Google heeft zijn nieuwe Gemini 3 Flash-AI-model geïntroduceerd. Volgens het bedrijf scoort het model beter in verschillende benchmarks dan Gemini 2.5 Pro. Het model wordt geleidelijk wereldwijd beschikbaar gemaakt in de Gemini-app en de AI-modus in Google Zoeken.
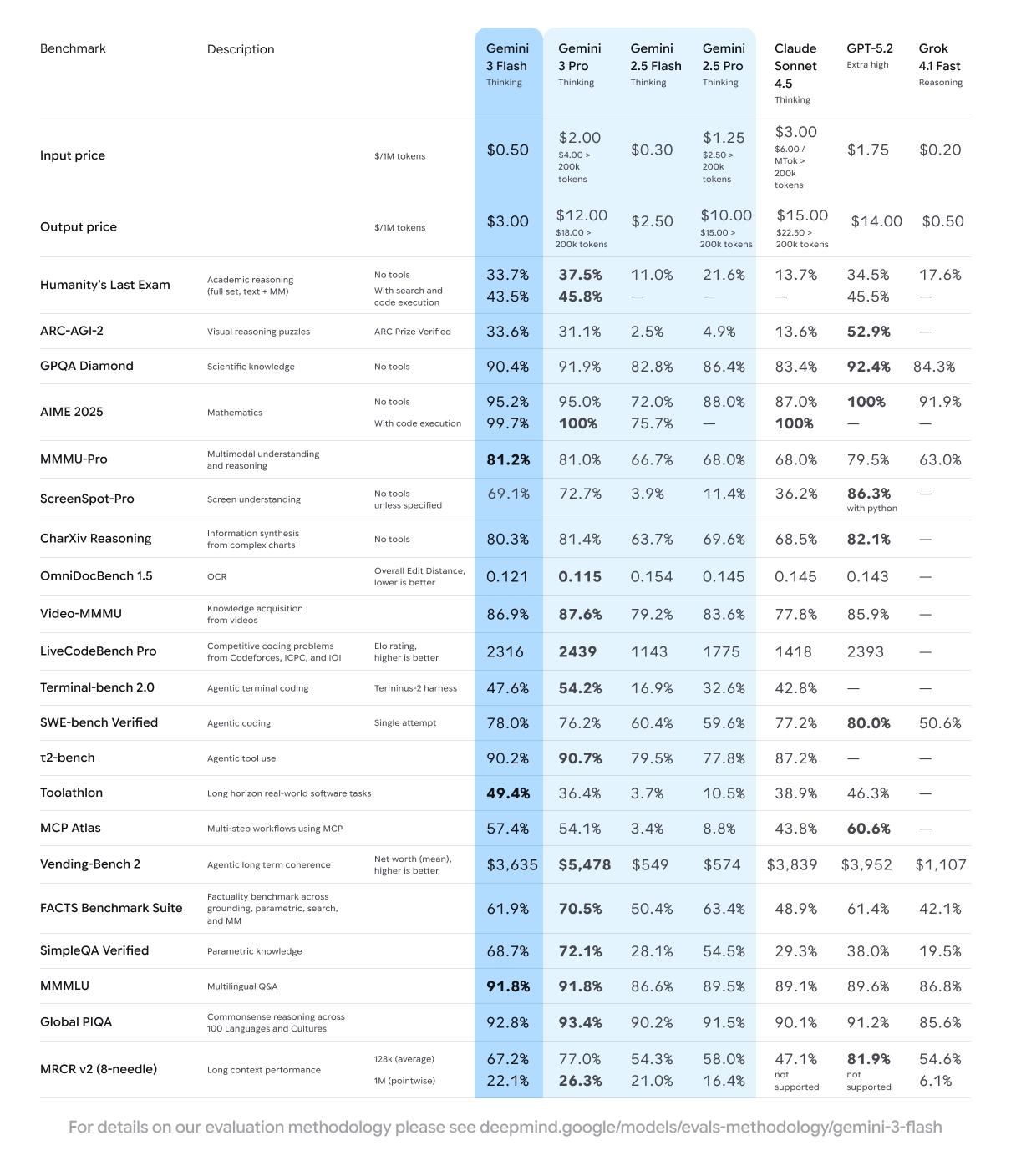
benchmarks hoger dan Gemini 2.5 Pro.
Volgens Google is Gemini 3 Flash drie keer sneller dan 2.5 Pro, terwijl het model ook beter presteert. Het model kost 50 dollarcent per miljoen inputtokens en 3 dollar per miljoen outputtokens. Dat is goedkoper dan Gemini 2.5 Pro, maar duurder dan Gemini 2.5 Flash, dat per miljoen inputtokens 30 dollarcent en per miljoen outputtokens 2,50 dollar kost. Volgens het bedrijf gebruikt Gemini 3 Flash 30 procent minder tokens dan 2.5 Pro.
Gemini 3 Flash is ook per direct beschikbaar als preview in de Gemini-api in Google Studio en via Google Antigravity, Vertex AI en Gemini Enterprise. Het model scoort onder meer 81,2 procent op MMMU-Pro, vergelijkbaar met Gemini 3 Pro. Het model haalt ook 90,4 procent op GPQA Diamond, dat wetenschappelijke kennis test, en 78 procent op de programmeerbenchmark SWE-bench Verified.
Gemini 3 Flash is volgens Google in staat om complexere videoanalyses uit te voeren of te werken in een visueel vraag-en-antwoordsysteem. Ontwikkelaars zouden het model daarom onder meer kunnen inzetten als in-gameassistent.

/i/2007887364.png?f=fpa)
:strip_exif()/i/2007940130.jpeg?f=fpa)
:strip_exif()/i/2007895364.jpeg?f=fpa)
:strip_icc():strip_exif()/u/43939/slotje.jpg?f=community)
/u/23741/crop65d220b3f3de0_cropped.png?f=community)
:strip_icc():strip_exif()/u/1454528/crop5f6239efda858_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/1318532/crop5f6baa8470c0d_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/224922/TESTsmaller.jpg?f=community)
:strip_exif()/u/47330/ava.gif?f=community)
:strip_icc():strip_exif()/u/279592/crop561258ca2dd6e_cropped.jpeg?f=community)
:strip_exif()/u/193139/tweakersIconSmall.gif?f=community)
:strip_icc():strip_exif()/u/94008/crop58ab4f789ed0d_cropped.jpeg?f=community)
:strip_exif()/u/30814/newgot.gif?f=community)