
Hoe doorbreek je een vicieuze cirkel? Google is al decennialang zo goed als monopolist in online zoeken. Omdat vrijwel iedereen zoekt via Google, kan het bedrijf zijn zoekmachine veel makkelijker dan concurrenten beter maken. Omdat Google de zoekmachine beter maakt, komen concurrenten er niet aan te pas.
Er was een moment dat het erop leek dat Googles monopolie zou worden doorbroken met de komst van AI-chatbots, maar als zoekmachines zijn diensten als Microsoft Bing en OpenAI ChatGPT niet genoeg in gebruik geraakt om die machtspositie te doorbreken.
De Europese Unie stelt een ongekende maatregel voor: Google zou zijn dataset, inclusief alle zoekopdrachten van gebruikers, beschikbaar moeten stellen aan concurrenten als Bing, DuckDuckGo, Ecosia en Qwant. Die kunnen dan leren van de zoekopdrachten van Google-gebruikers.
Volgende maand moet die maatregel definitief worden. Google is er uiteraard op tegen. Het bedrijf claimt dat zoekopdrachten niet te anonimiseren zijn en altijd te linken blijven aan een persoon.
:strip_exif()/i/2000961739.jpeg?f=imagenormal)
Waarom Google data moet afstaan
De plicht om informatie over zoekopdrachten af te staan komt uit de Digital Markets Act, de Europese wetgeving om de macht van grote techbedrijven in te perken. Googles zoekmachine geldt als poortwachter onder die wetgeving en moet dus concurrenten een eerlijke kans geven.
Die wetgeving is er al een aantal jaar en de verplichting om data af te staan bestaat ook al enkele jaren. Google heeft daarover al informatie online staan. Daaraan zijn strenge eisen verbonden. Een bedrijf moet een zoekmachine hebben en geen seo-diensten aanbieden, actief zijn in de EU en het moet een financieel levensvatbaar bedrijf zijn.
:strip_exif()/i/2008200510.jpeg?f=imagegallery)
De Europese Commissie had moeite met een aantal aspecten van de data. Zo beperkt Google de dataset tot zoekopdrachten die meer dan dertig keer voorkomen om ze te kunnen anonimiseren en de Commissie wil dat de vereisten voor toegang tot de data anders worden.
De maatregel dat het alleen mag gaan om zoekopdrachten die vaker voorkomen, moet ervoor zorgen dat zoekopdrachten niet te herleiden zijn naar individuele gebruikers. Dat is een mooi streven, maar daardoor hoeft Google een groot deel van de zoekopdrachten niet af te staan.
Ook willen concurrenten meer data over zoekgedrag en de Commissie vindt dat ook relevant. Daarbij gaat het onder meer om de tijd tussen het zoeken en klikken. Ook moet het uitbreiden van de data duidelijk maken of gebruikers hun zoekopdrachten verfijnen, wat veel zegt over wat ze vinden van de zoekresultaten.
Die data is volgens de Commissie nodig om een goede zoekmachine te bouwen en dat ligt voor de hand. De waarde van zoekmachines zit tenslotte niet in het beantwoorden van de algemene zoekopdrachten, maar juist in de specifieke zoekopdrachten die gebruikers hebben.
:strip_exif()/i/2007689686.jpeg?f=imagegallery)
Ook wil de Commissie dat Google de eisen versoepelt, want nu krijgen aanbieders van AI-chatbots geen toegang tot de data, terwijl zij daarmee de 'grounding' van hun AI-modellen zouden kunnen verbeteren en zo beter kunnen concurreren met zoekmachines zoals die van Google.
De bezwaren van Google
Google is het eens met de grondbeginselen van de uitwerking van de DMA, zoals het bevorderen van concurrentie, zo zei het bedrijf in een toelichting op de bezwaren waarbij Tweakers aanwezig was. Het delen van individuele zoekopdrachten kan volgens privacyonderzoeker Sergey Vasilevsky onmogelijk anoniem gebeuren. "Iedereen gebruikt Google anders. We hebben allemaal onze eigen trucjes om vragen te formuleren. Wat vragen we precies? Hoe krijgen we de informatie die we echt nodig hebben?"
Daarom staat er vaak identificeerbare informatie in de zoekopdracht zelf, zoals thuisadressen en bankrekeningnummers. "We hebben gekeken naar het openbaar maken van huisadressen, en dat gaat om miljoenen mensen. We hebben gekeken naar het openbaar maken van bankgegevens en bankrekeningnummers. En dat gaat om tienduizenden of honderdduizenden personen."
