Onderzoekers hebben een prototype gebouwd van een 'memcomputer', een computer die werkt door bepaalde eigenschappen van het menselijk brein na te bootsen. De bevindingen kunnen helpen computers te ontwikkelen die gebruik maken van 'memprocessors'.
Memprocessors bestaan uit samenwerkende geheugencellen die gebruik maken van de mogelijkheid om zowel informatie op te slaan als te verwerken. De in de paper gepresenteerde machine is technologisch nog erg gelimiteerd en het is daarom ook een proof-of-concept, schrijven de onderzoekers in de inleiding. De machine werd gebouwd door gebruik te maken van standaard micro-elektronica zodat de theorie makkelijk naar de praktijk omgezet kon worden in een laboratoriumopstelling.
De auteurs van de studie publiceerden al eerder dit jaar een theoretische paper over een mogelijke memcomputer waarin ze aantoonden dat het voor een memcomputing-machine makkelijker moet zijn 'notoir moeilijke computationele problemen op te lossen, zogenaamde NP-volledige problemen'. Met het gebouwde prototype krijgen de auteurs het voor elkaar om een NP-volledige versie van het subset sum-probleem op te lossen in slechts één stap, met behulp van een aantal memprocessors die lineair meeschalen met de grootte van het probleem. De door de onderzoekers gebouwde machine heeft wel veel last van ruis, maar biedt wel mogelijkheden voor de toekomst.
Als een normale computer, of deterministische Turingmachine, een NP-volledig probleem moet oplossen, zoals het handelsreizigersprobleem, kunnen de benodigde processorkracht en het geheugen heel snel omhoog gaan. Bij het handelsreizigersprobleem ontstaat dit door het toenemen van het aantal punten waar deze langs moet. Daardoor kan het oplossen vrijwel onmogelijk worden. Theoretisch kan deze computer problemen wel in korte tijd oplossen. Andere computers die dergelijke problemen in de toekomst mogelijk op zouden kunnen lossen, zijn bijvoorbeeld kwantumcomputers.
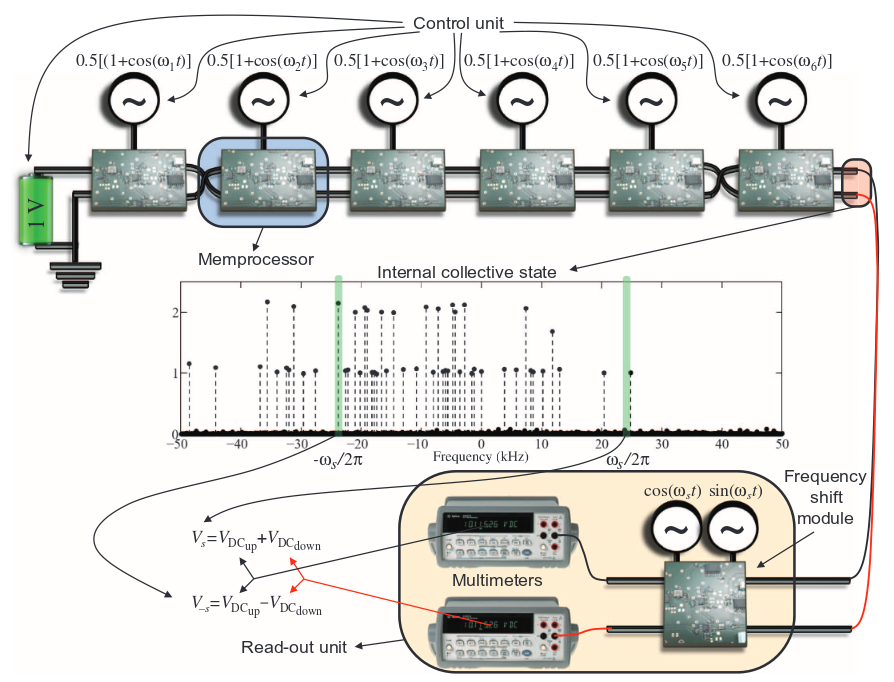 Schema van de memcomputerarchitectuur die voor dit experiment gebruikt werd om het subset sum-probleem op te lossen Bron: AAAS
Schema van de memcomputerarchitectuur die voor dit experiment gebruikt werd om het subset sum-probleem op te lossen Bron: AAAS

/i/1288623446.png?f=fpa)
/i/1257342214.png?f=fpa)
:strip_exif()/i/1295427894.gif?f=fpa)
/i/1225133057.png?f=fpa)
:strip_exif()/i/1068828305.jpg?f=fpa)
/u/99142/crop62758e978b3e3_cropped.png?f=community)
/u/27299/hoofd.png?f=community)
:strip_icc():strip_exif()/u/107918/s1.jpg?f=community)
/u/599314/jetjaguar.png?f=community)
:strip_icc():strip_exif()/u/428264/t6vldloofbntjgsxehen.jpg?f=community)
:strip_icc():strip_exif()/u/85308/mirko.jpg?f=community)