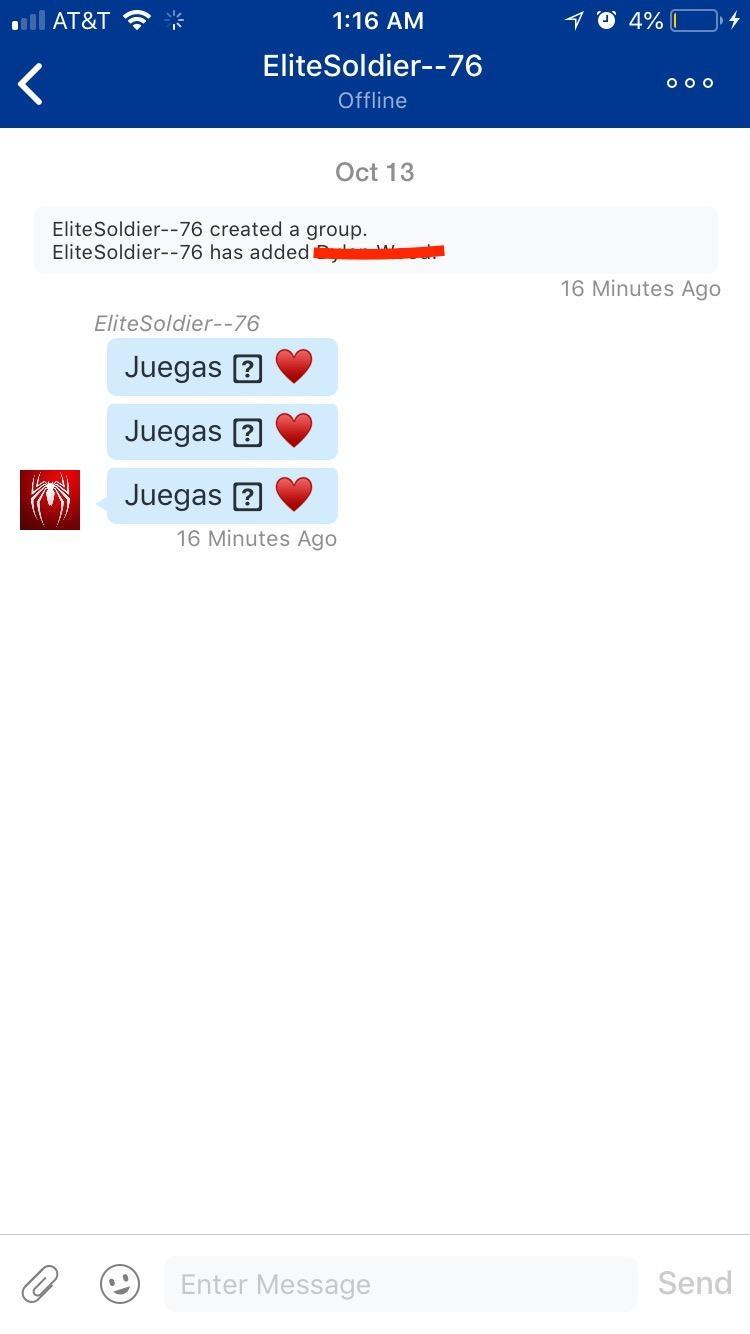
PlayStation 4-gebruikers maken melding van een privébericht dat hun console een bootloop in stuurt. Het probleem is te voorkomen door berichten van alleen vrienden of helemaal niemand toe te staan.
Het bericht bevat volgens Redditposters een teken dat niet weergegeven kan worden, waarna in- en outputs uitvallen en herstarten een bootloop oplevert. Volgens de meldingen kan het probleem voorkomen worden door het bericht op de console ongeopend te laten en te verwijderen via de PS4-berichtenapp. Voor wie het bericht al geopend heeft, lijkt een factory reset de enige remedie, eventueel gevolgd door een database rebuild vanuit safe mode.
