Nvidia heeft meer details van zijn komende Denver-soc vrijgegeven. Deze 64bit-ARMv8-soc krijgt onder andere de beschikking over een mechanisme dat dynamic code optimization is gedoopt. Volgens Nvidia is de Denver-soc de snelste 64bit-processor voor Android-hardware.
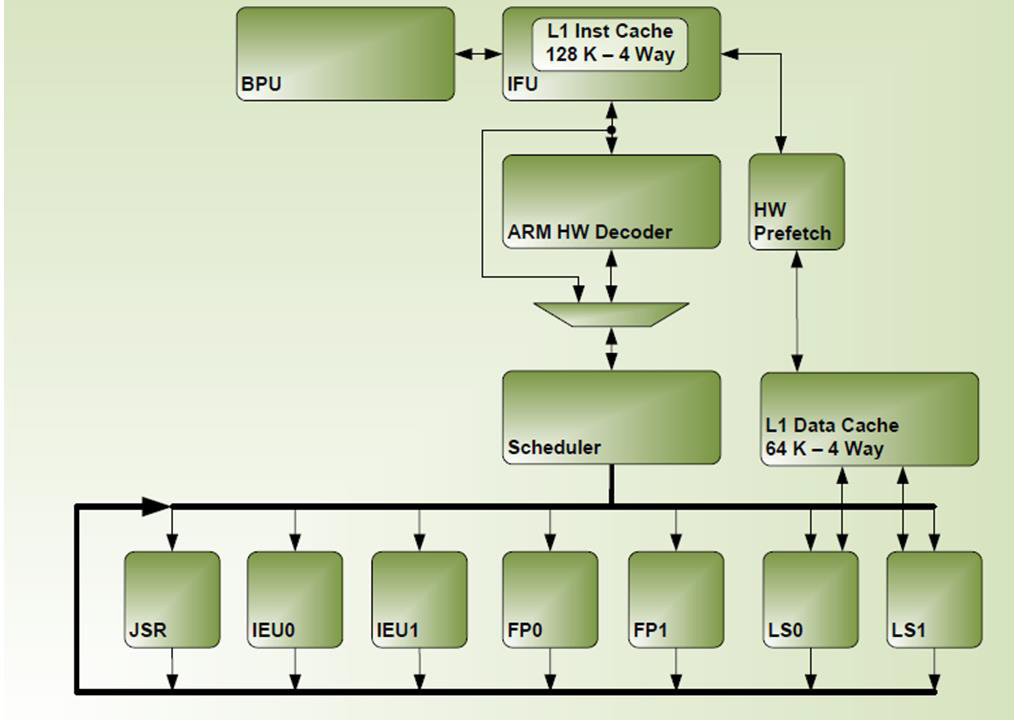 De plannen voor een 64bit-uitvoering op basis van de Tegra K1-processor werden in januari tijdens de CES geopenbaard. Inmiddels heeft Nvidia in een blogposting en whitepaper meer details over de architectuur van de dualcore-Denver-soc bekendgemaakt.
De plannen voor een 64bit-uitvoering op basis van de Tegra K1-processor werden in januari tijdens de CES geopenbaard. Inmiddels heeft Nvidia in een blogposting en whitepaper meer details over de architectuur van de dualcore-Denver-soc bekendgemaakt.
Bijzonder aan het ontwerp is dat er geen gebruik wordt gemaakt van out of order execution, zoals het geval is bij bijna elke moderne processorachitectuur, maar van in order execution. Bij OoO-execution worden instructies niet altijd in de volgorde verwerkt waarin ze binnenkomen. In gevallen waarin twee opvolgende instructies op elkaar moeten wachten, kan de processor onafhankelijke instructies voorrang geven, wat de efficiëntie ten goede komt. Moderne socs van onder andere Samsung, Qualcomm en Intel maken gebruik van OoO-exeuction.
Om vergelijkbare resultaten te behalen maakt Nvidia gebruik van softwareroutines die de binnenkomende instructies en bijbehorende branch results analyseren en omzetten naar geoptimaliseerde microcode. De geoptimaliseerde instructies worden vervolgens in een 128MB-blok van het werkgeheugen geplaatst, terwijl een kleine cache op de chip een look-up-table bevat, waardoor de processor de geoptimaliseerde code snel moet kunnen terugvinden.


Dankzij die techniek, door Nvidia dynamic code optimization genoemd, worden prestaties behaald die vergelijkbaar zijn met een out of order-architectuur, zonder dat energievretende fix function logic nodig is in het chipontwerp, aldus Nvidia. Een bijkomend voordeel is volgens Nvidia dat zijn softwarematige oplossing een grotere set instructies tegelijk kan analyseren dan de hardware in een OoO-processor.
