
Al eeuwen gaat er in het feudale Japan de poëzievorm haiku rond. In de afgelopen twee, drie decennia zijn systeembeheerders vooral bekend geraakt met een bekend vijf-zeven-vijf-lettergrepengedicht:
It's not DNS
There's no way it's DNS
It was DNS
Ook na maandagavond was dat weer relevant. DNS-records voor Facebook-diensten wezen niet meer naar de juiste plekken en zorgden voor een ongekend grote en langdurige chaos op internet. Inmiddels blijkt dat het Japanse rijm kan worden bijgewerkt:
Wat is BGP?
Is het echt zo belangrijk?
Oh ja... Blijkbaar wel.
BGP staat voor het border gateway protocol. Het protocol is al oud, maar zeker niet versleten. Het is daarentegen wel een goed voorbeeld van hoe het internet toch nog steeds met veel kunst- en vliegwerk in de lucht wordt gehouden. Er zijn inmiddels ook wat aanwijzingen dat Facebook zelf slecht voorbereid was op een dergelijke storing.
Na publicatie kwam Facebook met een nadere verklaring. Die is als update in het artikel verwerkt.
Wat gebeurde er?
Eerst maar eens de feiten. Facebooks grote storing begon om 17.40 Nederlandse tijd, toen bezoekers van de site en de app alleen nog een draaiend tandwieltje te zien kregen. Al snel bleken ook andere Facebook-diensten offline te zijn. De eigen berichtendienst Messenger deed niks meer, net als dochterdiensten Instagram en WhatsApp. Wie dacht met de vrije tijd dan maar lekker wat te gaan gamen met een Oculus-VR-headset kwam ook van een koude kermis thuis. De Oculus-diensten konden namelijk eveneens niet opstarten. Offline spelen op de headset kon nog wel, maar alles dat via de servers van Oculus moest, werkte niet.
Het werd snel duidelijk dat de storing veel groter was dan verwacht. Een algemene storing bij het complete portfolio van Facebook is al zeldzaam, maar zo'n langdurige al helemaal. Uiteindelijk duurde het meer dan zes uur voor de sociale netwerken weer enigszins bruikbaar waren. Om 23.50 meldde Facebook dat de diensten weer online kwamen. Dat duurde ook nog eens lang, want al die achterstallige berichten moesten in een keer worden verstuurd en dat leidde tot vertraging op de netwerken.
De storing was grootschalig. Bij dergelijke storingen is het normaal dat er veel vertraging is, of dat een website wel laadt met een errorcode, of dat de dienst wel laadt maar de content niet. Dat was nu niet het geval. Sommige experts zeggen het treffend: het leek alsof Facebook verdwenen was van internet.
Onduidelijkheden
/i/2004668684.png?f=imagenormal) De officiële communicatie vanuit Facebook en Instagram was summier. Die beperkte zich tot wat vage tweets zonder een oorzaak aan te wijzen. Ook in de officiële verklaring die Facebook achteraf gaf, staat niet veel concrete informatie. "We hebben geleerd dat de communicatieproblemen werden veroorzaakt door een configuratieaanpassing in de backbone-routers die netwerkverkeer versturen tussen onze datacenters", schreef het bedrijf. En dat het 'een domino-effect had op de manier waarop de datacentra communiceerden'. Dat lijkt te wijzen op een storing met betrekking tot het border gateway protocol zoals veel werd gespeculeerd, maar het is daar geen officiële bevestiging van.
De officiële communicatie vanuit Facebook en Instagram was summier. Die beperkte zich tot wat vage tweets zonder een oorzaak aan te wijzen. Ook in de officiële verklaring die Facebook achteraf gaf, staat niet veel concrete informatie. "We hebben geleerd dat de communicatieproblemen werden veroorzaakt door een configuratieaanpassing in de backbone-routers die netwerkverkeer versturen tussen onze datacenters", schreef het bedrijf. En dat het 'een domino-effect had op de manier waarop de datacentra communiceerden'. Dat lijkt te wijzen op een storing met betrekking tot het border gateway protocol zoals veel werd gespeculeerd, maar het is daar geen officiële bevestiging van.
