De NSA waarschuwt systeembeheerders hun netwerken te updaten zodat zij beschermd blijven tegen potentiële wormaanvallen. De veiligheidsdienst doelt daarbij op BlueKeep, een rdp-lek waarvoor inmiddels een patch beschikbaar is.
De waarschuwing van de NSA gaat specifiek over CVE-2019-0708, een kwetsbaarheid die ook wel BlueKeep wordt genoemd. Dat is een voormalige zero-daykwetsbaarheid die vooral oudere computersystemen treft. Windows XP en Windows 7, en Windows Server 2003, 2008 en 2008 R2 zijn daardoor vatbaar voor aanvallen. Microsoft heeft inmiddels een patch uitgebracht voor de kwetsbaarheid.
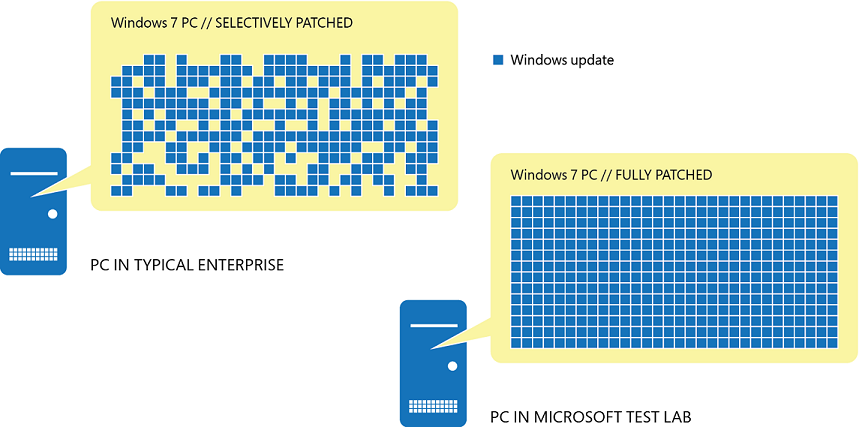
BlueKeep is een kwetsbaarheid in remote desktop services op Windows. Het is een vergelijkbaar probleem als die grote ransomwareaanvallen zoals WannaCry en (Not)Petya wisten uit te buiten en waardoor voor miljoenen euro's schade ontstond. De NSA waarschuwt dat als systemen kwetsbaar en niet up-to-date zijn, er opnieuw kans is op zo'n aanval. Hoewel er al een patch beschikbaar is hebben veel systeembeheerders die nog niet doorgevoerd. Er zijn nog steeds meer dan een miljoen kwetsbare systemen op internet aangesloten. Ook voor de kwetsbaarheden waar WannaCry en (Not)Petya gebruik van maakten waren al patches beschikbaar, maar die waren in veel gevallen niet doorgevoerd.
Het is de eerste keer dat de Amerikaanse veiligheidsdienst reageert op de situatie. Dat doet de NSA, die ook wel eens 'Never Say Anything' wordt genoemd, vrijwel nooit. De dienst heeft zich ook nooit uitgesproken over de controversiële diefstal van tools die door de ShadowBrokers-groep naar buiten werden gebracht.
"We roepen iedereen op tijd en middelen te steken in het leren kennen van je netwerk en om besturingssystemen van patches te voorzien. Dat is niet alleen belangrijk voor het beschermen van nationale veiligheidssystemen die de NSA beschermt, maar voor alle netwerken." De dienst geeft een aantal tips aan systeembeheerders, zoals het sluiten van tcp-poort 3389, en het inschakelen van Network Level Authentication. Ook zouden systeembeheerders remote desktop services moeten uitschakelen als ze die services niet nodig hebben.
De NSA is niet de enige partij die waarschuwt voor het patchen van systemen. Eerder deze week deed Microsoft hetzelfde.

/i/2001462189.png?f=fpa)
/i/1223118312.png?f=fpa)
/i/1230466687.png?f=fpa)
:strip_exif()/i/1398151713.jpeg?f=fpa)
/i/1277037256.png?f=fpa)
/i/1279002275.png?f=fpa)
/i/2001507527.png?f=fpa)
:strip_icc():strip_exif()/u/448966/crop62a741840cd69_cropped.jpg?f=community)
/u/94596/crop643fb12fd4e6d.png?f=community)
:strip_icc():strip_exif()/u/6764/cergorach.jpg?f=community)
:strip_icc():strip_exif()/u/362142/crop5c5080164c7ac_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/259705/AC.jpg?f=community)
:strip_icc():strip_exif()/u/78725/train-icon3.jpg?f=community)
:strip_exif()/u/34653/KeiFrontanim.gif?f=community)
:strip_icc():strip_exif()/u/233264/crop58207dc583e1d_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/79614/Family-Guy-Victory-is-Ours.jpg?f=community)
/u/107495/godzilla%252060x60.png?f=community)
/u/417613/crop5df91c60a28d2.png?f=community)
:strip_exif()/u/82844/crop5aec235376101.gif?f=community)
/u/93629/crop5f5b31620d196_cropped.png?f=community)
:strip_exif()/u/176890/crop63d223070f387_cropped.webp?f=community)
:strip_icc():strip_exif()/u/417493/crop58174774d1256.jpeg?f=community)
:strip_icc():strip_exif()/u/44988/crop5ebb1607ca069_cropped.jpeg?f=community)
/u/49116/crop5ab3aba55abd9_cropped.png?f=community)
/u/477733/crop5fd5d66004f79_cropped.png?f=community)
/u/407403/WAhack.png?f=community)
:strip_icc():strip_exif()/u/541076/crop5c0c5d7e04bf6_cropped.jpeg?f=community)
/u/129832/crop5e026f2850799_cropped.png?f=community)
:strip_icc():strip_exif()/u/21673/crop65674aee06c6d_cropped.jpg?f=community)
{kind=link}