Het ontwerp komt niet zonder nadelen. Zo levert het softwarematig optimaliseren van de instructies overhead op en daarnaast is de Denver-kern mede door de toevoeging van extra cache een stuk groter dan de Cortex A15-kern in de 32bit-versie van de K1-soc. Waar die versie van de chip vijf Cortex A15-kernen weet te huisvesten, passen op datzelfde oppervlak bij de 64bit-variant slechts twee Denver-cores. De chips zijn overigens wel pin compatible.
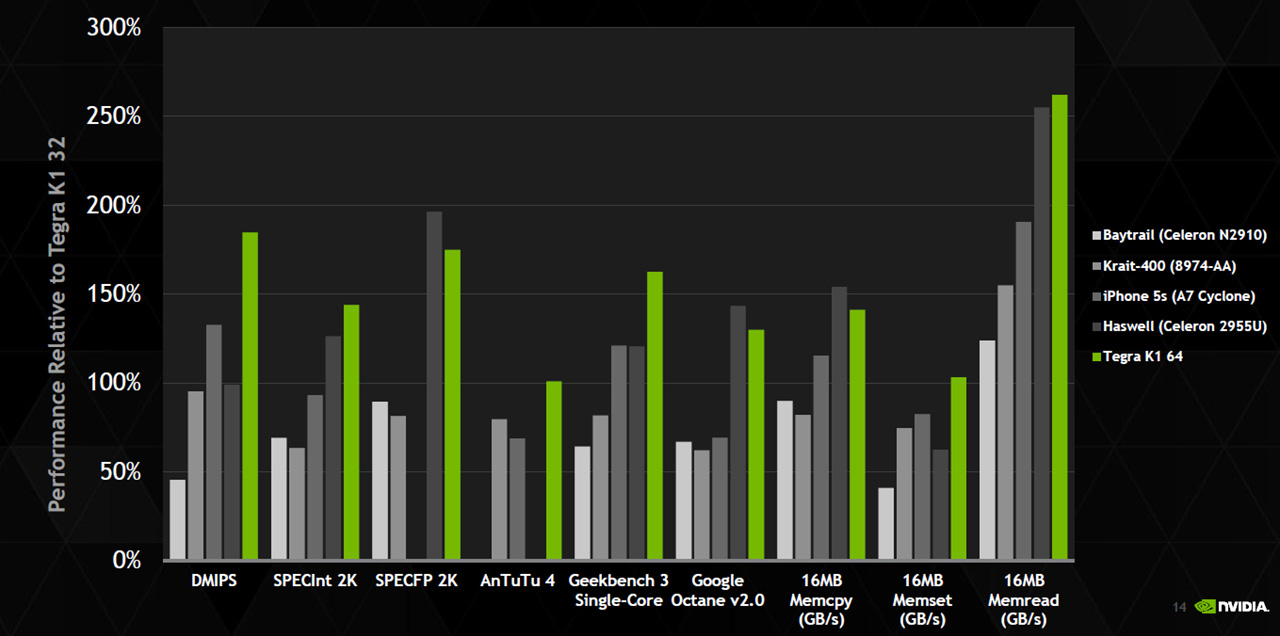
Nvidia claimt dat de Denver-soc met een kloksnelheid van 2,5GHz prestaties levert die gelijkwaardig of beter zijn dan die van Apples A7-soc. Volgens Nvidia kunnen ook Celerons uit Intels Haswell-serie in sommige tests worden bijgebeend op ipc-vlak. Daarmee zou het de snelste 64bit-ARM-soc voor de Android-markt zijn. De eerste producten waarin de 64bit-versie van de Tegra K1-soc beschikbaar is, moeten later dit jaar op de markt komen.

/i/1208164214.png?f=fpa)
/i/1270893438.png?f=fpa)
/i/1362397391.png?f=fpa)
/i/1368542044.png?f=fpa)
:strip_exif()/i/1212428440.gif?f=fpa)
:strip_exif()/u/16366/NeXTLogo-av.gif?f=community)
/u/1983/whiteButton.png?f=community)
/u/23785/crop5dcd5c59e07f9.png?f=community)
:strip_icc():strip_exif()/u/18149/catfish60.jpg?f=community)
:strip_icc():strip_exif()/u/323915/crop61af7c1e3ca8b_cropped.jpg?f=community)
/u/155722/Looneytunes.png?f=community)
/u/34200/crop6554f56fe2075_cropped.png?f=community)
:strip_icc():strip_exif()/u/81611/headcrop.jpg?f=community)
/u/265761/MadIce.png?f=community)
{kind=link}