Een andere zin uit Facebooks verklaring trekt ook de aandacht. "De onderliggende oorzaak van deze storing had impact op veel van onze interne tools en systemen die we gebruiken in ons dagelijkse werk. Dat maakte het diagnosticeren en oplossen van het probleem moeilijker." De reden dat de storing dus zo uitzonderlijk lang duurde had te maken met het feit dat Facebook ook zelf niet op zijn platformen kon. Omdat de interne communicatie niet werkte, konden medewerkers niet op Workplace, het enterpriseplatform van Facebook dat medewerkers uiteraard ook intern gebruiken. Ook interne beveiligingstools zouden niet hebben gewerkt. Volgens een interne memo waar The New York Times de hand op wist te leggen werd de storing door Facebook geclassifiseerd als 'HIGH risk' voor mensen' en 'HIGH risk' voor de reputatie van het bedrijf.
De krant schrijft ook dat het werk bemoeilijkt werd omdat veel digitale keycards niet meer werkten. Daarvoor konden medewerkers niet bij vergaderzalen en andere gebouwen. De verstoring van de fysieke en digitale samenwerking maakte het oplossen van het probleem ingewikkeld. Uiteindelijk zouden werknemers fysiek naar een datacentrum in Santa Clara hebben moeten reizen om daar een handmatige reset uit te voeren. Er ging zelfs een gerucht dat Facebook een slijptol nodig had om de serverruimtes binnen te komen, maar dat bleek uiteindelijk niet te kloppen.
Update, 20:30: Facebook geeft nadere uitleg
Inmiddels heeft Facebook een veel uitgebreidere verklaring online gezet. Daarin omschrijft Facebook hoe dit heeft kunnen gebeuren. Het ging mis tijdens regulier onderhoud aan de backbone. "Een commando werd gegeven met de intentie om in kaart te brengen hoe het zat met de wereldwijde beschikbaarheid van de capaciteit van de backbone. Die trok onbewust alle verbindingen in het backbone-netwerk offline en ontkoppelde als het ware alle datacentra van Facebook wereldwijd. Onze systemen zijn ontworpen om dit soort foutieve commando's tegen te houden om zo fouten als deze tegen te gaan, maar door een bug in de audit-tool gebeurde dat niet."
Die ene fout zorgde voor een tweede fout bij kleinere datacenters, die ook zorgen voor afhandeling van DNS-verzoeken. "Om te zorgen dat die betrouwbaar werken, trekken ze BGP-advertisements in als ze niet kunnen communiceren met onze datacenters." Die BGP-advertisements zorgen ervoor dat andere netwerken de Facebook-diensten kunnen vinden op internet. "Het eindresultaat was dat onze DNS-servers onbereikbaar werden, ook al deden ze het nog wel. Dat maakte het onmogelijk voor de rest van het internet om onze servers te vinden."
Het issue duurde bovendien langer doordat fysieke toegang tot de apparatuur lastig was. "Onze gebouwen zijn lastig in te komen en als je binnen bent zijn de routers en andere apparaten zo ontworpen dat ze lastig aan te passen zijn, om misbruik te voorkomen. Dus het nam extra tijd in beslag om de protocollen in werking te stellen om mensen te kunnen laten werken aan de servers. Pas toen konden we zien wat het probleem was en de backbone weer online zetten."
Interne communicatie
In het algemeen was opvallend hoeveel informatie over Facebooks interne systemen mondjesmaat naar buiten kwam. Een van de meest spraakmakende kwam van een inmiddels verwijderd account op Reddit. Dat deed uitvoerig uit de doeken dat het waarschijnlijk ging om een issue met de DNS-servers, wat werd veroorzaakt doordat de peeringrouters voor BGP offline waren. Een anonieme bron van Tweakers bevestigt dit verhaal. De BGP-problemen kwamen ook naar voren uit een veelgedeelde blogpost van Cloudflare. Dat bedrijf merkte voor het eerst op dat de BGP-routers van Facebook niet meer te benaderen waren. Het probleem lijkt dus te maken te hebben met BGP, al blijft die informatie onbevestigd. Als dat zo is, dan is het niet het protocol zelf waar scheurtjes in zitten die tot dit soort situaties leiden, maar eerder Facebooks implementatie ervan.
