Internetknooppunt AMS-IX kampte woensdagmiddag met uitval. Veel sites, waaronder GeenStijl, Facebook, NU.nl en Tweakers, waren daardoor gedurende een korte tijd niet of slecht bereikbaar. De problemen traden op bij onderhoudswerkzaamheden.
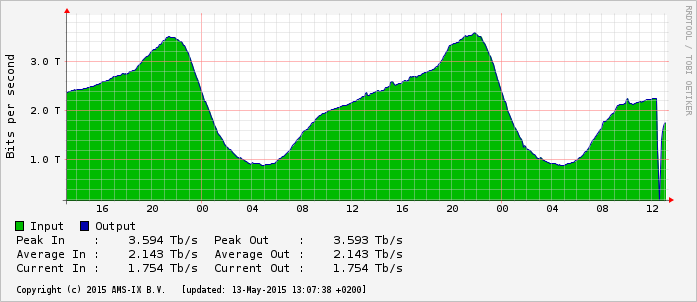
Op de statistieken van de AMS-IX is te zien dat het verkeer over het internetknooppunt, het belangrijkste van Nederland en een van de grootste ter wereld, iets na 12 uur 's middags tot het nulpunt daalt. Dat wil niet zeggen dat al het verkeer over het knooppunt uitviel: bij de storing viel het meetsysteem uit. Inmiddels is de storing weer verholpen, laat een woordvoerster van de AMS-IX weten.
Volgens webhoster GreenHost handelde AMS-IX ongeveer tien procent van het gebruikelijke internetverkeer af. De AMS-IX kan dat percentage niet bevestigen. Als gevolg van de storing kampten veel grote websites - waaronder GeenStijl, Facebook, NU.nl en Tweakers - met bereikbaarheidsproblemen. Ook het pinverkeer was woensdagmiddag verstoord.
De AMS-IX stelt dat het probleem werd veroorzaakt tijdens een fout bij onderhoudswerkzaamheden. In een mail aan leden van de AMS-IX, waarvan Tweakers de authenticiteit heeft bevestigd, meldt de AMS-IX dat een installatiemedewerker per ongeluk een loop op een vlan aanmaakte. Dat gebeurde op de AMS-IX-locatie in het AM3-datacenter van Equinix. Daardoor raakten de systemen van het knooppunt overbelast, waardoor veel border gateway protocol-sessies werden beëindigd. Het bgp-protocol wordt gebruikt om individuele netwerken aan elkaar te knopen.
Volgens de AMS-IX heeft de storing 'maximaal tien minuten' geduurd. Het gebeurt zelden dat de AMS-IX, die is verspreid over meerdere locaties, voor zo'n groot deel stil ligt; voor zover bekend is dat de afgelopen jaren niet gebeurd.
In de statistieken van Tweakers is te zien dat de backup-locatie van de techsite het werk van de hoofdlocatie grotendeels moest overnemen. Beide locaties zijn aangesloten op de AMS-IX, maar allebei op een andere route.
Update, 13:17: Reactie AMS-IX toegevoegd.
Update, 13:39: Meer informatie over oorzaak toegevoegd.
/i/2000611059.png?f=imagenormal)

:strip_exif()/i/1297761893.gif?f=fpa)
:strip_exif()/i/1059519197.gif?f=fpa)
/i/1219233120.png?f=fpa)
/i/1213892824.png?f=fpa)
:strip_exif()/i/1299509752.gif?f=fpa)
:strip_exif()/u/36176/44.gif?f=community)
:strip_exif()/u/53522/crop583d477015a24.gif?f=community)
/u/15883/crop595df51c3834e_cropped.png?f=community)
:strip_icc():strip_exif()/u/961/crop69b8f434281b1_cropped.jpg?f=community)
:strip_exif()/u/2172/crop57acf4ac04e70.gif?f=community)
:strip_exif()/u/19165/9cdefd.gif?f=community)
/u/41514/crop5c3b77c8badbf_cropped.png?f=community)
:strip_icc():strip_exif()/u/476420/crop5623d9ad036cf_cropped.jpeg?f=community)
/u/39500/BoGy_4_Tweakers_60.png?f=community)
/u/371406/crop5fbbc007da51e_cropped.png?f=community)
/u/8/oog3.png?f=community)
/u/3626/front-kabels.png?f=community)
:strip_exif()/u/16838/usericon.gif?f=community)
:strip_exif()/u/1703/crop5645b8b802a60_cropped.gif?f=community)
/u/482146/60x60_robo.png?f=community)
/u/13471/karnemelk.png?f=community)
/u/348359/crop5d1c8bf1db6bd_cropped.png?f=community)
:strip_icc():strip_exif()/u/36153/crop56ca0da3b0f2e.jpeg?f=community)
/u/201305/Pig.png?f=community)
/u/58518/crop55c9fb6f4244f_cropped.png?f=community)
/u/36414/blaat.JPG?f=community)
/u/255979/egel.png?f=community)
:strip_icc():strip_exif()/u/4167/bacall8.jpg?f=community)
:strip_icc():strip_exif()/u/524927/rsz_500px-leeroy_jenkins.jpg?f=community)
:strip_icc():strip_exif()/u/6105/crop5864bdfc59eeb_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/480920/crop560beea971308_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/109168/crop5c6ad3dc9bc0f_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/307988/crop5d386ba3e3a93_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/296384/AMDINSIDE.jpg?f=community)
/u/273924/Untitled.png?f=community)
:strip_icc():strip_exif()/u/4634/ratbuddy_ORIGINAL.jpg?f=community)
/u/660638/crop5b3093da322cb_cropped.png?f=community)
/u/602366/crop6478e12ac629b.png?f=community)
:strip_icc():strip_exif()/u/71115/plus222.jpg?f=community)
:strip_icc():strip_exif()/u/79657/crop5999e2bd51b92_cropped.jpeg?f=community)
{kind=link}
{kind=link}
{kind=link}