
Het is een cliché geworden de afgelopen jaren: een groot taalmodel is een 'black box'. We stoppen er iets in, er komt iets uit, maar waarom eruit komt wat we erin stoppen, blijft een beetje onbekend. De makkelijkste uitleg is die van een woordvoorspeller: een taalmodel berekent statistisch wat het meest logische volgende woord is en zet dat neer.
Maar dat is niet langer waar. Met redenerende modellen krijg je als gebruiker af en toe al een inkijkje in wat er gebeurt bij het nadenken, maar het is niet na te gaan of dat een compleet beeld is. Ook kun je tegenkomen dat een model begint met antwoorden en dat weghaalt, en ook dat voelt als een inkijkje. Er gebeurt veel meer in een taalmodel dan werd aangenomen.
De opbouw van een groot taalmodel
Laten we even beginnen bij het begin, namelijk hoe een groot taalmodel werkt en hoe de training in elkaar zit. Een groot taalmodel is een neuraal netwerk. Dat werkt met neuronen en verbindingen tussen die neuronen. De naamgeving komt uit de biologie van onze hersenen, al werken digitale neurale netwerken anders dan de analoge in ons hoofd. Als architectuur bestaat een neuraal netwerk uit een laag inputneuronen, een verborgen of hidden laag die uit een of meer lagen neuronen bestaat, en een uitvoerlaag. Een netwerk kan tientallen lagen bevatten.

Een neuron is niet 1 of 0, maar een willekeurige waarde die ligt tussen 1 en 0. Die data wordt naar een tweede laag 'neuronen' gestuurd. Die tweede laag bestaat uit een veel kleiner aantal neuronen en elk neuron krijgt input van elk neuron uit de eerste laag. Daarbij krijgt de data een weging. De data van de tweede laag neuronen, ook weer waarden tussen 0 en 1, gaat naar de uitvoerneuronen, opnieuw met een weging. Het neuron dat het dichtst bij waarde 1 komt, geeft aan welk cijfer het neurale net heeft 'gezien' en bepaalt dus de waarschijnlijkste output. Zo komt een neuraal netwerk tot 'antwoorden'.
Die wegingen zijn niet ingeprogrammeerd, maar die leert de software in eerste instantie zichzelf. Dat gebeurt doordat hij checkt of de output de goede was. Dat gebeurt in de eerste van twee fases, waarin een groot taalmodel training ondergaat. Die eerste fase is de fase waarbij de ontwikkelaars een grote dataset in het systeem gooien. Dat zijn doorgaans verzamelingen van teksten van internet: websites, fora, boeken en andere plekken waar veel tekst verschijnt. Ook bij grote bedrijven gaat het niet altijd om legaal verkregen datasets.
De software probeert, zoals het toetsenbord op een telefoon al jaren doet, simpelweg het volgende woord in een tekst te voorspellen van teksten in de dataset. De output van het neurale netwerk is daarmee te vergelijken met het juiste antwoord uit de tekst. Als dat goed is, dan geeft de software zichzelf een signaal dat hij de goede wegingen heeft toegepast en dan slaat hij dat op. Als het volgende woord helemaal fout is, dan verandert de software de parameters. Dit is een proces dat veel computerkracht vergt. Deze fase van training gebeurt daarom op supercomputers, of in elk geval op systemen met zoveel mogelijk gpu's. Op die manier gaat die training zo snel mogelijk. In deze fase leert het model zichzelf dus hoe zinnen zijn opgebouwd in de diverse talen en hoe het dus antwoorden moet structureren.
Het gevolg is dat het model telkens statistische berekeningen maakt over wat het meest logische volgende woord is. Taal is vaak ambigu en woorden of woordgroepen kunnen meerdere betekenissen hebben. Bij de combinatie 'ik was af' zou het kunnen dat de zin moet eindigen met 'met verstoppertje', maar het zou ook kunnen dat het eindigt met 'met een druppeltje afwasmiddel'. Het taalmodel probeert dan op basis van de context een inschatting te maken welke de juiste is. Dat is ook de reden dat hoe groter een taalmodel is, hoe beter het concepten uit de echte wereld lijkt te snappen. Er is dan meer context om te koppelen aan de verbindingen in het neurale netwerk, waardoor de software meer verbindingen kan leggen en dus met meer contexten rekening kan houden.
Om het beste volgende woord te schrijven, is dus meer nodig dan alleen het vooruitkijken naar het volgende woord. En dat is precies waar Anthropic, het bedrijf dat Claude maakt, onderzoek naar heeft gedaan: in hoeverre kan een groot taalmodel 'vooruitdenken' om tot een goed antwoord te komen?