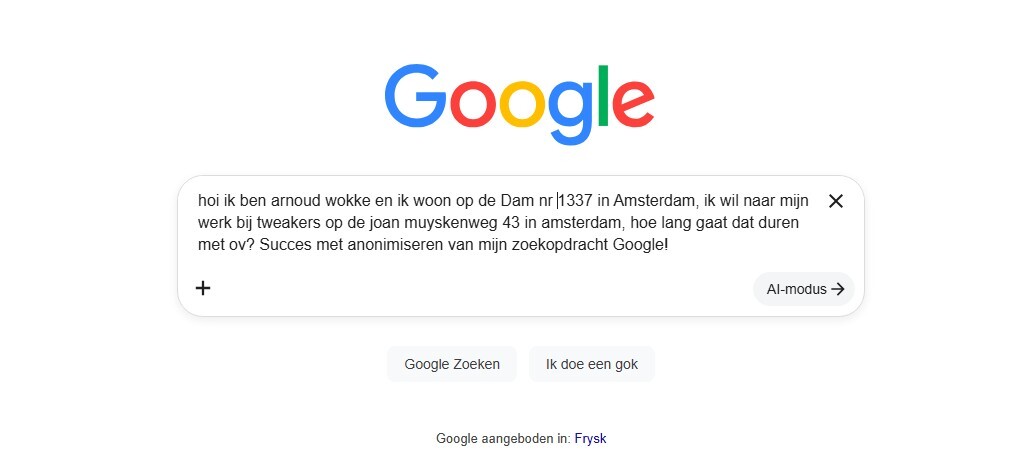
Zelfs als dat er niet in staat, is het makkelijk om mensen te herleiden op basis van de zoekopdracht en een grove locatie. "Stel, ik werk als kapper. Als het gebied relatief dunbevolkt is, zijn er niet zoveel kapperszaken met een formele salon. En dus kun je snel bepalen of het om een handjevol mensen gaat, want aan de hand van de zoekopdracht zelf kun je demografische informatie achterhalen, toch? Misschien zijn ze ouder, misschien jonger, misschien man, misschien vrouw, enzovoort."
Volgens hem is het anonimiseren letterlijk onmogelijk en moet er een compromis mogelijk zijn, maar dat kost tijd om te vinden. "De voorlopige maatregelen werden gepubliceerd, geloof ik, op 15 april. De periode voor open feedback was slechts twee weken. De beoordeling door externe academici liep dus tot 1 mei. En ik geloof dat het wettelijk gezien eind juli af moet zijn en de tekst wordt dus binnen een paar weken geschreven. Het moet allemaal heel snel."
Omdat het gaat om iets nieuws, vraagt het vinden van manieren om te anonimiseren juist meer tijd. "Er is niet veel literatuur over hoe je vrije zoekgegevens of vrije tekstgegevens kunt anonimiseren. Als je ergens tegenaan loopt, kun je een nieuwe methode voorstellen en zeggen: Dit is wat ik relevant vind. Laten we het testen. Laten we anderen het laten beoordelen. Je wilt echt deze stresstest uitvoeren, want het is de enige manier om er zeker van te zijn dat we niets over het hoofd hebben gezien. Het is erg moeilijk om te bewijzen dat iets goed geanonimiseerd is. Het is heel makkelijk om dingen te kraken. De enige manier om vertrouwen te krijgen in onze anonimisering is door ervoor te zorgen dat ze de tand des tijds hebben doorstaan, dat ze niet zijn gekraakt na een week, een maand, een jaar, twee jaar."
Hoe het verdergaat
De Europese Commissie wil geen jaren wachten. Google heeft de bezwaren neergelegd bij de Commissie en die zal zich er ongetwijfeld over gaan buigen. Lang hoeven we niet te wachten op die beoordeling, want de bedoeling is dus dat die volgende maand openbaar wordt.
Het uiteindelijke doel is dat concurrenten een eerlijke kans krijgen op de markt van zoeken. Dat Google, een bedrijf vol met knappe koppen die van alles hebben uitgevonden, claimt dat het de gevraagde zoekgegevens niet kan anonimiseren, zegt een paar dingen.
/i/2004424462.png?f=imagegallery)
Ten eerste ligt het keurig in lijn met dat Google niet wíl voldoen aan de DMA. Want op veel punten, waaronder het principiële punt, verzet het bedrijf zich tegen het breken van de eigen macht. Dat is logisch, maar het maakt elk verzet automatisch verdacht. Het standpunt van Google was vermoedelijk al van tevoren bepaald en Google heeft de argumenten erbij gezocht. Zelfs als die argumenten valide zijn en kloppen, heeft Google zichzelf, door zich te verzetten tegen de DMA op alle mogelijke fronten, op achterstand gezet in deze discussie.
Ten tweede laat het weer eens zien hoeveel data Google over zijn gebruikers heeft. Wij voeren zelf, zonder enige dwang, zoveel privacygevoelige data in bij Google dat het bedrijf zegt het onmogelijk te kunnen anonimiseren als dat van de wet moet. Dat op zich geeft ook te denken.
Redactie: Arnoud Wokke • Eindredactie: Monique van den Boomen
/i/2004847378.png?f=fpa)
:strip_exif()/i/2007814810.jpeg?f=fpa)
:strip_exif()/i/2007853496.jpeg?f=fpa)
:strip_icc():strip_exif()/u/21673/crop65674aee06c6d_cropped.jpg?f=community)
:strip_exif()/u/19665/ElfEverQuestTweakersSmall.gif?f=community)
:strip_icc():strip_exif()/u/389144/crop5f4a7b0c8e51d_cropped.jpeg?f=community)
/u/176086/crop5f0823fa5e8d6_cropped.png?f=community)
/u/415386/bonemonkey.png?f=community)
:strip_icc():strip_exif()/u/145751/check-in-minion-small2.jpg?f=community)
:strip_icc():strip_exif()/u/637028/crop6a3e22601b0f7_cropped.jpg?f=community)
/u/62384/crop61891f444d6e9.png?f=community)
:strip_icc():strip_exif()/u/269054/crop6064049cee9ab_cropped.jpg?f=community)
/u/1906/crop5dfd46928e003.png?f=community)