markeerde de stap naar EDR, met 100Gbit/s. De cpu-nodes van Snellius gaan over HDR100 beschikken, met bidirectioneel 100Gbit/s met lage latency. De gpu-nodes krijgen twee keer HDR voor een totale bandbreedte van 400Gbit/s. Bij fase drie zal twee keer NDR voor 800Gbit/s worden gebruikt, als de keuze op uitbreiding met gpu-nodes valt.
Zover is het nog niet. Eerst treffen SURF, Digital Realty en Lenovo de voorbereidingen voor de komst van het nieuwe cluster. In juli moet het systeem opgebouwd zijn en de eerste acceptancetests kunnen draaien. Daarbij wordt gekeken of alles geleverd is, of de kabels correct zijn aangesloten en of de hardware zich gedraagt zoals verwacht. SURF draait daarbij zijn benchmarksuite en een burntest waarbij het systeem een aantal dagen achter elkaar draait. "Een mooie test is het uit- en weer aanzetten", grinnikt Lioen. "Je kunt je voorstellen dat er veel configuratiewerk zit in zo'n complex systeem met tal van subsystemen." In augustus vinden dan het verdere configuratiewerk en de datamigratie plaats, zodat Snellius later die maand aan het werk gezet kan worden.
/i/2004339840.png?f=imagenormal)
Kuchjes simuleren bij covid-19-onderzoek
Waar de nationale supercomputer dan zoal voor ingezet wordt, vertelde prof.dr. Dethlef Lohse, natuurkundige aan de Universiteit Twente, onlangs tijdens de SURF Research Week. Hij is verbonden aan de Physics of Fluids-groep van de universiteit. Inzichten in fluid dynamics zijn van groot belang voor onder andere klimaat-, energietransitie-, gezondheids- en hightechonderzoek, maar het beschrijven van het gedrag van vloeistoffen en gassen is bijzonder complex. Lohse: "We leven dankzij de vorderingen van high performance computing in de gouden eeuw van fluid dynamics. Rekenclusters hebben het vakgebied met sprongen vooruitgeholpen."
Hij gaf als voorbeeld onderzoek naar aerosolen vanwege covid-19. Dankzij de inzet van Cartesius wist zijn onderzoeksgroep vorig jaar het gedrag van druppels in kaart te brengen bij spreken en kuchen. Daarbij konden verschillende factoren meegewogen worden, zoals de grootte van druppels, de temperatuur en de relatieve vochtigheid bij uitwaseming. De simulaties toonden dat bij een temperatuur van 10 graden Celsius druppels aanvankelijk groeien na uitwaseming en langer in stand blijven. Door oversaturatie is er sprake van hoge relatieve luchtvochtigheid bij het uitstoten van de lucht en de vochtige wolk blijft daardoor langer in de lucht dan vooraf gedacht. Druppels nemen bij 30 graden Celsius snel in omvang af en verdwijnen vanwege verdamping. De afstand van 1,5 meter die nu aangehouden wordt als veilig, is afgeleid van onderzoek uit 1936 van William F. Wells naar tuberculose. Het onderzoek van Lohse concludeert dat die afstand niet voldoende is voor social distancing en dat de levensduur van kleine druppels veel langer is dan Wells voorspelde.

