Upgrade hier, upgrade daar
 Upgrades all around
Upgrades all around
Na de verhuizing naar Redbus bleef het op het servergebied lange tijd stil. De servers deden braaf hun werk, en performanceproblemen waren er nauwelijks. Toch bleef de site groeien en de hardware bleef verouderen. Begin 2005 was het dus weer zaak om met het serverpark aan de slag te gaan. Als eerste werden de bijna antieke 3Com-switches in het rack vervangen door twee gloednieuwe Procurve 2824-switches. Verder werd er geschoven met processors: een webserver had twee Opteron 284's aan boord, terwijl Apollo het met slechts een tweetal Opteron 242's moest doen. Het plan werd opgevat om deze te verwisselen, en dus schroefden we de kast van Apollo open om deze te verlossen van zijn trage Opterons. Ongewild kregen we hierbij inzicht in hoe onze serverbouwer met koelpasta omging: bij het aanbrengen van de nogal grote hoeveelheid koelpasta op de processoren zal vermoedelijk een plamuurmes zijn gebruikt en er kwam een rol wc-papier aan te pas om de overtollige pasta op te dweilen. Verder werd er een nieuwe webserver in het rack gehangen. Tijdens het configureren van de netwerkinstellingen van deze server kwamen wij erachter dat de kvm-switch ook een broadcastfunctie had: als je een server met een ctrl-alt-delete wilde rebooten, dan ging dat commando naar alle aangesloten hardware. Alle servers in het rack werden dus met een enkele druk op de knop opnieuw opgestart.
:fill(black)/i/1107262284.jpg?f=thumb)
:fill(black)/i/1107439943.jpg?f=thumb)
:fill(black)/i/1107439942.jpg?f=thumb)
:fill(black)/i/1089320183.jpg?f=thumb)
Besmeurde koelers, nieuwe switches en een broadcastende kvm
Nieuwe loadbalancers en kvm-over-ip
In februari 2005 werd ook de Brainforce-loadbalancer uitgerangeerd en aan Fok! gedoneerd. De nieuwe loadbalancers waren volledig in ons beheer, en we konden daardoor ineens veel meer, zoals ip-bans plaatsen en het verkeer loggen. De zelfbouwscripts die op deze servers draaiden, waren niet altijd vrij van bugs. Dat leidde enkele keren tot een korte downtime, maar over het algemeen deden ze hun werk beter dan hun commerciële voorganger.
In 2005 vonden verder weinig grote upgrades plaats. De servers hadden een behoorlijke overcapaciteit en draaiden allemaal stabiel. Dit blijkt ook uit de 'Server- & netwerkstatusmeldingen'-.plan uit die tijd; in plaats van dat we elke paar maanden een verse lijst moesten maken, konden we de .plan uit deze periode ruim een jaar lang gebruiken. Dat wil niet zeggen dat er niets gebeurde, maar wel dat de normale gebruiker weinig tot niets van de bezigheden merkte.
In 2006 naderde de werklast op de webservers weer het punt waarop een upgrade noodzakelijk was. Ter vervanging van de webservers kozen we deze keer voor twee Supermicro 1u-servers met elk twee dualcore Opteron 275-processors en 2GB geheugen. Ook werd de kvm-met-monitor vervangen door een nieuwer model, dat de mogelijkheid had om een kvm-over-ip module aan te sluiten. Op die manier konden we tot 32 servers aansluiten en via het internet bedienen, alsof we er achter zaten.
Tijdens het testen van de nieuwe Supermicro-servers, Aphaea en Astraeus, traden er vreemde problemen op. Hoewel de servers over exact dezelfde hardware beschikten, lukte het ons niet om Aphaea te installeren. Daarom werd in eerste instantie alleen Astraeus in het rack gehangen, maar toen die eenmaal in productie werd genomen zagen we ook bij deze bak veel segfaults en andere problemen langskomen. Bovendien leek hij soms data van de harde schijf te vergeten en raakten bestanden en folders zoek - en het is redelijk lastig om een server op afstand te beheren als hij ineens geen /bin-directory meer heeft. Na wat zoeken op het internet en debuggen bleek dat de onboard raidcontroller van Marvell niet goed met de toenmalige Linux-kernels overweg kon. Gelukkig hadden we de ruimte om losse pci-x-raid-controllers in de kasten te plaatsen. Er werd dus zorgvuldig een raidcontroller uitgezocht met een chipset die wel gewoon onder Linux wilde werken, en nadat er twee waren besteld en geïnstalleerd, waren alle problemen met deze servers ineens opgelost.
