Facebook heeft een methode ontworpen om de trainingstijd voor machine learning terug te brengen bij het verhogen van het aantal gpu's. Een test bij een dataset van 1,2 miljoen afbeeldingen verlaagde de trainingstijd van meerdere dagen naar een uur, met behoud van accuraatheid.
Facebook maakt voor zijn methode gebruik van het modulaire Caffe2-framework voor schaalbare deep learning en van de Gloo-library voor collectieve communicatie. De software draaide op Facebooks eigen Big Basin-servers met Nvidia Tesla P100-accelerators.
Facebook zet hiermee gedistribueerde training voor deep learning-modellen in, met Distributed synchronous SGD, maar onderzoekers van het bedrijf voeden de gpu's met grotere minibatches van beelden dan gebruikelijk.
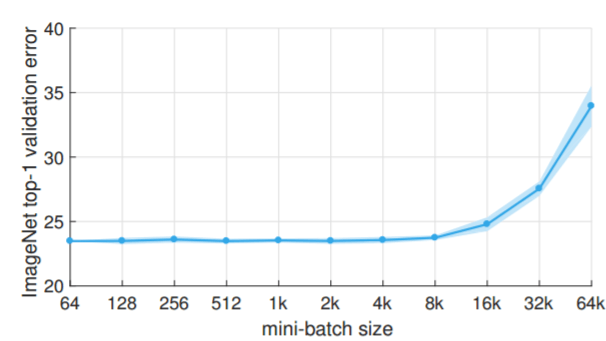
Bij een test met het populaire ResNet-50-model voor beeldclassificatie op ImageNet, bestaande uit 1,2 miljoen afbeeldingen, deed Facebook er 29 uur over om te trainen met 8 Tesla P100-accelerators als minibatches van 256 beelden ingezet werden. Tot nu toe was het zo dat grotere modellen en datasets tot een flinke toename van de trainingstijd leidden, wat opschalen bemoeilijkt. De onderzoekers van Facebook slaagden erin de omvang van de minibatches te verhogen naar 8192 afbeeldingen, waardoor het aantal gpu's ook efficiënt verhoogd kan worden, bij het onderzoek naar 256 gpu's. Hiermee lukte het om ResNet-50 in een uur te trainen, met behoudt van het accurate niveau van de kleinere batches.
Het onderzoek met de titel Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour werd gepresenteerd door de Nederlandse Facebook-ontwikkelaar Pieter Noordhuis tijdens de Data @Scale-conferentie in Seattle.

/i/2000593550.png?f=fpa)
/i/2000820476.png?f=fpa)
/i/1233670851.png?f=fpa)
:strip_exif()/i/1353487218.jpeg?f=fpa)
/u/58600/got_icoon.png?f=community)
/u/407403/WAhack.png?f=community)
:strip_icc():strip_exif()/u/20205/IconMindGames.jpg?f=community)
/u/176320/3.png?f=community)
:strip_icc():strip_exif()/u/303210/favritegotevj9.jpg?f=community)
:strip_icc():strip_exif()/u/143704/crop5e1e448ecf136_cropped.jpeg?f=community)
/u/177191/crop6213dc4802e4f.png?f=community)
:strip_exif()/u/186029/crop5eb41ba83051f_cropped.gif?f=community)
{kind=link}
{kind=link}
{kind=link}
{kind=link}