OpenAI heeft GPT-5.3-Codex aangekondigd, een verbeterde versie van de programmeeragent. De 5.3-versie is tot 25 procent sneller en kan grotere taken aan dan de voorgaande versie. De nieuwe variant geeft ook meer updates tijdens het verwerken van opdrachten.
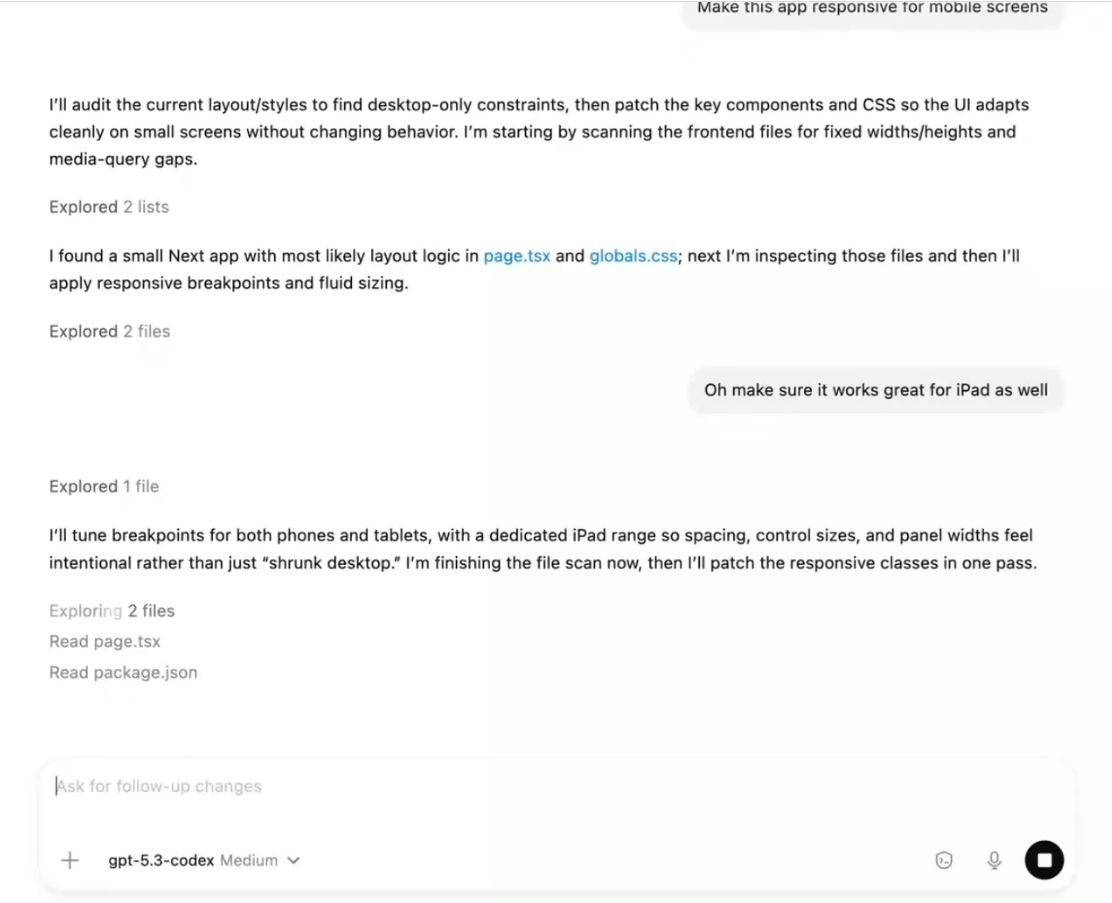
Het verbeterde model kan beter programmeren en redeneren en heeft meer professionele kennis, claimt OpenAI. Daardoor is de programmeeragent tot 25 procent sneller dan de 5.2-versie en kan deze ook taken aan die langer duren en complexer zijn, stelt het bedrijf. Codex kan onder meer gebruikt worden om websites te bouwen, games te ontwikkelen en presentaties te maken.
De verbeterde agent begrijpt bijvoorbeeld beter wat de gebruiker vraagt, waardoor ook eenvoudigere prompts tot betere resultaten leiden, claimt het bedrijf. Het model geeft tijdens het verwerken van prompts ook updates over wat Codex wil doen. Daardoor kunnen gebruikers tijdens het verwerkingsproces vragen stellen of discussies aangaan met de chatbot om het verwerkingsproces aan te passen. Zo hoeven gebruikers niet te wachten tot Codex klaar is om het resultaat aan te kunnen passen, stelt OpenAI.
OpenAI gebruikte GPT-5.3-Codex ook om het model zelf beter te maken. Zo vroeg het onderzoeksteam de agent om bugs in de gaten te houden en op te lossen, of om patronen te herkennen tijdens trainingen en deze te analyseren. Dit zorgde er volgens OpenAI voor dat GPT-5.3-Codex sneller gemaakt kon worden.
GPT-5.3-Codex is per direct beschikbaar voor ChatGPT-abonnees die al toegang hebben tot Codex. De agent is dus beschikbaar in de app, in de terminal, VS Code en web. Api-toegang volgt nog.

:strip_exif()/i/2007654988.jpeg?f=fpa)
:strip_exif()/i/2005545080.jpeg?f=fpa)
:strip_exif()/i/2007853496.jpeg?f=fpa)
:strip_exif()/i/2006208068.jpeg?f=fpa)
/i/2007713342.png?f=fpa)
/i/2006842994.png?f=fpa)
/i/2004954780.png?f=fpa)
:strip_icc():strip_exif()/u/297620/2000d.jpg?f=community)
/u/478524/crop698611adb516a_cropped.png?f=community)
:strip_icc():strip_exif()/u/296601/crop5c3f747d7c066_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/57655/SuperTeamLogo.jpg?f=community)
/u/586088/crop67f63a210249f_cropped.png?f=community)
:strip_icc():strip_exif()/u/234191/crop56914d8580230_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/432714/crop6287e94322cf6_cropped.jpg?f=community)
/u/117810/cupcake2.png?f=community)
/u/155568/usericon.png?f=community)
:strip_icc():strip_exif()/u/406786/256px-Cc_kane_shot.jpg?f=community)