:fill(black)/i/1173795806.jpg?f=thumb)
:fill(black)/i/1139844987.jpg?f=thumb)
:fill(black)/i/1139844986.jpg?f=thumb)
:fill(white)/i/1222952761.jpg?f=thumb)
Nieuwe kvm-switches, nieuwe loadbalancers en kvm-over-ip-module
Doorschuiven, Dell en Sun
Dell-databaseserver
2006 luidde het einde in voor de zelfbouw- en barebonemachines: vanaf dit jaar werden er alleen maar complete nieuwe servers aangeschaft. We waren het gezeik met incompatible hardware, niet passende spullen en instabiele configuraties nogal zat. Bovendien konden we onder VNU-vlag gebruik gaan maken van vrij gunstige inkoopcondities zodat er ook geen financieel argument meer bestond voor het aanschaffen van gammeler systemen. Een van de eerste machines die aldus werd aangeschaft was Apollo, de forum-databaseserver die het tot dan toe regelmatig erg zwaar had. Ook werd het plan gemaakt om alle Slackware- en Suse-machines over te zetten naar Debian, omdat we slechts één distro wilden gebruiken, Suse nooit onze favoriet was geworden en Slackware op dat moment niet al te best onderhouden werd. De keuze viel dus op Debian en het hele serverpark zou daarop gaan draaien.
De oude Apollo draaide nog op Suse omdat het een van de eerste Opteron-servers in ons rack was en er destijds geen fatsoenlijk alternatief beschikbaar was. Bij Dell werd een nieuwe Apollo besteld met behoorlijke specificaties: in plaats van vijf scsi-schijven in raid-5 en een hotspare, kregen we nu de beschikking over veertien sata-schijven, wederom in raid-5 en wederom met een hotspare. Deze veertien 36G-schijven werden niet gekocht omdat we te weinig ruimte hadden, maar puur omdat veertien schijven veel beter presteren dan vijf stuks. Ook de hoeveelheid intern geheugen werd verdubbeld, van 8GB in de oude Apollo naar 16GB in de nieuwe. Al met al bleek de nieuwe server bijna tweemaal zo snel te zijn als het afgedankte exemplaar.
:fill(black)/i/1160396432.jpg?f=thumblarge)
:fill(black)/i/1183583814.jpg?f=thumblarge)
Apollo met enclosure
Dell-webservers en downtime
Tijdens het uit het rack halen van Apollo bleek dat een van onze masterswitches op sterven na dood was: af en toe besloot hij een paar seconden geen stroom meer aan de servers te geven. Na de eerste stroomuitval gingen alle servers netjes weer aan, waaronder de databaseserver Artemis. Tijdens de tweede stroomuitval was deze echter net bezig met het recoveren van de database. Het gevolg laat zich raden: database kapot en serverbeheerders die tot ruim 3 uur 's nachts bezig zijn om te redden wat er te redden valt.
De oude Apollo werd meegenomen naar het kantoor, waar deze van nieuwe processors, nieuw geheugen, snellere harde schijven en een verse Debian-installatie werd voorzien. Enige tijd later verving hij Artemis als databaseserver.
Ook werden er bij Dell twee nieuwe webservers aangeschaft - Alectrona en Adrastos - met vrijwel dezelfde hardware als Apollo. Dit werd gedaan zodat, als Apollo de geest zou geven, we een van de webservers redelijk gemakkelijk op de MD1000 konden aansluiten om de taken van Apollo over te nemen. Bij het in het rack hangen van deze servers bleek hoe handig het kan zijn om een kabel die van een server naar een externe enclosure loopt, vast te schroeven, zodat je hem niet per ongeluk uit de server stoot op het moment dat je onderhoud aan de servers pleegt. Gevolg: weer een nachtelijke forumdatabase-reddingsoperatie en weer een nacht met te weinig slaap.
:fill(black)/i/1163505864.jpg?f=thumb)
:fill(white)/i/1222954713.jpg?f=thumb)
:fill(black)/i/1164885362.jpg?f=thumb)
:fill(black)/i/1164885184.jpg?f=thumb)
Dell-webservers en databaseserver-downtime
Geschenk van Sun en upgrades
De oude Artemis verhuisde wederom naar kantoor voor een herinstallatie en wat opfrishardware. Deze server kwam op 2 februari 2007 onder de naam Asclepius terug in het rack en kreeg daar de taak van webserver en Postgresql-databaseserver. De server paste maar net in ons rack - blijkbaar is 19" bij de ene fabrikant net wat groter dan bij de andere. Tijdens de installatie van Asclepius wilden we ook de backupserver Athena van een tweede processor voorzien, maar dit feest ging helaas niet door: we hadden wel een processor en een koeler meegenomen, maar er bleek geen houder voor die koeler op het moederbord aanwezig te zijn.
