Microsoft geeft testers de mogelijkheid om Windows Server te booten vanaf het bestandssysteem ReFS. Dat alternatief voor Windows' standaard NTFS is al jaren in ontwikkeling. Het biedt betere bescherming tegen datacorruptie en kan schalen tot opslagvolumes van 35PB.
Het Resilient File System van Microsoft maakte zijn debuut met de komst van Windows Server 2012, maar was niet te gebruiken voor het bootvolume van Windows. Dat moest nog altijd geformatteerd zijn met NTFS. Daarin komt nu verandering. Testers in het Windows Insider-programma van Microsoft kunnen de Insider Preview van Windows Server installeren en dan laten draaien op ReFS-volumes.
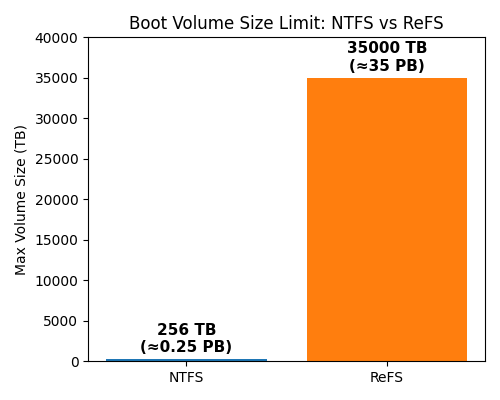
Het alternatieve bestandssysteem van Microsoft biedt betere bescherming tegen zogeheten bitrot. Daarbij kan opgeslagen data corrupt raken door verlies van bijvoorbeeld magnetische of elektrische lading van het opslagmedium. Daarnaast brengt ReFS verbeteringen voor het prestatieniveau van opslag en ondersteunt het volumes tot een maximale capaciteit van 35PB. NTFS kan maximaal 256TB aan.
Builds van de testrelease van Windows Server bieden sinds 11 februari de mogelijkheid van ReFS-boot in het installatiemenu. Voor gebruik van ReFS is wel een systeem met UEFI-firmware nodig, merkt Microsoft op. Oudere virtuele machines gebruiken nog een legacybios en kunnen dit alternatieve bestandssysteem dus niet gebruiken voor hun bootvolume.

:strip_icc():strip_exif()/i/2007711926.jpeg?f=fpa_thumb)
:strip_exif()/i/2004675122.jpeg?f=fpa)
:strip_exif()/i/2005569146.jpeg?f=fpa)
/i/2004763582.png?f=fpa)
/i/2000776373.png?f=fpa)
:strip_exif()/i/1315899998.gif?f=fpa)
/u/115333/crop5f45784fcadad_cropped.png?f=community)
:strip_icc():strip_exif()/u/107049/Spoor12B%2520-%2520cropped4.jpg?f=community)
/u/2466866/crop69a1fc114accf_cropped.png?f=community)
:strip_icc():strip_exif()/u/1138733/crop5bed7f8ee609f_cropped.jpeg?f=community)
/u/2008130/crop6536ebba0daf2_cropped.png?f=community)
:strip_icc():strip_exif()/u/91018/dgtw.jpg?f=community)
/u/27299/hoofd.png?f=community)
:strip_icc():strip_exif()/u/65843/chef60x60.jpg?f=community)
:strip_icc():strip_exif()/u/79614/Family-Guy-Victory-is-Ours.jpg?f=community)
/u/176086/crop5f0823fa5e8d6_cropped.png?f=community)
:strip_icc():strip_exif()/u/1897390/crop66f01cc72c09a_cropped.jpg?f=community)
/u/488034/crop5bc05764b1211_cropped.png?f=community)
/u/1906/crop5dfd46928e003.png?f=community)
/u/818861/crop67e51182dfc04_cropped.png?f=community)
/u/450484/crop5db05062083ff_cropped.png?f=community)