Mozilla heeft de Nederlandse taal toegevoegd aan zijn Common Voice-project. Dat betekent dat vrijwilligers hun stem kunnen laten opnemen bij het voorlezen van bepaalde zinnen. Het project heeft tot doel om een open dataset te bouwen van verschillende talen.
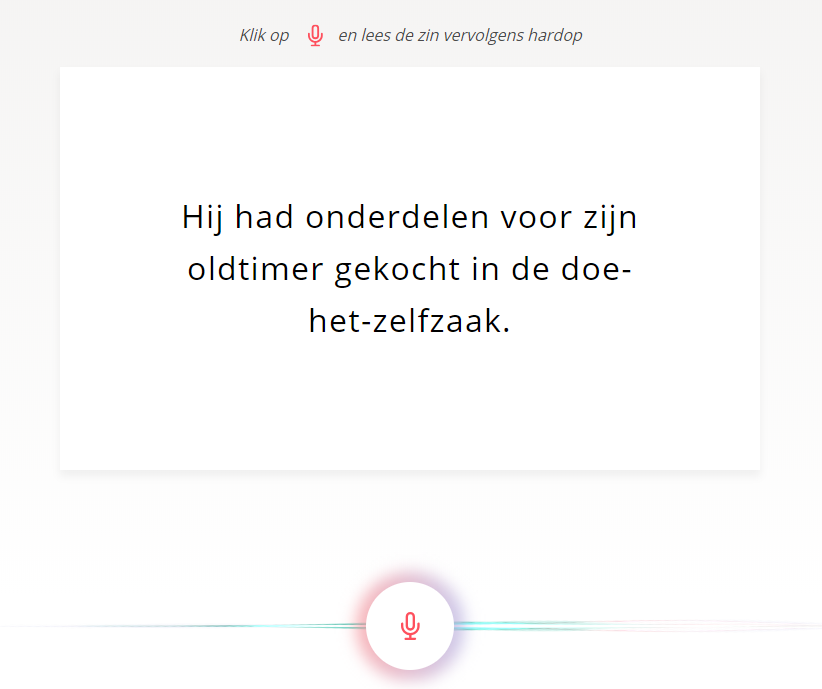
Common Voice bestaat al sinds de introductie halverwege vorig jaar, maar sinds kort kunnen gebruikers ook Nederlandse zinnen inspreken. Tot nu toe hebben vier sprekers een totaal aan 51 seconden opgenomen, de doelstelling is 1200 uur.
Er zijn maar weinig talen die veel bijdragen hebben, met uitzondering van Engels. De teller staat daar op 462 uur met in totaal meer dan 30.000 sprekers.
Bij de introductie van Common Voice zei Mozilla dat het de bedoeling is een open dataset met een CC0-licentie te bouwen aan de hand waarvan bijvoorbeeld onderzoekers spraakdiensten kunnen ontwikkelen die werken met machinelearning.
Samen met Common Voice kondigde Mozilla destijds ook het opensourceproject DeepSpeech aan, dat zich richt op speech-to-text. Op die manier moeten mensen meer keuze krijgen als het gaat om spraakherkenningsdiensten, is de redenering. Onder meer de slimme speaker Mycroft gebruikt DeepSpeech, dat op zijn beurt weer Common Voice gebruikt.

/i/2007107056.webp?f=fpa)
/i/1395213870.png?f=fpa)
/i/1200057701.png?f=fpa)
/i/2002127237.png?f=fpa)
/i/2001765419.png?f=fpa)
:strip_exif()/i/2001355005.jpeg?f=fpa)
/i/1324382284.png?f=fpa)
/u/311399/pa.png?f=community)
:strip_icc():strip_exif()/u/407197/tweakers%2520forum.jpg?f=community)
:strip_icc():strip_exif()/u/521319/crop68bfc0d4c3484_cropped.jpg?f=community)
/u/613192/crop575c74557b493_cropped.png?f=community)
/u/314906/crop68a5aa8bdd674_cropped.png?f=community)
/u/217510/crop660db19c1cf7b_cropped.png?f=community)
:strip_icc():strip_exif()/u/61340/125281113_256.jpg?f=community)
/u/27299/hoofd.png?f=community)
:strip_icc():strip_exif()/u/18624/ogen.jpg?f=community)
/u/223884/tweakerslogo.png?f=community)
/u/261030/crop5697ab2d20937.png?f=community)
/u/31680/crop6a240bdb852c3_cropped.png?f=community)
/u/143137/crop5d1c4f96268ca_cropped.png?f=community)
:strip_icc():strip_exif()/u/176404/crop5d8a18233281d_cropped.jpeg?f=community)
:strip_exif()/u/69523/knijper2.gif?f=community)
:strip_exif()/u/467778/crop5d7a5dd1f296a.gif?f=community)
/u/246423/crop5979eb9e5c60f_cropped.png?f=community)
:strip_exif()/u/106680/LOY_kleinerder.gif?f=community)
:strip_exif()/u/341057/minibeevatar.gif?f=community)
:strip_icc():strip_exif()/u/481839/e-resized.jpg?f=community)
:strip_icc():strip_exif()/u/489983/crop5db33928bbeea_cropped.jpeg?f=community)
:strip_exif()/u/64172/crop63592a78cad19.gif?f=community)
:strip_icc():strip_exif()/u/155904/crop5ab030145f248_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/1850/crop668bec02ef9dd.jpg?f=community)