In juli 2006 publiceerde Tweakers.net een review van een Sun T2000. Deze server hadden wij via het try & buy-programma van Sun geleend en getest. Aan dit programma zat echter ook een wedstrijd vast; eens per maand bekeek een jury van Sun alle ingezonden reviews, en de winnaar kreeg een gratis Sun-server. Hoewel de T2000 in onze test niet erg goed scoorde, vond de jury ons verhaal toch dermate goed dat wij een Sun Fire X4200 wonnen. Dit leek ons een mooie bak om onze oude mailserver Adonis door te vervangen, en op 9 maart 2007 werd deze aanwinst in het rack gehangen. Naast het plaatsen van de nieuwe Adonis deden we weer een poging om een extra processor in Athena te plaatsen. Dat was al eens mislukt omdat we geen koeler bij ons hadden en de tweede keer bleek er dus geen bracket op het bord te zitten. Driemaal bleek scheepsrecht: deze keer hadden we een processor, een koeler en een bracket bij ons. De tweede processor van Athena draait sindsdien rustig mee.
:fill(black)/i/1170679547.jpg?f=thumb)
:fill(black)/i/1170679856.jpg?f=thumb)
:fill(black)/i/1173795593.jpg?f=thumb)
:fill(white)/i/1222954657.jpg?f=thumb)
:fill(white)/i/1222954969.jpg?f=thumb)
:fill(black)/i/1172587547.jpg?f=thumb)
:fill(black)/i/1172587550.jpg?f=thumb)
:fill(black)/i/1173795592.jpg?f=thumb)
Nieuwe mailserver van Sun, problemen met upgraden en vervanging van brakke masterswitches
Naar Eunetworks
In de zomer van 2006 was ons rack weer een enorme rotzooi geworden: goede bedoelingen om het rack netjes te houden blijken niet bestand tegen regelmatig onderhoud aan de servers. Toen we net bij Redbus zaten, hadden we bijvoorbeeld amper servers met meer dan één voeding, nu had bijna elke server redundante psu's. Ook de toevoeging van de kvm-switch had geen positieve invloed op de kabelbrij achter in het rack. Bovendien hadden we alle vier de masterswitches bovenin het rack gehangen zodat we veel en lange netstroomkabels moesten gebruiken. Al met al was situatie niet erg werkbaar meer, wat zich opnieuw vertaalde naar kabels die uit servers vielen, stroomkabels die losschoten en masterswitches die spontaan overleden.
Ook het stroomverbruik in ons rack was iets aan de hoge kant. Redbus hanteerde een limiet van 8 ampère per rack, terwijl ons rack inmiddels een dikke 21 ampère opsoupeerde. Als we bij Redbus zouden blijven, hadden we onze servers over drie racks moeten verdelen. Gelukkig had True een oplossing: in plaats van een drietal racks bij Redbus, mochten we er twee bij Eunetworks betrekken waar we per rack 14 ampère konden gebruiken. Ook waren de racks dieper, zodat we onze kabelbrij nog beter konden wegwerken.
Om de verhuizing zo soepel mogelijk te laten verlopen werd er besloten om een heleboel hardware te vernieuwen. De horizontale masterswitches, die regelmatig voor problemen zorgden, werden vervangen door een viertal verticale masterswitches. Het netwerk zou worden uitgebreid met twee nieuwe Procurve 2900-switches zodat we een 20Gbps-verbinding tussen de twee racks konden aanleggen en de loadbalancers, die het erg zwaar hadden, zouden worden vervangen door twee nieuwe Dell-machines. Verder werd er een lade in het rack opgehangen zodat wij een plaats hadden om onze kabels en schroevendraaiers netjes op te bergen. Als laatste werden bijna alle stroom- en netwerkkabels nieuw gekocht zodat we het netwerk een betere kleurcodering konden geven en zodat we geen kabels van twee meter hoefden te gebruiken voor een afstand van 50 centimeter.
Nadat de beide racks op Eunetworks van deze nodige gadgets waren voorzien, werd de verhuizing gepland en op 30 juni 2007 uitgevoerd. Gelukkig bleef Murphy deze keer van onze hardware af en alle servers overleefden de reis door Amsterdam. Dit alles werd door talloze nieuwsgierige tweakers via webcams gevolgd. Minder gelukkig waren de nieuwe loadbalancers: door een bug in de kernel crashten deze als er aan enkele zeer specifieke voorwaarden werd voldaan. Deze voorwaarden traden met onze hoeveelheid dataverkeer echter om de paar uur op, waardoor we in allerijl de oude loadbalancers weer in het rack moesten hangen.
In eerste instantie was het ook de bedoeling dat we vlak voor de verhuizing de nieuwe Artemis in een Eunetworks-rack zouden hangen. Tijdens tests bleek de server echter erg vreemd gedrag te vertonen. Met behulp van de Dell-support werd het probleem geanalyseerd en dat leidde uiteindelijk tot het vervangen van het moederbord. Na deze vervanging bleek de nieuwe Artemis stabiel en kon hij het rack in als vervanging van de oude Artemis. Op 28 juli 2007 nam hij zijn taken ook daadwerkelijk over. In de winter van 2007 probeerden wij fileserver Atlas te vervangen. Voor dit doel werd een IBM-server aangeschaft en in het rack gehangen. Helaas bleek deze niet stabiel te krijgen en werd hij al snel weer uit het rack gehaald.
