
Hoe zal een historicus over vijftig of honderd jaar terugkijken op deze tijd? Door welke bronnen laat hij of zij zich informeren om een beeld te schetsen van ons leven? Uiteraard gebruikt hij of zij daar boeken, kranten, videodragers en foto’s voor. Maar om een beeld te schetsen van hoe ons leven eruit ziet, moet je ook online kijken, want daar speelt een groot deel van ons leven zich af. Een historicus moet dus kijken naar websites, weblogs en sociale media. Dat is echter nog niet zo makkelijk, want de gemiddelde webpagina is maar negentig dagen online voor hij verdwijnt of wordt aangepast.
Om historici van de toekomst een kans te geven, werkt de nationale bibliotheek KB al vijftien jaar aan een archief van ons online leven. Dat varieert van Nederlandse websites uit de tijd van Euronet en XS4ALL tot een collectie met sites die iets vertellen over hoe wij de coronapandemie hebben beleefd. Conservator digitale collecties Kees Teszelszky en collectiespecialist Peter de Bode van de KB vertellen hoe en waarom ze dat doen. “Het liefst zouden we alle websites bewaren.”
Hoe bewaar je een website?
In vijftien jaar tijd heeft de KB iets meer dan 21.500 websites gearchiveerd, die allemaal zijn te bekijken in de leeszaal van de nationale bibliotheek in Den Haag. Dat klinkt als weinig, helemaal als je bedenkt dat er ongeveer 6 miljoen .nl-sites zijn. Met Nederlandse websites op andere domeinnamen erbij, komt de teller zelfs boven de 10 miljoen uit. "We slaan niet alle websites op", legt Teszelszky uit. "Dat heeft een technische, maar ook een juridische en inhoudelijke reden."
Het archiveren van het Nederlandse web begint bij de selectie. "Alles komt in principe in aanmerking voor selectie", legt De Bode uit, "maar je kiest een representatie van een geheel." Volgens hem moet je je daarbij verplaatsen in de gebruiker van de toekomst die onze digitale cultuur wil begrijpen. "Je wil dus niet alleen maar opmerkelijke websites bewaren", legt Teszelszky uit, "maar juist ook gewone sites. Anders weten toekomstige historici niet wat 'gewoon' was." Je moet daarbij uit tientallen soortgelijke sites een representatieve keuze maken. "Zo zijn er honderden loodgieterssites. Welke bewaar je wel en welke niet?", vertelt De Bode. Daarnaast is het belangrijk dat je goed luistert naar geluiden uit de maatschappij, vult Teszelszky aan. Ook proberen Teszelszky en De Bode af en toe een tijdcapsule te maken, een speciale collectie rond een bepaald onderwerp waarbij ze zoveel mogelijk websites proberen te verzamelen rond dat thema. "Je weet natuurlijk niet wat over honderd jaar belangrijk is", zegt Teszelszky.
Geen depotwetgeving
Wanneer de KB een selectie heeft gemaakt, moet de website-eigenaar op de hoogte worden gesteld van het opnemen van de website in het archief van de KB. "Nederland is het enige land ter wereld dat geen enkele vorm van depotwetgeving heeft. Dat soort wetgeving geeft bibliotheken toestemming om een boek of website te bewaren", legt Teszelszky uit. "Zonder die wetgeving moeten we een uitgever op de hoogte stellen voor we een tekst in onze collectie kunnen opnemen. Dat is bij boeken niet zo'n probleem, want daarover maken we gewoon afspraken met uitgevers. Voor websites is het ingewikkelder." De Bode voegt toe: "We moesten dus alle ruim 21.500 website-eigenaren benaderen om te laten weten dat we hun site gaan toevoegen aan de collectie."
Zodra de KB een website wil opnemen in de collectie, krijgt de maker een bericht en vier weken de kans om bezwaar te maken. "We werken via opt-out. Als de website-eigenaar nee zegt, is het jammer, maar dan kunnen we de website niet bewaren", legt De Bode uit. "En als we de website-eigenaar niet kunnen achterhalen, kan het ook niet." In andere landen kan een paar keer per jaar het hele nationale web worden opgeslagen met crawlers. In Nederland kan dat juridisch niet. Dat is de belangrijkste reden dat de collectie van de KB relatief zo klein is. "En dat is jammer, want er gaat Nederlands erfgoed verloren. We worden elke dag intellectueel armer", stelt Teszelszky. "Nederland heeft bijna niks van zijn digitale geschiedenis bewaard."