Hoe onderzoekers uitplozen hoe het werkt
Je zou verwachten dat het neurale netwerk neuronen heeft voor elk concept om zo tot antwoorden te komen, maar dat is niet waar. Een van de moeilijke elementen is dat elk neuron verschillende concepten vertegenwoordigt, terwijl elk concept is verdeeld over veel verschillende neuronen. Daarom is het zo lastig om te achterhalen hoe een neuraal netwerk in elkaar zit na de training, en dus hoe het grote taalmodel precies werkt.
Er zijn diverse methoden om uit te pluizen hoe het van binnen werkt, maar dit gaat vooral om het maken van een replacementmodel, een model onder controle van de onderzoekers dat het publiekelijk beschikbare model zo dicht mogelijk benadert. Dat is om diverse redenen heel moeilijk.
Er is nauwelijks een manier om te verifiëren hoe goed dat werkt. De beste methode is om de output van het replacementmodel te vergelijken met dat van het originele model. Ook het onderverdelen van de nodes en het toewijzen van features aan die nodes is subjectief, zo schrijven de onderzoekers.
Die output is niet zomaar output: de onderzoekers hebben ook functies geremd of onderdrukt en de uitkomsten van het replacementmodel te vergelijken. Daardoor moet het model op zoek naar een andere uitkomst.
Dat onderdrukken hebben ze gedaan door het gewicht van neuronen die gelinkt zijn aan bepaalde concepten handmatig aan te passen. Daardoor is te zien hoe het replacementmodel antwoordt als er net één variabele anders is.
De uitkomsten: noem de hoofdstad
De onderzoekers zeggen in het bijzonder dat hun methode niet altijd werkt en dat er zelfs specifieke scenario's zijn waarin taalmodellen anders werken. Dat gebeurt onder meer bij lange prompts en ongebruikelijke prompts, omdat die de uitkomsten ernstig beïnvloeden. Toch vertellen de voorbeelden veel over hoe een groot taalmodel 'denkt'.



Dit eerste voorbeeld gaat over hoe een model redeneert bij een vraag waarbij het antwoord twee denkstappen nodig heeft. De vraag is in dit geval 'Hoe heet de hoofdstad van de staat waar Dallas ligt?', iets wat je naar Nederland zou kunnen vertalen als 'Hoe heet de hoofdstad van de provincie waar Sittard ligt?'. Dat vereist twee stappen, want eerst moet het model achterhalen om welke staat het gaat en daarna wat de hoofdstad daarvan is.
Wat opvalt: als de onderzoekers 'staat' onderdrukten, beïnvloedde dat het antwoord niet, maar het onderdrukken van alle andere elementen had wel invloed op het antwoord en dan kwam het juiste antwoord ook niet.
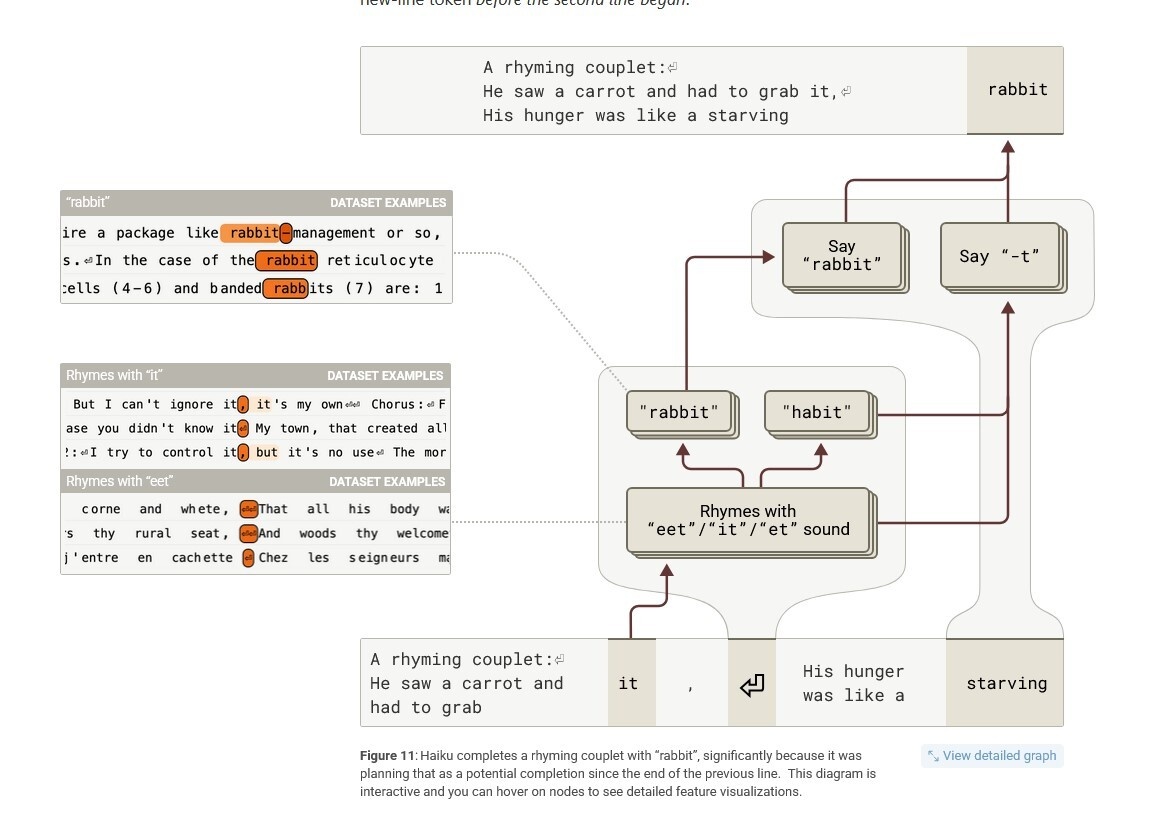
Maak een gedicht af