:fill(black)/i/1183584581.jpg?f=thumb)
:fill(black)/i/1183584605.jpg?f=thumb)
:fill(black)/i/1183584311.jpg?f=thumb)
:fill(black)/i/1183583962.jpg?f=thumb)
:fill(black)/i/1183584191.jpg?f=thumb)
:fill(black)/i/1183584136.jpg?f=thumb)
:fill(black)/i/1183583851.jpg?f=thumb)
:fill(black)/i/1160396433.jpg?f=thumb)
Korte impressie van de verhuizing en de nieuwe Artemis
Loadbalancers
Hoewel het grootste deel van deze reviews chronologisch is, willen we toch van enkele servers apart de geschiedenis bekijken. Voordat we aan de fileservers beginnen, behandelen we de geschiedenis van onze loadbalancing-pogingen.
Loadbalancing: de eerste stapjes
Al vanaf het prille begin bestonden er plannen voor loadbalancing. In eerste instantie probeerden we het op de webservers zelf op te lossen met mod_backhand, en later met Squid. Deze oplossingen bleken echter niet makkelijk te schalen, en beide hadden een negatief effect op de performance van de webservers. In 2001 kregen we steeds meer webservers, en het verdelen van de werklast over deze servers werd steeds moeilijker. In eerste instantie kon er nog gewoon met verschillende onderdelen geschoven worden - het forum op de ene, en de frontpage op de andere server - maar zodra er een server uitlag, was ook dat onderdeel niet meer te bereiken. Ook Fok! werd steeds groter, en zodoende kwamen er steeds meer servers in het rack te hangen.
Na een korte periode met round-robin-dns gewerkt te hebben, werd besloten dat ook dit niet ideaal was: er moest een meer gestructureerde oplossing voor dit probleem komen. Via een sponsor kregen wij een 1u-server toegeschoven met een matx-bordje en een PIII die op 700MHz draaide. Deze zou door middel van LVS en iptables de loadbalancer en firewall worden voor de Tweakers.net-sites. Deze machine bleek echter al tijdens het testen zo instabiel te zijn en zo vaak vast te lopen, dat we maar meteen besloten om deze hardware af te danken.
Brainforce
Een nieuwe sponsor, loadbalancerfabrikant Brainforce, wilde ons wel wat hardware cadeau doen. In eerste instantie ging het om twee loadbalancers die in een 'High Availabilty'-opstelling werkten, maar de IBM-servers waarop dit platform draaide, bleken zo stabiel te zijn, dat we besloten om maar één server te nemen en de tweede terug te sturen. Voordat deze loadbalancers stabiel liepen moesten we in samenwerking met Brainforce wel enkele keren de software updaten. In de eerste versie die we in gebruik namen, was het bijvoorbeeld niet mogelijk om configuratiewijzigingen op afstand uit te voeren en moesten alle veranderingen lokaal worden doorgevoerd. Ook beschikte de loadbalancer niet over een firewall, en werden connecties vanuit de servers zelf niet doorgestuurd. Na uiteindelijk versie 1.3 van de software te hebben geïnstalleerd, was het tijd voor een echte test. Op dat moment liep de bèta-test van de React-forumsoftware, en deze omgeving bleek ideaal om te testen. De test verliep met succes en toen de forumsoftware van React in gebruik werd genomen, werden ook meteen de loadbalancers aangeslingerd. Vanaf dat moment was onze cluster echt een cluster: als een webserver down ging, draaide de site gewoon verder op de andere webservers.
Zelfbouw-loadbalancers
Deze Brainforce loadbalancers deden precies wat ze behoorden te doen, maar niet meer dan dat. In de periode na de ingebruikname kregen wij met enige regelmaat grote ddos-aanvallen over ons heen maar op de loadbalancers, waar het verkeer wel werd tegengehouden, konden we alleen waarnemen dat het verkeer er was en niet waar het vandaan kwam. Daarom werd besloten om ook dit gedeelte weer in eigen beheer op te lossen. MSI werd bereid gevonden om twee moederborden met een Serverworks-chipset, een op 1GHz geklokte PIII en 512 MB Dane Elec-geheugen te sponsoren. De vreugde over deze professionele moederborden was echter van korte duur: al snel na de installatie van Linux bleek dat, zodra de loadbalancer-to-be langer dan twee dagen aanstond, deze onherroepelijk vastliep door een bug in de driver voor de chipset. Ook deze hardware was dus niet geschikt voor een server waarvan we een hoge uptime verwachtten.