/i/2004668682.png?f=imagenormal)
Verbindingen routeren
Om BGP goed te kunnen uitleggen, doken we even het serverhok in met onze bofh Kees Hoekzema. We willen van de analogieën over telefoonboeken en -centrales wegblijven, maar het border gateway protocol laat zich omschrijven als een manier waarop verkeer tussen twee routers of tussen een router en een provider wordt geleid. BGP vertelt een provider welk netwerk bij welk ip-adres hoort, en kan vervolgens worden geconfigureerd om de snelste weg tussen die verschillende netwerken te vinden. Neem een bestemming op internet zoals Tweakers. Tweakers hoeft zelf niets te regelen aan de implementatie van het border gateway protocol, dat doen onze hostingproviders True en Atom86. "Tweakers heeft een vrij eenvoudige setup, dus dat hebben we zelf niet nodig", zegt Kees. "Het heeft pas nut dat zelf te doen als je meerdere netwerken hebt die over meerdere locaties verdeeld zijn, of wanneer je meerdere verbindingen met internet hebt. Je moet er ook je eigen ip-space voor hebben, en met de huidige schaarste van ipv4-adressen is dat de laatste tijd niet makkelijk om te krijgen."
Voor Tweakers is het minder interessant BGP zelf te regelen dan het voor Facebook is
Laten we het visualiseren door ons voor te stellen dat je vanaf je Ziggo-connectie een verbinding wil leggen met Tweakers.net. True, onze hostingprovider, heeft veel verschillende routers en heeft daar het border gateway protocol op geïmplementeerd. "Dat laat aan de wereld zien hoe ze de specifieke ip-range voor Tweakers kunnen bereiken", zegt Kees. Dat wordt naar alle netwerken verzonden waar True mee verbonden is, en die sturen dat dan weer door naar netwerken waar zij mee verbonden zijn. Dat zijn bijvoorbeeld de AMS-IX, maar ook verschillende andere knooppunten en transitproviders. Ziggo krijgt die informatie ook binnen op haar routers en weet daardoor via welke netwerken en routes Tweakers te bereiken is. Met behulp van informatie die door BGP is verkregen, wordt een afweging gemaakt welke route wordt gekozen. Dat gebeurt in eerste instantie op beschikbaarheid van de route, maar het kan bijvoorbeeld op basis van snelheid en aantal tussenliggende routers. Ook kosten kunnen een rol spelen. "Verkeer via een bepaalde transitprovider kan bijvoorbeeld goedkoper of juist duurder zijn dan peering via de AMS-IX." Met behulp van BGP-informatie bestaan er veel verschillende manieren om verkeer te routeren.
Zelf hosten of uitbesteden
Je kunt het beheren van een BGP-implementatie op twee manieren regelen. De meeste gebruikers, zoals Tweakers, besteden dat gewoon uit aan hun hostingprovider. Andere bedrijven houden dat juist in eigen beheer, zegt Job Snijders. Hij werkt bij Fastly en is vrijwilliger bij internetorganisaties zoals OpenBSD, RIPE NCC en IETF en weet alles van BGP-implementaties. "Vaak zie je dat als er iets mis gaat met het BGP-protocol, het merkbaar is in de hele organisatie. BGP is echt een protocol voor de kern van het internet", zegt hij. Uitbesteden of niet heeft voor- en nadelen. Snijders: "Het is altijd een combinatie van de kosten, maar ook de performance en beheersbaarheid." Tweakers zou daarbij een goed voorbeeld zijn. Via de juiste BGP-implementatie vinden Nederlandse en Belgische bezoekers de site sneller dan bezoekers die toevallig op vakantie zijn in Kaapverdië. Is het in zo’n geval goed de controle te houden over wat er met bezoekers uit de buurt gebeurt, maar voor het handjevol internationale bezoekers dat je krijgt is het wat minder belangrijk die controle te hebben. Voor een bedrijf als Facebook is zo’n totale controle veel belangrijker.
