
Het staat buiten kijf dat als je het maximale wilt halen uit AI-chatbots, het goed leren schrijven van prompts een nuttige vaardigheid is. Het is niet moeilijk te vinden hoe dat moet en het kan je helpen om meer uit AI-chatbots te halen. Wat nog leuker is, is dat je leert omgaan met de mogelijkheden en beperkingen van de huidige generatie AI-chatbots. Dat prompt engineering je nu nog een voorsprong geeft, betekent dat AI-chatbots nog niet goed genoeg zijn om écht natuurlijke taal in de juiste commando's om te zetten. Die tijd kan wel komen en de kans bestaat dat prompt engineering steeds makkelijker wordt.
Wie denkt dat prompt engineering nu hetzelfde is als met computers leren omgaan in de jaren tachtig en negentig van de vorige eeuw of een smartphone leren gebruiken in de jaren nul en begin jaren tien, zit er vermoedelijk naast. Ja, AI heeft de potentie om veel dingen in de maatschappij te veranderen, maar prompt engineering hangt aan de huidige generatie AI-chatbots en die zullen over een paar jaar al geen rol van betekenis meer spelen.
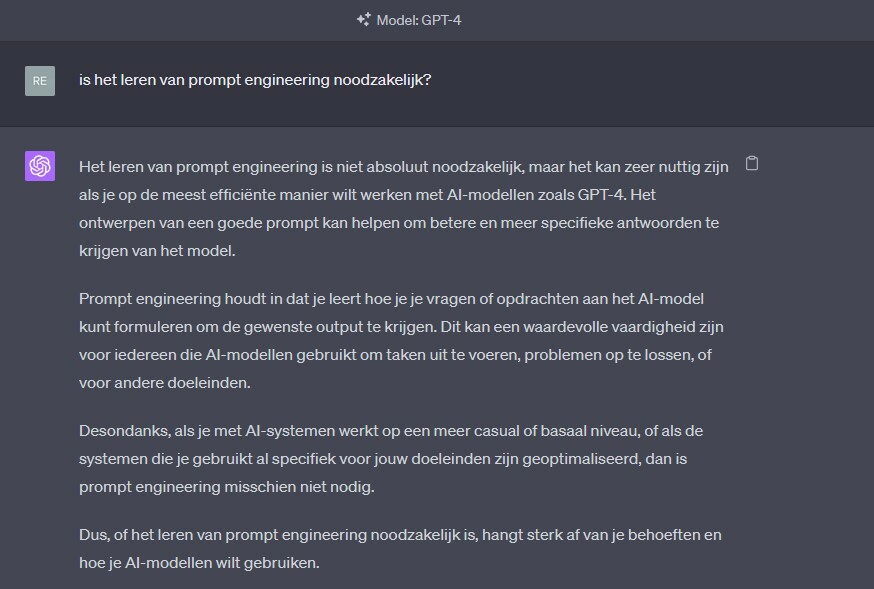
AI is nu duidelijk een hype en dat gaat vaak gepaard met overmatige aandacht voor bepaalde elementen daarvan. Kun jij binnen afzienbare tijd een miljoenensalaris verdienen, omdat je nu een paar avonden een cursusje hebt gedaan op LearnPrompting? Natuurlijk niet, maar AI is interessant genoeg om mee om te leren gaan. Net zoals bij AI zelf is het zaak om niet té hoge verwachtingen te hebben. Want, zoals al zo vaak is gebleken, stelt het resultaat dan uiteindelijk alleen maar teleur. Of, zoals ChatGPT met GPT-4 het verwoordt: "Het leren van prompt engineering is niet absoluut noodzakelijk, maar het kan zeer nuttig zijn als je op de efficiëntste manier wilt werken met AI-modellen."
:strip_exif()/i/2006018352.jpeg?f=fpa)
/i/2005662524.png?f=fpa)
:strip_exif()/i/2005545080.jpeg?f=fpa)
:strip_exif()/i/2004743102.jpeg?f=fpa)