:fill(black)/i/1063809078.jpg?f=thumblarge)
:fill(black)/i/1031007039.jpg?f=thumblarge)
Brainforce loadbalancers en hardware die deze had moeten vervangen
Celeron-loadbalancers
Uiteindelijk werden bij Melrow twee Celeron-servers besteld die als loadbalancer dienst moesten doen. Deze servers bleken uitermate stabiel, maar niet erg snel. De software die op deze servers draaide was een mix van zelfgeschreven scripts en Linux Virtual Server-kernelmodules. Tussen het installeren en de ingebruikname van deze servers zat een behoorlijk lange tijd, mede veroorzaakt door een bug in een van de gebruikte kernelmodules. Na zeer veel debuggen werd de fout eindelijk gevonden en gefixt. In de nacht van 16 februari 2005 werden de eerste servers overgezet en al snel verdeelden deze loadbalancers alle requests over alle webservers, met als grote voordeel dat wij nu direct toegang hadden tot de servers, en zodoende ook mensen een ip-ban konden verkopen en veel beter het verkeer naar ons rack konden debuggen.
Dell-loadbalancers
Na de introductie van de nieuwe lay-out werd al snel duidelijk dat deze loadbalancers kracht tekort kwamen om al het verkeer te dirigeren. Zodra de hoeveelheid traffic naar ons rack boven de 50 megabit per seconde kwam, werd de processor volledig belast, wat kort na de introductie van de nieuwe lay-out tot veel downtime leidde. Dit was uiteraard niet acceptabel, en daarom werden er bij Dell snel twee nieuwe machines besteld. Deze loadbalancers beschikken elk over een Intel Xeon-quadcore met 2GB geheugen. Ze werden als eerste servers in het nieuwe rack op Eunetworks gehangen, en toen de rest van de servers eenmaal verhuisd was, werden ze in gebruik genomen. Helaas bleek direct na de ingebruikname dat deze servers niet stabiel waren; zodra aan een zeer specifieke conditie werd voldaan hingen ze zichzelf op. Met enige spoed werden de oude loadbalancers weer in het rack gehangen en aangeslingerd, terwijl wij de kernel debugger weer van stal haalden. Ook deze keer bleek het om een fout in de LVS-code te gaan, en nadat er een kleine patch upstream was gestuurd, konden we deze servers weer in gebruik nemen. Tot op de dag van vandaag verdelen zij braaf de werklast over de webservers.
:fill(white)/i/1222099332.jpg?f=thumblarge)
:fill(white)/i/1222099355.jpg?f=thumblarge)
Oude en huidige loadbalancers
Fileservers
Tweakers.net en Fileservers
:fill(black)/i/1008385580.jpg?f=thumb) Centrale opslag van alle data die bij Tweakers op de servers staat, stond al vanaf het begin op ons verlanglijstje. In eerste instantie werd gedacht aan een filesystem als Coda, maar dat bleek niet aan onze verwachtingen te voldoen - zelfs de developers van Coda vonden het destijds nog niet verstandig om Coda in productiesystemen te gebruiken. We besloten de simpelste oplossing te kiezen en hingen een nfs-server in het rack bij Telecity. Voor dit doel werd een Gigabyte-server gesponsord door hardware.nl, maar al snel bleek Atlas, zoals deze machine werd gedoopt, daar niet geschikt voor te zijn. Na vele crashes werd de server teruggestuurd naar Gigabyte en zijn taken werden door een van de webservers overgenomen.
Centrale opslag van alle data die bij Tweakers op de servers staat, stond al vanaf het begin op ons verlanglijstje. In eerste instantie werd gedacht aan een filesystem als Coda, maar dat bleek niet aan onze verwachtingen te voldoen - zelfs de developers van Coda vonden het destijds nog niet verstandig om Coda in productiesystemen te gebruiken. We besloten de simpelste oplossing te kiezen en hingen een nfs-server in het rack bij Telecity. Voor dit doel werd een Gigabyte-server gesponsord door hardware.nl, maar al snel bleek Atlas, zoals deze machine werd gedoopt, daar niet geschikt voor te zijn. Na vele crashes werd de server teruggestuurd naar Gigabyte en zijn taken werden door een van de webservers overgenomen.