BGP biedt veel mogelijkheden om het zelf in te richten en te optimaliseren. Snijders: "Door de open standaarden die partijen als de IETF beheren, kan iedereen die er technisch toe in staat is dit draaien zonder verplicht specifieke hard- of software te gebruiken." Met die vrijheid om je eigen netwerk op te zetten komt volgens Snijders ook wel een risico. "Je kunt je eigen verbinding er ook mee verbreken." Het kan dus zomaar gebeuren dat je in je BGP-regels neerzet dat je eigen servers niet bestaan. In zo'n geval werkt BGP precies zoals het hoort. Het is volgens Snijders dan ook een veelvoorkomend misverstand dat BGP 'oud en brak' is. Dat werd maandagavond veelvuldig herhaald door experts en Twitter-helden, maar beide kloppen niet echt. 'Oud' slaat op het feit dat BGP voor het eerst in het leven werd geroepen in de vroege jaren 80. "Maar sindsdien is er jaar in, jaar uit gewerkt, gepolijst en geüpdatet door honderden vrijwilligers", zegt Snijders. Daardoor draait 'het internet' niet simpelweg op BGP, maar op een evolutie van BGP.
Redundancy
Het border gateway protocol is volgens Snijders op een vlak erg goed: het heeft veel gelegenheid voor redundancy. "Dat is een fascinerende eigenschap. Dat heeft het internet zo groot gemaakt als dat het is. BGP heeft de eigenschap dat info die niet direct nodig is, ook niet meteen zichtbaar is. Dat betekent ook dat het bijvoorbeeld relatief weinig geheugen in BGP-routers kost." Door BGP volgt verkeer de beste route, maar alternatieve routes worden pas ingeladen op het moment dat de primaire wegvalt. Daardoor is het niet nodig een complete routekaart van internet vooraf in te laden.
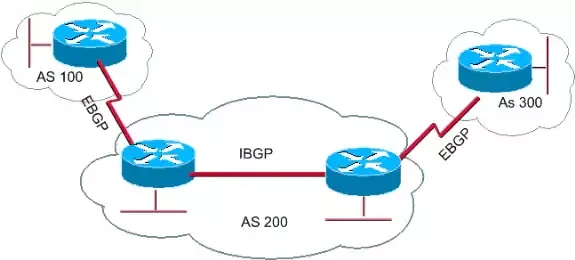
BGP-inrichting voor je datacenter
Ook met die achtergrondkennis is het echter nog moeilijk om te analyseren wat er precies mis ging bij Facebook. Met de beperkte informatie die Facebook zelf deelt over het incident is het vooral gissen, maar er zijn wel wat aanwijzingen over hoe het bedrijf zijn datacenters heeft ingeregeld. Begin dit jaar publiceerde het bedrijf een paper over precies dit onderwerp. Ingenieurs van Facebook beschrijven erin hoe ze het border gateway protocol zelf implementeren in hun datacenters - toch geen sinecure met de omvang die Facebook heeft. Het is een interessant inkijkje in de werkcultuur van Facebook. 'Move fast and break things' gold bijvoorbeeld ook voor de serverinfrastructuur. "Onze oorspronkelijke motivatie was om ons netwerk snel op te bouwen maar tegelijkertijd een schaalbaar routeringontwerp te houden", schrijven de admins. Daarbij was met name uptime belangrijk; Facebook heeft zich altijd op de borst geklopt vanwege zijn goede bereikbaarheid, ook hier. "We hebben geprobeerd een netwerk te bouwen dat hoge beschikbaarheid biedt voor onze diensten." Desondanks werd er geanticipeerd op downtime en failures. Uiteindelijk bleek BGP het beste protocol te zijn voor schaalbaarheid van een datacentrum. Het was volgens Facebook ook al bewezen dat het op dat niveau kon werken. Bovendien is BGP een gestandaardiseerd protocol dat ook goed werkt met de custom hardware die Facebook gebruikt.