De problemen lijken zich sinds dit weekend voor te doen. In sommige gevallen worden hele groepen spelers tegelijk getroffen door het probleem door middel van een groepsgesprek. Waarschijnlijk doet het probleem zich voor op iedere variant van de PlayStation 4, aangezien ze dezelfde firmware draaien. Sony heeft nog niet gereageerd op verzoeken tot commentaar van bijvoorbeeld Kotaku.

:fill(white):strip_exif()/i/1370918689.jpeg?f=thumbmedium)
:strip_exif()/i/2001246817.png?f=thumbmedium)
:strip_exif()/i/2000614887.jpeg?f=fpa)
:fill(white):strip_exif()/i/2001223149.jpeg?f=thumbmedium)
:strip_exif()/i/1369083932.jpeg?f=fpa)
/i/2001708299.png?f=fpa)
/i/2001660975.png?f=fpa)
:strip_exif()/i/1377062847.jpeg?f=fpa)
/i/2000658159.png?f=fpa)
/i/2000946917.png?f=fpa)
/i/2000777301.png?f=fpa)
:strip_icc():strip_exif()/u/43727/crop5f1869322b29b.jpeg?f=community)
:strip_icc():strip_exif()/u/72351/Toon_en_Len%25202015-02-02%252070x69.jpg?f=community)
:strip_icc():strip_exif()/u/604689/rsz_1triryche.jpg?f=community)
:strip_icc():strip_exif()/u/57655/SuperTeamLogo.jpg?f=community)
:strip_exif()/u/219668/crop6818d9983dc68_cropped.webp?f=community)
:strip_exif()/u/47900/baph.gif?f=community)
/u/59561/crop581d08355d484_cropped.png?f=community)
/u/1983/whiteButton.png?f=community)
:strip_exif()/u/147595/avaterTZ.gif?f=community)
:strip_icc():strip_exif()/u/974823/crop5f0647b8b52de_cropped.jpeg?f=community)
/u/62384/crop61891f444d6e9.png?f=community)
:strip_exif()/u/53522/crop583d477015a24.gif?f=community)
/u/441310/crop57949f5d0029b_cropped.png?f=community)
:strip_icc():strip_exif()/u/78725/train-icon3.jpg?f=community)
/u/136818/2dt252w.png?f=community)
/u/1127039/crop5bc35819cbc55.png?f=community)
/u/727812/crop5c893c9ed11f9.png?f=community)
/u/269449/crop5f3cdfa201d6b_cropped.png?f=community)
/u/508157/crop5d74f356d7e4f_cropped.png?f=community)
:strip_exif()/u/31303/HMC2.gif?f=community)
:strip_icc():strip_exif()/u/251795/Untitled.jpg?f=community)
/u/286895/icon1.png?f=community)
:strip_exif()/u/677/crop5e62ccc026e5a_cropped.gif?f=community)
/u/466919/Tweakers_p9_v2.png?f=community)
:strip_exif()/u/15256/Froukje.gif?f=community)
:strip_exif()/u/910003/crop5a0824f8c2602_cropped.gif?f=community)
/u/292867/crop5630e1f334453_cropped.png?f=community)
:strip_icc():strip_exif()/u/453808/image.jpg?f=community)
/u/152942/crop687206d7bca78.png?f=community)
:strip_icc():strip_exif()/u/403133/crop55f6a82e900d9_cropped.jpeg?f=community)
:strip_exif()/u/219702/crop5af8a47963858_cropped.gif?f=community)
:strip_icc():strip_exif()/u/341611/crop59bdeb03f3805_cropped.jpeg?f=community)
/u/658225/avaaataaar.png?f=community)
:strip_icc():strip_exif()/u/109168/crop5c6ad3dc9bc0f_cropped.jpeg?f=community)
:strip_exif()/u/422307/crop5f88f7389f36f_cropped.gif?f=community)