Compaq ML530 Atlas
Omdat ook deze webserver niet ideaal was, werd gezocht naar een andere oplossing. In de tussentijd mochten we van True een Netapp F740 lenen om als fileserver te gebruiken. Deze Netapp is een volwaardige fileserver, maar op een of andere manier kregen we het toch voor elkaar om deze bak vrijwel elke dag te laten crashen. Aangezien we de Netapp bovendien maar tijdelijk konden gebruiken, moest er een meer permanente nfs-server komen. Deze werd uiteindelijk gesponsord door hardware.nl in de vorm van een Compaq ML530, die wederom Atlas werd genoemd. Ook deze Atlas was niet heel erg stabiel, dus moesten we allerlei oplossingen bedenken om de site redelijk bereikbaar te houden in het geval van een crash. De hardware van Atlas heeft ons ook een aantal scsi-schijven gekost; zodra een schijf in een bepaalde bay geplaatst werd was het een kwestie van enkele dagen voordat de raidcontroller die doodverklaarde. Toch was deze server stabieler dan de andere oplossingen die we eerder gebruikten, met name toen de problemen met de schijven opgelost werden.
De enorme omvang van het apparaat was wel een heikel punt: de ML530 nam maar liefst 7u in. Ter vergelijking: de databaseservers die wij op dat moment hadden waren slechts 2u hoog. Ook werden de schijven op de server steeds voller. We bleven weliswaar schijven bijplaatsen, maar op een moment waren alle bays gevuld met 36GB scsi-schijven. Besloten werd om de taken van deze machine over drie servers te verdelen. Aphrodite zou een rentree maken en de zoekmachine overnemen die toen op Atlas draaide. Athena zou de backuptaken van Atlas overnemen en kreeg daarvoor de beschikking over twaalf 160GB sata-schijven. De opvolger van Atlas zou zich puur met het serveren van files bezig gaan houden en daar acht 74GB-Raptors voor krijgen. Dankzij deze setup hadden wij veel meer ruimte voor backups, veel meer geheugen voor de zoekmachine en voldoende capaciteit op de fileserver. De oude ML530 werd uit het rack gehaald en in 2007 op een meeting door de crew 'beloond' voor de vele uren aan downtimes, kapotte schijven en verloren data. Zelfs op dit feestje ter ere van hem, kon Atlas het niet nalaten om nog een laatste keer een stuk hardware te vernielen.
:fill(black)/i/1067889539.jpg?f=thumb)
:fill(white)/i/1221494851.jpg?f=thumb)
:fill(white)/i/1222176067.jpg?f=thumb)
:fill(white)/i/1222176095.jpg?f=thumb)
Atlas: begin en einde, en zijn laatste slachtoffer
IBM Atlas en toekomst
Hoewel we nu veel meer ruimte hadden, besloten we toch om deze server weer te vervangen door een IBM-machine met 4TB aan ruimte, snellere processoren en meer geheugen. Helaas bleek met deze IBM ons oude geluk weer terug te keren: hij was uitermate instabiel, en zodra het geheugengebruik over de 4GB kwam liep hij onherroepelijk vast. Toen bleek dat we de server bijna dagelijks moesten herstarten, werd besloten om de oude server, die nog in het rack hing, voorlopig weer in te zetten als fileserver en naar een betere oplossing te zoeken. De IBM-helpdesk raadde ons ondertussen aan om de firmware van de backplane te upgraden - dit had inderdaad als gevolg dat de bak niet meer vastliep vanwege het geheugengebruik, sterker nog, na deze upgrade kon de IBM-server niet eens meer voorbij het post-scherm komen.
De toekomst moet ons leren of de oplossing waar wij nu aan werken een betere oplossing wordt dan wat we nu hebben (wij denken uiteraard van wel). In ieder geval heeft de toekomstige oplossing met 6TB weer meer ruimte en zal nfs worden ingeruild voor gfs. Binnenkort zal deze oplossing de huidige Atlas gaan vervangen.
:fill(white)/i/1222179778.jpg?f=thumb)
:fill(white)/i/1222179807.jpg?f=thumb)
:fill(white)/i/1222179790.jpg?f=thumb)
:fill(white)/i/1222180061.jpg?f=thumb)
Twee nieuwere generaties Atlas
Veel gestelde vragen en statistieken
Bij onze .plans en reviews over het serverbeheer krijgen wij nog aardig veel vragen. Hieronder proberen we een paar van de vaakst gestelde vragen te beantwoorden.
Wat gebeurt er met oude hardware?
Dat hangt ervan af of wij die hardware nog kunnen gebruiken, of het nog werkt en of iemand het wil. Servers die nog goed functioneren, kunnen bijvoorbeeld op het kantoor in een rack belanden, om daar bijvoorbeeld te dienen als testserver of als client voor databasetests. Sommige servers worden verkocht of, als niemand er echt belangstelling voor heeft, weggegeven. De servers die ons veel problemen hebben bezorgd, krijgen een speciale behandeling en zijn dan rijp voor de afvalcontainer. Ook komen er wel eens onderdelen bij een serverbeheerder thuis in de kast terecht, waar ze dan jaren liggen te rotten.
:fill(white)/i/1222950378.jpg?f=thumb)
/i/1222950407.png?f=thumb)
:fill(white)/i/1222950445.jpg?f=thumb)
Verschillende manieren om van hardware af te komen
Waarom doen jullie je werk niet 's nachts?