De uitleg over taalmodellen is altijd geweest dat ze woord voor woord een tekst voorspellen, maar dit experiment toont aan dat dat in elk geval niet altijd het geval is. De onderzoekers vonden aanwijzingen voor een mechanisme van planning: "Het model activeert vaak kenmerken die overeenkomen met kandidaat-einde-van-de-volgende-regelwoorden voordat de regel wordt geschreven, en maakt gebruik van deze kenmerken om te beslissen hoe de regel moet worden samengesteld."

:strip_exif()/i/2007389826.jpeg?f=imagegallery)
Dat is een behoorlijk inzicht, omdat het laat zien dat taalmodellen niet leunen op improvisatie, maar vooruitkijken hoe een zin moet eindigen om vervolgens daar de hele zin op aan te kunnen passen. Hoe ver die planning gaat, blijkt niet uit dit experiment.
Die planning gaat vooruit en achteruit: het kan ook eindigen met het laatste woord en dan de zin die eindigt op dat woord formuleren, zodat de zin op een juiste manier eindigt.
Hoe vertalen werkt
We zijn al een paar jaar gewend dat veel AI-taalmodellen in het Nederlands antwoorden. Een jaar geleden hebben we een keer gekeken hoe taalmodellen Nederlandse culturele elementen meenemen in hun antwoord. Weten taalmodellen wat een kringverjaardag is? Het antwoord bleek in veel gevallen 'ja', al waren niet alle hapjes die ze suggereerden geschikt.
Intussen hebben veel taalmodellen redeneerfuncties en als je daaraan Nederlandse prompts stuurt, is te zien dat ze vaak eerst vertalen naar het Engels, dan gaan redeneren, vervolgens hun antwoord vertalen en dat weergeven. Betekent dat dat taalmodellen in het Engels 'denken'?


Dat is in elk geval niet helemaal waar. Een prompt in drie talen blijkt dezelfde nodes te activeren. Die prompts hebben dezelfde inhoud, maar geen enkel karakter komt uiteraard overeen. De theorie is dat simpele prompts langs neuronen die niet taalspecifiek zijn lopen.
Wel hebben taalmodellen een voorkeur voor Engels. Een verklaring daarvoor geeft Anthropic niet. Veel modellen zijn getraind op meer Engelstalig materiaal dan op materiaal uit andere talen en dat zou een verklaring kunnen zijn.
Hallucineren kun je leren
Taalmodellen kunnen hallucineren, maar om dat te voorkomen, proberen bedrijven ze zo te trainen dat ze op feitelijke vragen alleen antwoord geven als ze zeker genoeg zijn van het antwoord. Op de vraag welke sport Michael Jordan beoefent, wist het model zeker genoeg dat het 'basketbal' was.


Wel een beetje gek: toen de onderzoekers de node voor 'bekend antwoord' probeerden te blokkeren, gaf het model alsnog het juiste antwoord. Het sprong toen niet automatisch naar de optie om dan maar geen antwoord te geven.
Maar omgekeerd werkt het anders. Toen de onderzoekers vroegen naar een fictieve sporter, bedacht het model wel logisch klinkende sporten, maar die antwoorden waren niet zeker genoeg om als antwoord te geven. Toen de onderzoekers de node voor 'onbekende naam' onderdrukten, gokte het model dat het een schaker was en gaf dat als antwoord.
