wat hier dus niet staat, is dat je een shared disk nodig hebt ( quorum-disk) die kun je via shared scsi ( scsi-hub radial topology ) doen , of via het SAN . je hebt dus pertinent geen 2 storage boxen nodig. 1 is genoeg. verder heb je dus ook een hartbeat nodig , die monitored of de andere node nog op is. ook een active/pasive cluster is mogelijk , waarbij er 1 op standby staat en het overneemt als de hoofd node dood is .
Shared storage op meerdere clusternodes is het belangrijkste concept. Alleen wat als die uitvalt, dan zit je nog met de shit. Uitval van hardware is No 1. Disk, No. 2 power supply.
Beste oplossing is:
Twee of meerdere clusternodes naar redundant FC Switch of AL-hub's. Daarnaast 2 disk array's waarvan 1 primary in raid-5 (misschien meerdere logische volumes en split bus) met hot-spare disks. Daarnaast een tweede raid systeem in identieke configuratie welke een Raid-1 is van de eerste.
Je krijgt dan de volgende configuratie:
Clusternode 1 ---> FC Switch 1 (of FC-AL hub)
Clusternode 2 ---> FC Switch 1 (of FC-AL hub)
Clusternode 1 ---> FC Switch 2 (of FC-AL hub)
Clusternode 2 ---> FC Switch 2 (of FC-AL hub)
Storage 1 ----> FC Switch 1 (of FC-AL hub)
Storage 2 ----> FC Switch 1 (of FC-AL hub)
Storage 1 ----> FC Switch 2 (of FC-AL hub)
Storage 2 ----> FC Switch 2 (of FC-AL hub)
FC Switch 1 ---> FC Switch 2 (E-Port)
Dan primary paden definieeren:
Node 1 ---> Switch 1 ----> Storage 1 port 1
Node 2 ---> Switch 2 ----> Storage 1 port 2
Storage 1 ----> Switch 1 ----> Storage 2
Storage 2 ----> Switch 2 ----> Storage 1
Secundaire paden definieeren:
Node 1 ---> Switch 2 ----> Storage 1 port 2
Node 2 ---> Switch 1 ----> Storage 1 port 1
Storage 1 ----> Switch 2 ----> Storage 2
Storage 2 ----> Switch 1 ----> Storage 1
Wat er ook geschied, het cluster blijft vrij goed in de lucht. Natuurlijk alle systemen met dubbele power supplies, per raid-5 set 1 hotspare disk.
Geen dual channel kaarten gebruiken, maar single channel. Want anders liggen er gelijk 2 verbindingen uit.
Daarnaast iedere server met 2 netwerkkaarten en die in een Cisco switch group hangen en channel bundeling gebruikern (adapter teaming).
Server 1, eth0 ----> Cisco 1 (1 gibi) ] team 1
Server 1, eth1 ----> Cisco 2 (1 gibi) ] team 1
Server 2, eth0 ----> Cisco 2 (1 gibi) ] team 2
Server 2, eth1 ----> Cisco 1 (1 gibi) ] team 2
Cisco's ook met dubbel powersupply uitvoeren.
Daarnaast, power goed verdelen.
Group 1 (fase 1) CN1 SW2 ST1
Group 2 (fase 2) CN2 CIS1 ST2
Group 3 (fase 3) SW1 CIS2 Other
En nog zijn er combinaties van onderdelen welke niet uit mogen vallen. Oplossing, een derde clusternode etc.
Als je geld over hebt kan je het concept uitbreiden. Je doet dan het volgende:
Meerdere raid-5 volumes op storage systeem, een even aantal definieeren. Bijvoorbeeld 4.
Storage 1:volume 1 - mirror (raid 1) --> Storage 2:volume 1
Storage 2:volume 2 - mirror (raid 1) --> Storage 1:volume 2
Storage 1:volume 3 - mirror (raid 1) --> Storage 2:volume 3
Storage 2:volume 4 - mirror (raid 1) --> Storage 1:volume 4
Daarnaast 2 extra FC kaarten in elke server en dan de switchen bypassen.
Node 1 ---> Storage 1
Node 2 ---> Storage 1
Node 1 ---> Storage 2
Node 2 ---> Storage 2
En primary en secundairy paden aanmaken.
Kost wel een hoop PCI sloten. En lots of hardware.
 Op Digit Life is een uitgebreid artikel verschenen over clustering. Het stuk is niet bedoeld als analyse van varianten op verschillende probleemoplossingen maar gaat dieper in op de terminologie en de toepassingsmogelijkheden. Na een korte inleiding over clusters in het algemeen gaat de schrijver dieper in op de verschillen in architectuur. De kenmerken van een cluster zijn afhankelijk van het doel waar het system voor gebruikt gaat worden. De systemen zijn globaal in te delen in drie groepen: High Performance(HP), High Availability (HA) of een combinatie van beide.
Op Digit Life is een uitgebreid artikel verschenen over clustering. Het stuk is niet bedoeld als analyse van varianten op verschillende probleemoplossingen maar gaat dieper in op de terminologie en de toepassingsmogelijkheden. Na een korte inleiding over clusters in het algemeen gaat de schrijver dieper in op de verschillen in architectuur. De kenmerken van een cluster zijn afhankelijk van het doel waar het system voor gebruikt gaat worden. De systemen zijn globaal in te delen in drie groepen: High Performance(HP), High Availability (HA) of een combinatie van beide.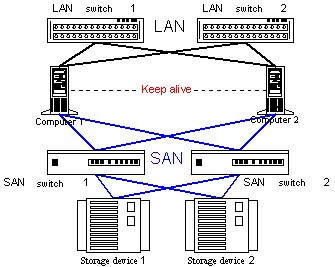

/u/9170/got.JPG?f=community)
:strip_icc():strip_exif()/u/27572/crop5d5fa7a843673_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/22964/amd.jpg?f=community)
/u/1/femme.png?f=community)
/u/38782/crop6146c7a29805d_cropped.png?f=community)
:strip_icc():strip_exif()/u/30300/crop649b06535e901_cropped.jpg?f=community)
:strip_exif()/u/8402/Untitled-2.gif?f=community)
:strip_icc():strip_exif()/u/1508/sax_k.jpg?f=community)
/u/11574/crop600813d96273f_cropped.png?f=community)