De Internet Engineering Task Force heeft Googles http-over-quic gekozen als netwerkprotocol voor http/3, de opvolger van het huidige http/2. Daarmee wordt de komende http-versie niet op tcp gebaseerd.
IETF-leden hebben hun goedkeuring gegeven aan het voorstel dat http-over-quic wordt hernoemd naar http/3 en dat de ontwikkeling door de QUIC Working Group wordt overgenomen door de HTTP Working Group. Het is de tweede keer dat door Google ontwikkelde technologie het tot http-standaard schopt. De http/2-standaard uit 2015 bouwde voort op Googles spdy-protocol.
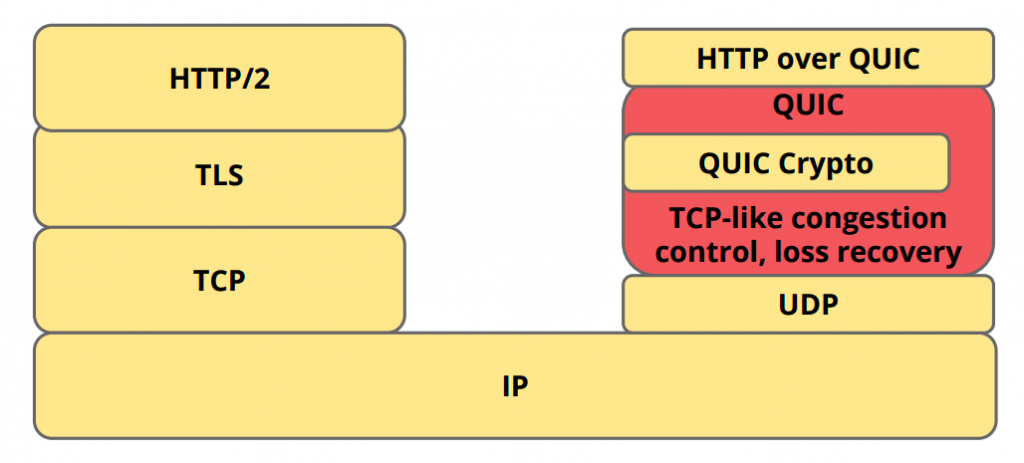
Quic staat voor Quick UDP Internet Connections en werkt via udp. Het protocol zorgt ten opzichte van tcp voor aanzienlijk minder round trips die nodig zijn om een connectie tussen client en server te bewerkstelligen. Het opzetten van beveiligde ssl-verbindingen levert bij tcp bijvoorbeeld een flinke toename op van het aantal requests en antwoorden. Bij http-over-quic is ssl standaard geïmplementeerd en de huidige versie maakt gebruik van het nieuwe tls 1.3.
Door de afname van het aantal onderhandelingen tussen client en server verbetert http-over-quic de netwerklatency en kunnen webpagina's sneller laden. Http-over-quic is de implementatie van quic in het http-protocol, zoals Google die in juli 2016 als ontwerp-standaard in 2016 bij de IETF voorstelde.
Onder andere Chrome, Opera en Googles servers ondersteunen quic al. Daarnaast is Facebook begonnen met de adoptie, schrijft ZDNet.
/i/2000603310.png?f=imagenormal)

/i/2002191883.png?f=fpa)
/i/1260868188.png?f=fpa)
/i/1238489039.png?f=fpa)
/u/27299/hoofd.png?f=community)
:strip_icc():strip_exif()/u/71115/plus222.jpg?f=community)
:strip_icc():strip_exif()/u/78725/train-icon3.jpg?f=community)
:strip_icc():strip_exif()/u/25867/no_bugs_small.jpg?f=community)
/u/411828/crop576907a75c281.png?f=community)
/u/318832/Naamloos.png?f=community)
:strip_icc():strip_exif()/u/12461/crop65b195553d948.jpg?f=community)
/u/10064/leuk_he.png?f=community)
/u/512556/doranku.png?f=community)
/u/34556/welles60x60.PNG?f=community)
:strip_icc():strip_exif()/u/24792/74f128e7b84aec3866ab9eff6d09b097.jpg?f=community)
:strip_exif()/u/47900/baph.gif?f=community)
:strip_icc():strip_exif()/u/793705/crop57de4b2cc3582_cropped.jpeg?f=community)
/u/49730/babby%2520tux.png?f=community)
/u/1983/whiteButton.png?f=community)
:strip_icc():strip_exif()/u/174665/crop5f3505845c31b_cropped.jpeg?f=community)
/u/262016/crop64ed94e1a7757_cropped.png?f=community)
/u/107495/godzilla%252060x60.png?f=community)
:strip_icc():strip_exif()/u/289675/crop6401bf2c85501_cropped.jpg?f=community)
/u/112537/crop5e54218d79906_cropped.png?f=community)
/u/59144/aMSN_96.png?f=community)
{kind=link}
{kind=link}