Het korte antwoord: slechte ervaringen. Het iets langere antwoord: upgrades en verhuizingen nemen vaak een hele nacht in beslag. In theorie is dat mogelijk, maar ervaringen uit het verleden hebben ons geleerd dat als je een hele dag bezig bent met voorbereidingen en het plan vervolgens 's nachts uitvoert, je op het einde redelijk moe bent. Er worden dan ook meer fouten gemaakt dan wanneer je het werk na een goede nachtrust doet. Er zijn serverupgrades geweest waar we om 9 uur 's avonds begonnen en pas de volgende dag om 1 uur 's middags thuis waren - om meteen weer achter de computer te kruipen, omdat er toch nog iets fout was gegaan wat we tijdens de werkzaamheden nog niet hadden opgemerkt.
Zijn jullie wel eens aangevallen?
Ja. In eerste instantie ging het om een tweetal bezoekers van de site die een zwak wachtwoord van een crewlid wisten te vinden om vervolgens via de backend access tot de servers wisten te verkrijgen. Deze hack was redelijk goedaardig en er werden geen al te gekke dingen gedaan. Er werd wel een 'review' geplaatst waarin ons werd uitgelegd dat de beveiliging van de site niet geheel afdoende was.
Soms lukte het de scriptkiddies ook om onze site plat te leggen. Een voorbeeld hiervan is de deface in de zomer van 2001. Een te standaard Slackware-installatie met een exploitable telnet zorgde er voor dat wij gehackt werden. Deze hackers sloegen midden in de nacht toe (en dat was natuurlijk smullen voor onze concurrenten), maar de deface was van korte duur. Ondanks het tijdstip waren de meeste webpagina's binnen enkele minuten weer hersteld en binnen een half uur was uitgevonden hoe ze binnen waren gekomen en was het lek gedicht. Uit de verklaring van de hackers bleek dat ze ons graag een lesje wilden leren. Dat lesje hebben wij hopelijk geleerd, want het was de laatste keer dat er iemand serieus het serverpark is binnengedrongen.
Niet alleen hackpogingen zorgden voor overlast, sommige mensen vonden het blijkbaar nodig een ddos-aanval op Tweakers.net uit te voeren. Dit gebeurde een aantal keren en bij de grootste ddos waren we ruim een halve dag offline omdat er 5Gbps aan verkeer op ons 100Mbps-lijntje werd afgevuurd. Een aantal van deze aanvallen werden gepleegd door bij ons bekende personen. Hoewel we van deze personen de adresgegevens konden achterhalen, heeft een aangifte bij de politie tot op de dag van vandaag nog maar weinig effect gesorteerd.
Tegenwoordig worden wij bijna niet meer aangevallen. Soms probeert iemand om ons plat te leggen door heel veel pagina's heel langzaam op te vragen, maar dat is redelijk eenvoudig te blokkeren. Aanvallen waarbij grote hoeveelheden verkeer onze kant op gestuurd worden behoren (hopelijk) tot het verleden.
Waar kan ik meer lezen over het serverbeheer?
Een goede plek om daarmee te beginnen zijn onze 'Server- en netwerkstatusmeldingen' .plans die wij sinds 12 maart 2002 bijhouden:
Server- en netwerkstatusmeldingen I: 12-03-2002 - 25-08-2002
Server- en netwerkstatusmeldingen II: 01-09-2002 - 16-10-2002
Server- en netwerkstatusmeldingen III: 05-12-2002 - 22-06-2003
Server- en netwerkstatusmeldingen IV: 24-06-2003 - 28-01-2004
Server- en netwerkstatusmeldingen V: 10-02-2004 - 07-12-2004
Server- en netwerkstatusmeldingen VI: 08-12-2004 - 01-02-2006
Server- en netwerkstatusmeldingen VII: 07-02-2006 - 11-12-2006
Server- en netwerkstatusmeldingen VIII: 28-03-2007 - 19-12-2007
Server- en netwerkstatusmeldingen IX: 18-01-2008 - heden
Statistieken
Wij Tweakers zijn dol op statistieken. De meeste statistieken kan je al op de site terugvinden, maar hieronder hebben we er toch nog een paar voor je gebakken om de groei van ons serverpark weer te geven.
| Hoeveelheid | Begin 2001 | Vandaag | Groei |
|---|
| Servers | 3 | 16 | 533% |
| Processoren | 4 | 28 | 700% |
| Cores | 4 | 54 | 1350% |
| MHz | 3066MHz | 136.960MHz | 4467% |
| Geheugen | 2432MB | 86.016MB | 3536% |
| Harddisks | 8 | 104 | 1300% |
| Diskruimte | 110GB | 17.129GB | 15572% |
De serverpower aan het begin van de hostingsgeschiedenis vs. nu
Wat brengt de toekomst?
