Drie onderzoekers van de Stanford Universiteit hebben manieren gevonden om captcha's, die onder meer spambots moeten tegengaan, te kraken. De beveiliging van grote sites als eBay en Wikipedia blijkt er makkelijk mee te passeren.
Een captcha toont een aantal letters en cijfers die dusdanig zijn verhaspeld dat ze wel door mensen, maar niet door computers kunnen worden gelezen. Dat zou het voor spambots onmogelijk maken om geautomatiseerd accounts te registreren; registratieformuleren op veel websites maken gebruik van captcha's.
Met het Decaptcha-project zijn onderzoekers van de Stanford Universiteit erin geslaagd manieren te ontwikkelen om de automatische websitebeveiliging te kraken. Het programma verwijdert de zichtbare 'ruis' in de afbeeldingen, zet de letters om in platte tekst en maakt de captcha's voor computers leesbaar. Dit gebeurt in een fractie van een seconde, staat in het onderzoek.
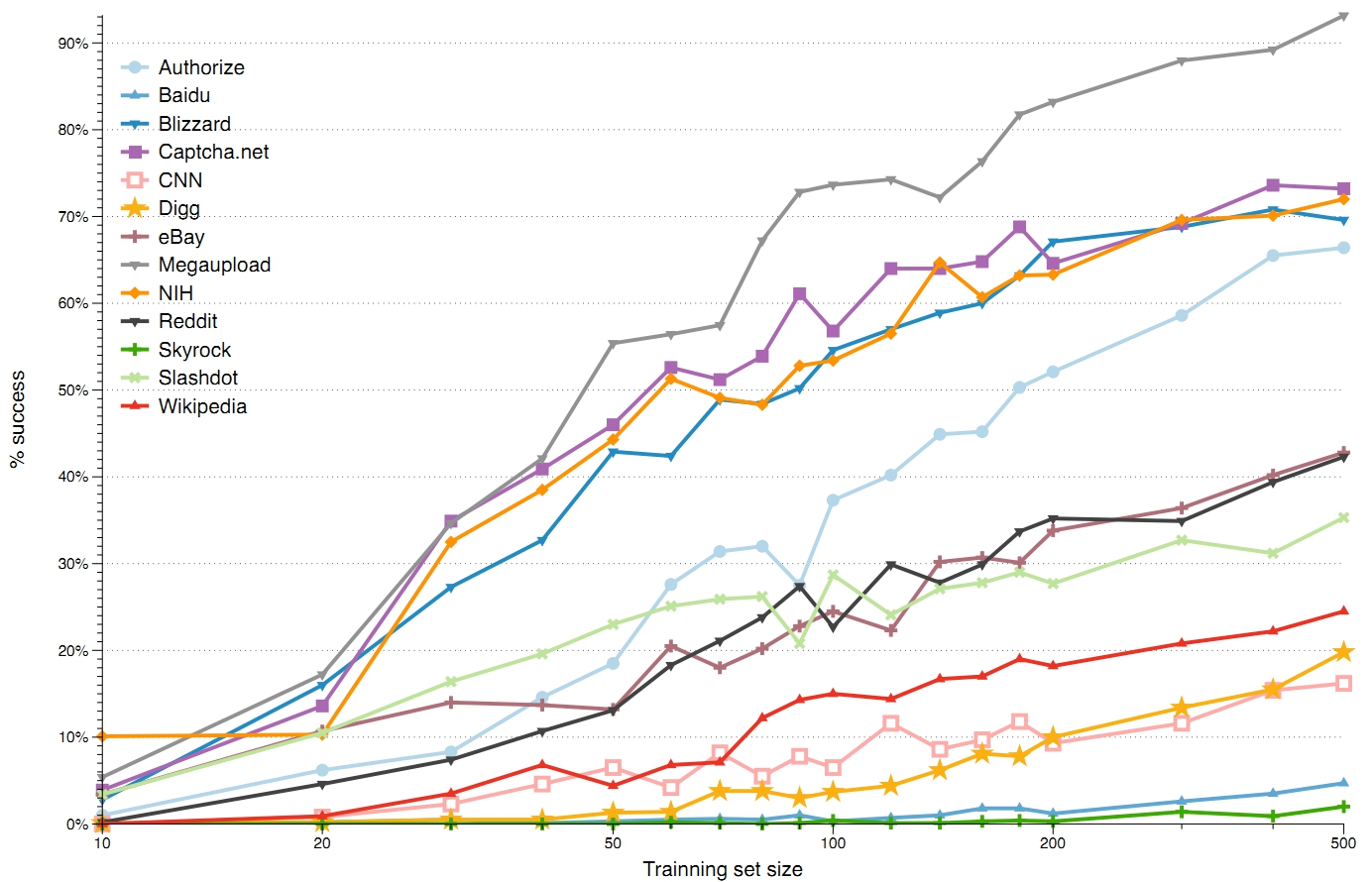
De onderzoekers probeerden hun software uit op verschillende grote sites, met diverse soorten captcha's. Grote sites als eBay, Wikipedia, CNN, Baidu, Digg en Visa's Authorize.net bleken te omzeilen. Van de vijftien geteste captcha's bleven alleen die van Google en Recaptcha redelijk buiten de gevarenzone. Hun captcha's konden onder andere minder vaak gekraakt worden omdat de gebruikte methodes het moeilijker maakten het aantal en de gemiddelde grootte van de tekens te bepalen.
Eerder toonden de Stanford-informatici al kwetsbaarheden in audio-captcha's aan. Die lagen aan de manier waarop de software werkt; de cijfers en letters uit de captcha's die in de audiofragmenten hoorbaar zijn, vormen pieken in een spectrumanalyse. Die pieken worden van ruis gescheiden, maar bij spraak als storende component werkt dat niet. Audio-captcha's worden gebruikt om slechtzienden te helpen bij het oplossen van een captcha.


:strip_exif()/i/1253172424.gif?f=fpa)
/i/2000658159.png?f=fpa)
:strip_exif()/i/1324372204.gif?f=fpa)
/i/1262428448.png?f=fpa)
/i/1240135325.png?f=fpa)

:strip_icc():strip_exif()/u/365070/Untitled.jpg?f=community)
:strip_icc():strip_exif()/u/64465/crop5db09addab56c_cropped.jpeg?f=community)
:strip_exif()/u/16879/brant.gif?f=community)
/u/305595/Space__by_MeckanicalMind.png?f=community)
:strip_icc():strip_exif()/u/174665/crop5f3505845c31b_cropped.jpeg?f=community)
/u/155568/usericon.png?f=community)
:strip_icc():strip_exif()/u/57655/SuperTeamLogo.jpg?f=community)
/u/85941/crop61dd9b39bb021_cropped.png?f=community)
/u/7928/ava-misc-dp0.png?f=community)
:strip_icc():strip_exif()/u/23965/crop5e6625671ade4.jpeg?f=community)
:strip_icc():strip_exif()/u/249917/jaapschaap.jpg?f=community)
:strip_icc():strip_exif()/u/360698/and5.jpg?f=community)