Google heeft het Gemini 2.5 Computer Use-model als preview via de api beschikbaar gemaakt. Het model gebruikt de 'visuele begrips- en redeneringsmogelijkheden' van Gemini 2.5 Pro om te kunnen communiceren met gebruiksinterfaces, waaronder browsers.
Google schrijft dat AI-modellen vaak via api's met software kunnen communiceren, maar dat veel digitale taken nog altijd directe interactie met de gebruikersinterface vereisen, zoals het invullen en versturen van formulieren. Voor dit soort taken moeten agents net als mensen door webpagina's en applicaties navigeren, onder andere door te klikken, te typen en te scrollen.
De invoer voor de tool bestaat uit de gebruikersaanvraag, een schermafbeelding van de omgeving en een geschiedenis van recente acties. Het model analyseert de invoer en genereert daarop een respons, zoals klikken of typen. Voor bepaalde acties, zoals het doen van een aankoop, is bevestiging van de gebruiker nodig. De clientsidecode voert de ontvangen actie daarna uit.
Volgens Google presteert het model in meerdere benchmarks beter dan alternatieven, zoals Claude Sonnet en het agentmodel van OpenAI. Gemini 2.5 Computer Use zou onder andere hogere scores halen in Online-Mind2Web, WebVoyager en AndroidWorld.
Tekst gaat verder onder de afbeelding
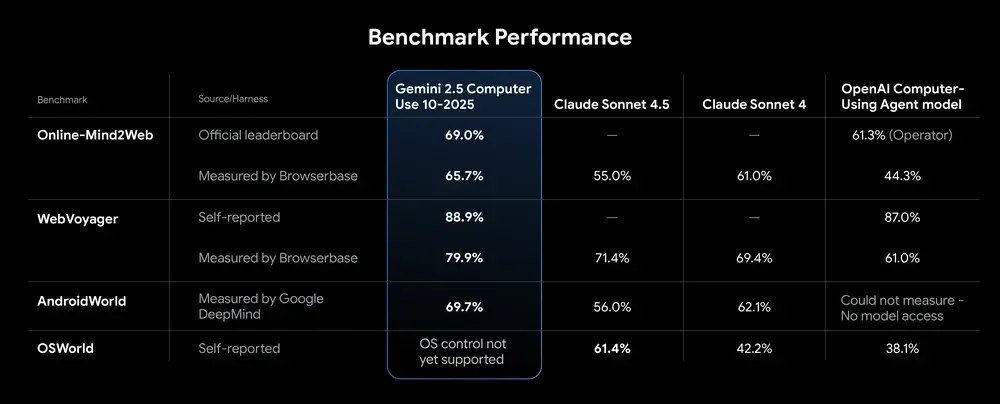
Ontwikkelaars hebben toegang tot het Computer Use-model via de Gemini-api in Google AI Studio en Vertex AI. Het model is vooral geoptimaliseerd voor webbrowsers, maar kan ook gebruikt worden voor taken in mobiele gebruiksinterfaces. Het model is nog niet geoptimaliseerd voor gebruik op desktop-OS-niveau.

:strip_exif()/i/2007634368.jpeg?f=fpa)
:strip_exif()/i/2007814810.jpeg?f=fpa)
/i/2004779058.png?f=fpa)
/i/2006784590.png?f=fpa)
/i/2007816560.png?f=fpa)
:strip_exif()/i/2007816468.jpeg?f=fpa)
:strip_exif()/u/601542/crop5776a8f28f717_cropped.gif?f=community)
:strip_exif()/u/915077/crop59dce6a25e42d_cropped.gif?f=community)
:strip_icc():strip_exif()/u/1877032/crop6385d9c9acd97_cropped.jpg?f=community)
:strip_icc():strip_exif()/u/621125/crop65cd0fde312bc_cropped.jpg?f=community)
{kind=link}