Zoals je al wel opgemerkt hebt is deze review redelijk snel over 2007 en 2008 heen gegaan. Dit is niet omdat wij niets doen, maar grotendeels te wijten aan onze developers. Hadden wij vroeger nog regelmatig last van een overbelaste databaseservers en webservers, tegenwoordig slagen de developers erin om meer mensen per dag, met minder queries en minder cpu-tijd te voorzien van een mooiere pagina. Ook het gebruik van juiste cache-headers en het inzetten van aparte software voor statische requests leidde tot een daling van de werklast terwijl het aantal pageviews bleef stijgen.
Dankzij alle serverupgrades en vernieuwingen waarover je de afgelopen tijd hebt kunnen lezen, hoeven wij vrijwel nooit meer naar de colocatie toe. Bijna alles kan vanuit kantoor of huis beheerd worden; we zijn eigenlijk alleen nog in de serverruimte te vinden als we nieuwe hardware moeten plaatsen of onderdelen moeten vervangen. Uiteraard blijven we het serverpark monitoren en waar nodig upgraden: zo wordt binnenkort de filedistributie aangepakt, waardoor vrijwel alle servers weer naar nul dagen uptime gaan. Een verbouwing waarbij we alle servers van een nieuw moederbord voorzien zal echter niet meer voorkomen; dat behoort nu tot de Tweakers.net-geschiedenis.











:fill(black)/i/1163505864.jpg?f=imagegallery)

































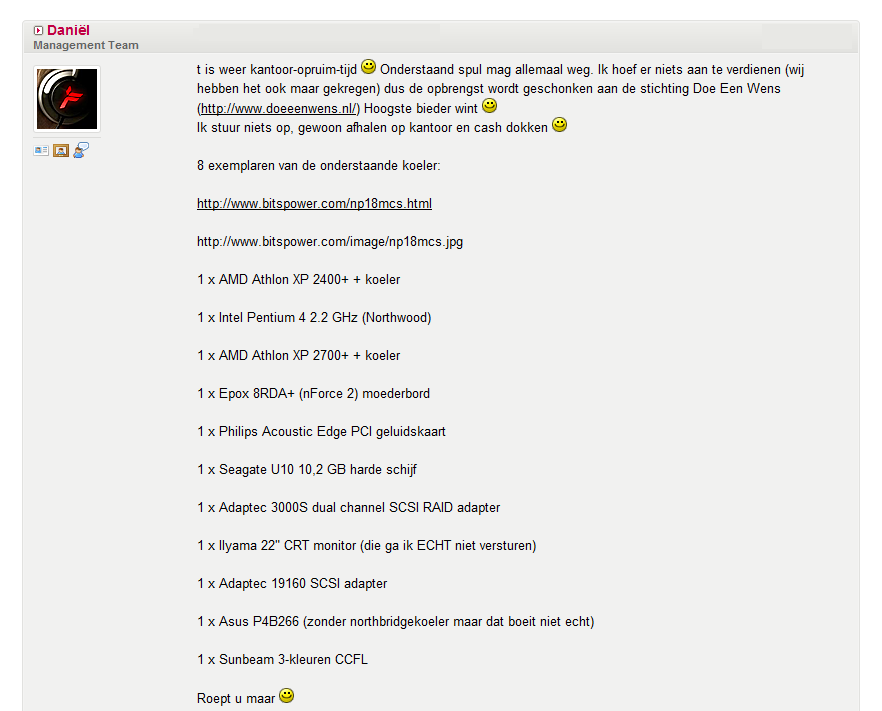

:strip_icc():strip_exif()/i/2003096314.jpeg?f=fpa_thumb)
:strip_icc():strip_exif()/i/2001246513.jpeg?f=fpa_thumb)

:strip_icc():strip_exif()/u/174221/crop622fcedcbc717_cropped.jpg?f=community)
/u/8/oog3.png?f=community)
:strip_icc():strip_exif()/u/135404/crop586e284093763_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/961/crop69b8f434281b1_cropped.jpg?f=community)
/u/80078/iconiPad.png?f=community)
:strip_exif()/u/38491/klus.gif?f=community)
:strip_icc():strip_exif()/u/155215/krijg-ik-een-cola.jpg?f=community)
:strip_icc():strip_exif()/u/3550/S2462.jpg?f=community)
:strip_icc():strip_exif()/u/31/netapp.jpg?f=community)
/u/1830/acm.png?f=community)
:strip_exif()/u/262703/Untitled-1.gif?f=community)
/u/208637/crop586544c351249_cropped.png?f=community)
/u/145838/2095.PNG?f=community)