Snelle veranderingen doorvoeren
Om dat opschalen te optimaliseren heeft Facebook een eigen BGP-agent geschreven voor onder andere het opzetten van externe BGP-sessies op switch-niveau. Daarmee kan het bedrijf naar eigen zeggen 'snelle, frequente veranderingen doorvoeren' aan de netwerkinfrastructuur. Voor het doorvoeren van wijzigingen in, of updates van, het protocol, heeft Facebook een eigen pipeline voor testen in werking gezet. Die begint met unit testing, maar Facebook heeft ook eigen emulator geschreven waarin ook wordt getest op situaties waarbij er iets mis gaat, zoals links die niet werken of als BGP moet herstarten. Facebook erkent dat daarin nog mogelijke obstakels zitten; het is bij emulaties moeilijk om zowel soft- als hardware na te bootsen, en testen in Linux-containers is 'veel langzamer dan op hardware switches', zegt het bedrijf. Tot slot wordt er nog canary testing uitgevoerd, waarbij een BGP-update op één switch wordt geplaatst en waarbij gekeken wordt of er problemen ontstaan wanneer er opgeschaald wordt. Die worden dan sneller ondervangen. Op die manier kan er worden uitgerold zonder liveproductie teveel te schaden. In het document wordt daarnaast beschreven welke back-upstrategie er binnen het datacentrum bestaat voor het geval een switch besluit er de brui aan te geven. Iedere switch krijgt daarvoor een alternatief routing-path.
/i/2004668690.webp?f=imagenormal)
Facebooks whitepaper zegt uiteindelijk niet zoveel over de situatie die maandagavond plaatsvond. Het toont bijvoorbeeld niet waar het precies mis ging, of hoe het uiteindelijk werd opgelost. Zo zou het kunnen dat de problemen aanvankelijk voornamelijk binnen de eigen backbone speelden en de resulterende BGP-problemen naar buiten toe daar een bijkomstigheid van waren. Daarvoor zal Facebook zelf meer bekend moeten maken.
Ondanks alle onduidelijkheid rondom het incident lijkt het er niet op dat het border gateway protocol nu stuk is. Dat betekent niet dat het perfect is. Veel BGP-data gaat nog steeds via plaintext en dat mag inmiddels wel anders. In 2015 schreef Tweakers ook al een artikel over de potentiële kwetsbaarheden van het protocol. Er wordt hard gewerkt aan het toevoegen van encryptie, zegt Snijders. "Van de grote protocollen zoals SMTP, DNS en http is BGP de laatste die nog moet worden bijgewerkt op grote schaal. Dat is aan de ene kant een uitdaging, maar ook een leuke puzzel."
Misschien zijn de internethaiku's ook wel aan een update toe.
Belangrijk systeem
Border gateway protocol
Backbone van het net
/i/2008072918.png?f=fpa)
:strip_exif()/i/2004648162.jpeg?f=fpa)
/i/2004672728.png?f=fpa)
/i/2004629056.png?f=fpa)
:strip_exif()/u/240676/pino_ada2c2.gif?f=community)
:strip_icc():strip_exif()/u/651669/crop61f075a821e45.jpg?f=community)
:strip_icc():strip_exif()/u/448966/crop62a741840cd69_cropped.jpg?f=community)
/u/649844/crop5f804331d9657_cropped.png?f=community)
:strip_exif()/u/44466/0115455001290429971.gif?f=community)
/u/122874/crop5e26d7a209cd1_cropped.png?f=community)
/u/172597/crop5e1225c8b1011.png?f=community)
/u/349199/crop69f59caff1e30_cropped.png?f=community)
:strip_icc():strip_exif()/u/78725/train-icon3.jpg?f=community)
:strip_icc():strip_exif()/u/86810/display.jpg?f=community)
:strip_exif()/u/26026/snowrabb.gif?f=community)
:strip_exif()/u/12572/4-3hoek-r-b-g-g.gif?f=community)
/u/200366/naamloos9999.JPG?f=community)
/u/269377/arnoud8bit.png?f=community)
/u/363743/crop61aa1329d36b8_cropped.png?f=community)
:strip_exif()/u/38813/holland.gif?f=community)
{kind=link}
{kind=link}