Nvidia is van plan om een nieuwe, snellere interface in zijn gpu's te bouwen, zodat gpu's en cpu's data vijf keer zo snel kunnen delen als nu. Ook gaat het bedrijf in 2016 een nieuwe reeks gpu's op de markt brengen, onder de naam Pascal.
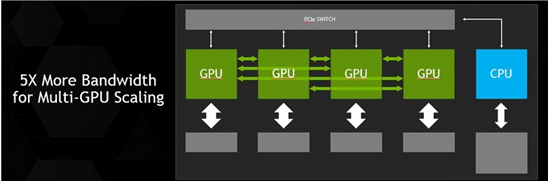
De huidige pci-express 3.0-interface die wordt gebruikt als interface om een gpu in een pc te steken is volgens Nvidia een belangrijke bottleneck. De NVLink-interface moet dat oplossen, zo heeft Nvidia tijdens een persconferentie bekendgemaakt. NVLink is vijf tot twaalf keer zo snel als pci-express 3.0. Ook blijven de caches tussen de cpu en de gpu gesynchroniseerd.
Het sneller heen en weer kunnen schuiven van data is volgens Nvidia vooral van belang voor supercomputers. De nieuwe interface maakt volgens het bedrijf supercomputers met 1000 petaflops mogelijk, wat 50 tot 100 keer zo snel is als de huidige supercomputers.
De nieuwe interface zal nog worden toegepast met Nvidia-gpu's die de Maxwell-architectuur gebruiken, maar wanneer precies is nog niet bekend. De eerste gpu's met die architectuur werden vorige maand aangekondigd.
Daarnaast gaat Nvidia in 2016 gpu's uitbrengen met een nieuwe architectuur, onder de naam Pascal. Die architectuur moet zijn voorzien van geheugen dat bovenop de gpu wordt geplaatst, waardoor een gpu met duizenden bits tegelijk kan werken, waar dat nu nog maximaal honderden bits zijn. Dat principe, door Nvidia 3d memory gedoopt, zorgt bovendien voor kleinere high-end-gpu's: tijdens de keynote toonde de ceo van Nvidia een Pascal-kaart met de grootte van een betaalpas.

:strip_exif()/i/1338715926.jpeg?f=fpa)
/i/1397132571.png?f=fpa)
/i/1208164214.png?f=fpa)
:strip_exif()/i/1371172691.jpeg?f=fpa)
/i/1237031931.png?f=fpa)
/i/1394087870.png?f=fpa)
/i/1279715721.png?f=fpa)

:strip_exif()/u/200334/crop577a56c4b236f_cropped.gif?f=community)
:strip_icc():strip_exif()/u/109168/crop5c6ad3dc9bc0f_cropped.jpeg?f=community)
:strip_exif()/u/564003/8728.gif?f=community)
:strip_icc():strip_exif()/u/357100/download.jpg?f=community)
:strip_exif()/u/92704/AthlonX2.gif?f=community)
/u/341337/oog.png?f=community)
:strip_icc():strip_exif()/u/174878/SCKnightMicro.jpg?f=community)
:strip_icc():strip_exif()/u/360912/crop55ff0586c3afa_cropped.jpeg?f=community)
/u/38159/DirkJan.png?f=community)
/u/463378/9uDTZt2vQa.png?f=community)