Het domein DrunkMenWorkHere.org is het afgelopen jaar geheel gewijd geweest aan het onderzoeken van zoekmachines. Op het domein was een site geplaatst van liefst 2.147.483.647 pagina's, die in een binaire-boomstructuur aan elkaar geknoopt waren. Door een jaar lang het gedrag van de bots van Google, Yahoo en MSN op deze site te bestuderen, hebben de Drunk Men geprobeerd om de methodes waarvan zoekmachines zich bedienen om een site in kaart te brengen, wat beter inzichtelijk te maken. En passant werd ook nog even gekeken welke andere robots de pagina's bezochten, en met een invulveldje werden zulke bots uitgenodigd om een opmerking achter te laten. Het bleek dat ruim de helft van de bots die automatisch teksten op de site achterlieten, reclame maakte voor geneesmiddelen.
 Van de 231 aanwezige pagina's werden er door Yahoo's Slurp-bot meer dan honderdduizend opgevraagd, wat nog steeds niet meer dan een schamele 0,0049% van het totale aantal pagina's was. De Googlebot bleek benieuwd naar 7556 verschillende pagina's, terwijl de zoekmachine van Microsoft het na 1390 pagina's voor gezien hield. MSN Search rapporteerde dan ook niet meer dan één enkele pagina, terwijl Google beweerde 554 pagina's te hebben ontdekt, wat neerkomt op ruim zeven procent van de gespiderde pagina's. Yahoo deed zozeer zijn best om alle gevonden materiaal te laten zien, dat het zelfs meer gevonden pagina's rapporteerde dan het in feite had bekeken, maar dat ligt eerder aan een erg optimistische afronding dan aan moedwillige fraude.
Van de 231 aanwezige pagina's werden er door Yahoo's Slurp-bot meer dan honderdduizend opgevraagd, wat nog steeds niet meer dan een schamele 0,0049% van het totale aantal pagina's was. De Googlebot bleek benieuwd naar 7556 verschillende pagina's, terwijl de zoekmachine van Microsoft het na 1390 pagina's voor gezien hield. MSN Search rapporteerde dan ook niet meer dan één enkele pagina, terwijl Google beweerde 554 pagina's te hebben ontdekt, wat neerkomt op ruim zeven procent van de gespiderde pagina's. Yahoo deed zozeer zijn best om alle gevonden materiaal te laten zien, dat het zelfs meer gevonden pagina's rapporteerde dan het in feite had bekeken, maar dat ligt eerder aan een erg optimistische afronding dan aan moedwillige fraude.
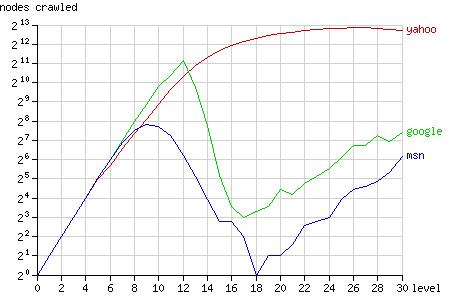
 De binaire-boomconstructie maakte het verder mogelijk om vast te stellen hoe lang de spiders linkjes bleven volgen. Elke pagina van de testsite verwees naar twee 'dieper' gelegen pagina's, en tot vijf linkjes diep wist elke zoekmachine elke pagina te vinden. Google bleef het langst volledig: hun engine indexeerde alle pagina's tot het tiende niveau. Zowel MSN als Google lieten het daarna flink afweten, terwijl Yahoo pas na 27 van de 31 niveaus iets van zijn belangstelling verloor. Ook het aantal opgevraagde pagina's werd onderzocht, en weer bleek Yahoo het vasthoudendst: elke pagina die werd gespiderd, werd gedurende het jaar rond de tien keer opgevraagd, terwijl Google en MSN elk op ongeveer drie pageviews per gevonden pagina bleven steken. Voor een volledig verslag van alle bevindingen hebben we deze keer écht geen ruimte, want elk van de 2.147.483.647 pagina's bevat een grafische weergave van het gedrag van de zoekmachines vanaf die pagina. Voor wie graag met grafiekjes, statistieken en natuurlijk zoekmachines bezig is, is een bezoekje aan de site dan ook verplichte kost.
De binaire-boomconstructie maakte het verder mogelijk om vast te stellen hoe lang de spiders linkjes bleven volgen. Elke pagina van de testsite verwees naar twee 'dieper' gelegen pagina's, en tot vijf linkjes diep wist elke zoekmachine elke pagina te vinden. Google bleef het langst volledig: hun engine indexeerde alle pagina's tot het tiende niveau. Zowel MSN als Google lieten het daarna flink afweten, terwijl Yahoo pas na 27 van de 31 niveaus iets van zijn belangstelling verloor. Ook het aantal opgevraagde pagina's werd onderzocht, en weer bleek Yahoo het vasthoudendst: elke pagina die werd gespiderd, werd gedurende het jaar rond de tien keer opgevraagd, terwijl Google en MSN elk op ongeveer drie pageviews per gevonden pagina bleven steken. Voor een volledig verslag van alle bevindingen hebben we deze keer écht geen ruimte, want elk van de 2.147.483.647 pagina's bevat een grafische weergave van het gedrag van de zoekmachines vanaf die pagina. Voor wie graag met grafiekjes, statistieken en natuurlijk zoekmachines bezig is, is een bezoekje aan de site dan ook verplichte kost.


:strip_exif()/u/29711/tweakers.gif?f=community)
:strip_exif()/u/9179/crop586dff9d475a6_cropped.gif?f=community)
:strip_icc():strip_exif()/u/12925/darlingtonia.jpg?f=community)
:strip_icc():strip_exif()/u/17296/palawanmini.jpg?f=community)
:strip_icc():strip_exif()/u/81611/headcrop.jpg?f=community)
:strip_icc():strip_exif()/u/78725/train-icon3.jpg?f=community)
:strip_exif()/u/19341/billencaptains60x60.gif?f=community)
/u/154493/Moderat_ii.png?f=community)
{kind=link}