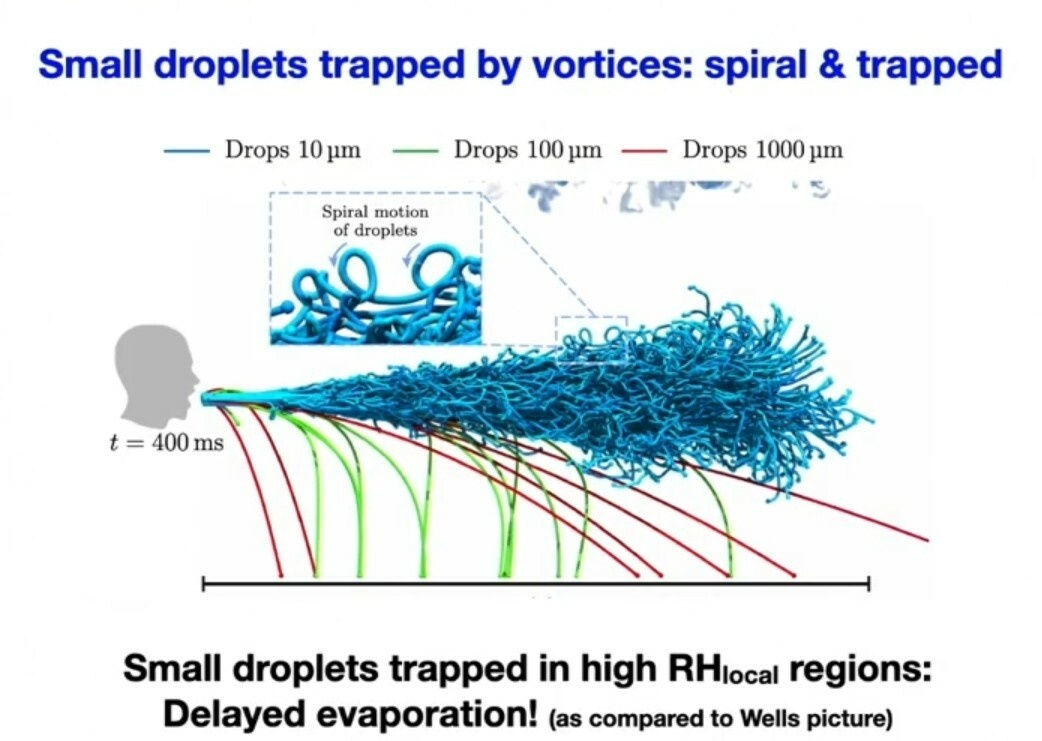

Het rekenproject dat Lohse door Cartesius liet uitvoeren, is een van de rekenprojecten die vorig jaar betrekking hadden op onderzoek naar covid-19. SURF en NWO besloten eind maart vorig jaar om dit soort onderzoeken voorrang te geven. De organisaties beloofden wetenschappers om binnen drie dagen uitsluitsel te geven bij aanvragen om de supercomputer voor covid-19-rekenwerk in te zetten. Normaal gesproken duurt deze procedure bij omvangrijke voorstellen vier tot zes weken. Cartesius was mede hierdoor goed volgeboekt. Die flexibele inzet toonde het voordeel aan van het hebben van een nationale supercomputer, geoptimaliseerd voor gebruik door zoveel mogelijk wetenschappers. Snellius moet straks verder inspelen op de almaar stijgende behoefte aan meer rekenkracht, om zo onderzoek mogelijk te maken dat nu nog buiten het bereik van veel wetenschappers ligt.
:strip_icc():strip_exif()/i/2001340241.jpeg?f=fpa_thumb)
:strip_icc():strip_exif()/i/2001028793.jpeg?f=fpa_thumb)
:strip_exif()/i/2005344592.jpeg?f=fpa)
:strip_exif()/i/2004334262.jpeg?f=fpa)
/i/2004636488.png?f=fpa)
/u/40481/crop63f777c898038_cropped.png?f=community)
:strip_icc():strip_exif()/u/427532/crop62650f4b0566a_cropped.jpg?f=community)
:strip_icc():strip_exif()/u/57960/crop66d9728fd8521_cropped.jpg?f=community)
:strip_exif()/u/41019/aim_mine_ani.gif?f=community)
:strip_icc():strip_exif()/u/79614/Family-Guy-Victory-is-Ours.jpg?f=community)
:strip_icc():strip_exif()/u/137578/crop684839b85b72a.jpg?f=community)
:strip_icc():strip_exif()/u/664938/twava1_60.jpg?f=community)
/u/253895/crop5fddbb24425ea_cropped.png?f=community)
:strip_icc():strip_exif()/u/14944/ist_hdr11.jpg?f=community)
:strip_exif()/u/1359832/crop5fcfdc0ba0f2b_cropped.gif?f=community)
/u/1503/crop601859cd0da3c_cropped.png?f=community)
:strip_exif()/u/16366/NeXTLogo-av.gif?f=community)
:strip_icc():strip_exif()/u/52144/thunderdome.jpg?f=community)
:strip_icc():strip_exif()/u/172905/crop59a5561d63c7d.jpeg?f=community)
/u/246423/crop5979eb9e5c60f_cropped.png?f=community)
/u/541877/Profielfoto%2520Tweakers.png?f=community)
:strip_icc():strip_exif()/u/549548/crop5f71a5df02179_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/303210/favritegotevj9.jpg?f=community)
/u/3041/crop651a776a4ad9f_cropped.png?f=community)
:strip_exif()/u/32998/tweakpiggy_anim.gif?f=community)
:strip_icc():strip_exif()/u/337114/crop5fabf93808914.jpeg?f=community)