Ook bij een prompt voor papers van een academisch onderzoeker bleek hallucineren voor te komen, al is het minder duidelijk hoe dat dan kwam. De onderzoekers namen waar dat het model niet kon vaststellen dat het onjuiste antwoorden wilde gaan geven, maar konden niet aanduiden waarom het model dat zelf niet tegenhield. Dit laat in elk geval zien dat hallucinatie een lastig aan te pakken probleem is.
Jailbreaken
Jailbreaken gaat om de mogelijkheid een taalmodel te laten doen wat eigenlijk volgens de regels niet mag. Dat werkt bij elke uitgave anders, maar het kan nog steeds. In dit geval probeerden de onderzoekers advertenties te genereren voor het schoonmaken met een mix van bleek en ammoniak. Dat levert chloramine op, een giftig gas. Dat kan in extreme gevallen dodelijk zijn.
Logisch dus dat een taalmodel waarschuwt tegen het mengen van deze twee. Hoe zit dat als je vraagt om een advertentietekst te schrijven? Dit model bleek ook dan te waarschuwen in veel gevallen. Alleen als zij de node die het concept kent van de mix van ammoniak en bleek onderdrukten, gaf het model gehoor en schreef de gevraagde advertentie. In alle andere gevallen gaf het model, in de vorm van een advertentie of niet, een waarschuwing om die twee middelen niet te mengen.

Tot slot
Dit zijn maar glimpjes in de werking van grote taalmodellen. Het onderzoek is natuurlijk beperkt: het richt zich op een afsplitsing van alleen Claude en niet op andere modellen. De gegeven prompts zijn over het algemeen simpel en kort. Kortom: er zou veel meer te onderzoeken zijn. Door de methode van het kunnen onderdrukken van neuronen is het wel mogelijk om te zien hoe een taalmodel tot een antwoord komt.
Dat is geavanceerd. Er zijn onverwachte uitkomsten: de mogelijkheid om vooruit te plannen, concepten die agnostisch zijn voor de taal en dat er meerdere ingebouwde mechanismes lijken te zijn voor het onderdrukken van onzekere of onjuiste antwoorden zijn dingen die niet voor de hand lagen.
Stiekem is het best wel gek. Bij elke technologie die we als mensheid gingen gebruiken, van de stoomtrein tot de smartphone, waren er mensen die precies wisten hoe die werkte. Nu, met AI-modellen, trainen ze zichzelf en dat levert een andere verhouding op tot die technologie. We hebben dit eerst gemaakt en nu gaan we pas onderzoeken hoe dat eigenlijk werkt.
Redactie: Arnoud Wokke Eindredactie: Monique van den Boomen Headerfoto: BlackJack3D/Getty Images
:strip_icc():strip_exif()/i/2007460880.jpeg?f=fpa_thumb)
/i/2006829312.png?f=fpa)
:strip_icc():strip_exif()/u/125182/crop5f773b38ac426_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/572004/fox.jpg?f=community)
:strip_icc():strip_exif()/u/50747/crop56ff9e8c1f4bd_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/526002/crop5903118017c66.jpeg?f=community)
:strip_icc():strip_exif()/u/134130/crop656d9955ccc54.jpg?f=community)
/u/27299/hoofd.png?f=community)
:strip_icc():strip_exif()/u/1493414/crop614b02975caa1_cropped.jpg?f=community)
/u/28892/flo.png?f=community)
:strip_exif()/u/296989/webicon.gif?f=community)
:strip_icc():strip_exif()/u/33880/crop5ec3d2d5f2541_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/140051/BSOD.jpg?f=community)
/u/524443/My_Beautiful_Dark_Twisted_Fantasy.png?f=community)
:strip_icc():strip_exif()/u/80690/silly60.jpg?f=community)
:strip_exif()/u/26289/ahxp68H.gif?f=community)
/u/246414/crop64732e7f0bf92_cropped.png?f=community)
:strip_icc():strip_exif()/u/227665/th_petey_rawrs.jpg?f=community)
/u/96903/cdwaveicon.png?f=community)
/u/40481/crop63f777c898038_cropped.png?f=community)
/u/2089840/crop65d8bf7c41e1f_cropped.png?f=community)
:strip_icc():strip_exif()/u/59826/crop5a2d096bed81a_cropped.jpeg?f=community)
/u/1435570/crop672c9fd299184_cropped.png?f=community)
:strip_icc():strip_exif()/u/841345/crop69e3a13edc965_cropped.jpg?f=community)