Die wetgeving is ook een belangrijke reden dat de collectie alleen te bekijken is in de leeszaal van de KB en niet online, legt Teszelszky uit. Dat zou herpublicatie zijn, en dat mag niet zomaar. Een deel van de website-eigenaren stemde alleen in met het opnemen in het archief, als de site alleen in de leeszaal te zien zou zijn. Daar kan overigens iedereen de collectie inzien die lid is van de KB.

Het archiveren zelf gebeurt met webcrawlers. "We gebruiken daarvoor Heritrix", legt De Bode uit. Dat is een webcrawler ontwikkeld door het Internet Archive, dat volgens Teszelszky gebruikt wordt door ongeveer negentig procent van alle bibliotheken. Daarnaast gebruikt de KB de zelfontwikkelde Web Curator Tool, die het samen met de nationale bibliotheek van Nieuw-Zeeland heeft doorontwikkeld. "Daarmee kunnen ze zeggen hoe Heritrix zich moet gedragen. Zo kunnen we zeggen dat Heritrix na 1,5GB per webpagina moet stoppen, of hoeveel niveaus diep van een website moeten worden opgeslagen." Ook registreert de WCT precies welke stappen de crawler heeft gemaakt. "De omschrijving van waarom en hoe je een website hebt opgeslagen, is ook van belang", voegt Teszelszky toe.
Webzombies en het Internet Archive
Hoewel de nationale bibliotheek in de basis dezelfde software gebruikt om websites te archiveren als het Internet Archive, doet de KB het toch net anders. Waar de KB een selectie maakt van websites, probeert het Internet Archive álles op te slaan. The Wayback Machine is een plek om oude versies van websites terug te vinden. De crawlers van het Internet Archive kruipen het hele internet over om kopieën te maken van webpagina's. Als zij dit al doen, waarom is de verzameling van de KB dan eigenlijk nog nodig? Beide hebben hun waarde, stellen De Bode en Teszelszky, en ze vullen elkaar aan. "De crawler van de KB begint bij de homepage en gaat dieper dan die van het Internet Archive, doordat we het gedrag van de crawler nauwkeurig kunnen instellen", legt Teszelszky uit. "Het Internet Archive probeert vooral zoveel mogelijk op te slaan."
"Je moet het Internet Archive zien als een enorme bak met Lego. Die blokjes zijn niet gesorteerd en ze zijn op verschillende momenten binnengehaald om een geheel te vormen. Dat werkt, maar je loopt wel het risico op het maken van web-zombies. Dode websites worden tot leven gewekt doordat het live-web lekt naar het gearchiveerde web", zegt Teszelszky. Omdat het Internet Archive verschillende momenten pakt en ze samenvoegt, krijg je soms websites zoals ze nooit online hebben gestaan. Ook kunnen stukjes nieuwe sites lekken naar een gearchiveerde site, omdat ze op een server staan waar de oude site heeft gestaan. Daardoor krijg je een mengelmoes van nieuw en oud. "Archiveren van websites is daarom handwerk", voegt De Bode toe.
:strip_exif()/i/2005045680.jpeg?f=imagegallery)
Is het Internet Archive dan waardeloos voor historici? Nee, absoluut niet, zegt Teszelszky. Sterker, het Internet Archive is heel belangrijk. "Een website verandert constant. Domeinen verdwijnen of websitebouwers halen dingen weg." Daar komt bij dat het Internet Archive niet hoeft te wachten op toestemming om een site te archiveren, zoals de KB. Het kan dus goed zijn dat er in ieder geval iets bewaard is gebleven, vinden Teszelszky en De Bode. Je krijgt momentopnamen die je kunt aanvullen met de selectieve aanpak van de bieb en kunt voorzien van context.
Internetpioniers op XS4ALL
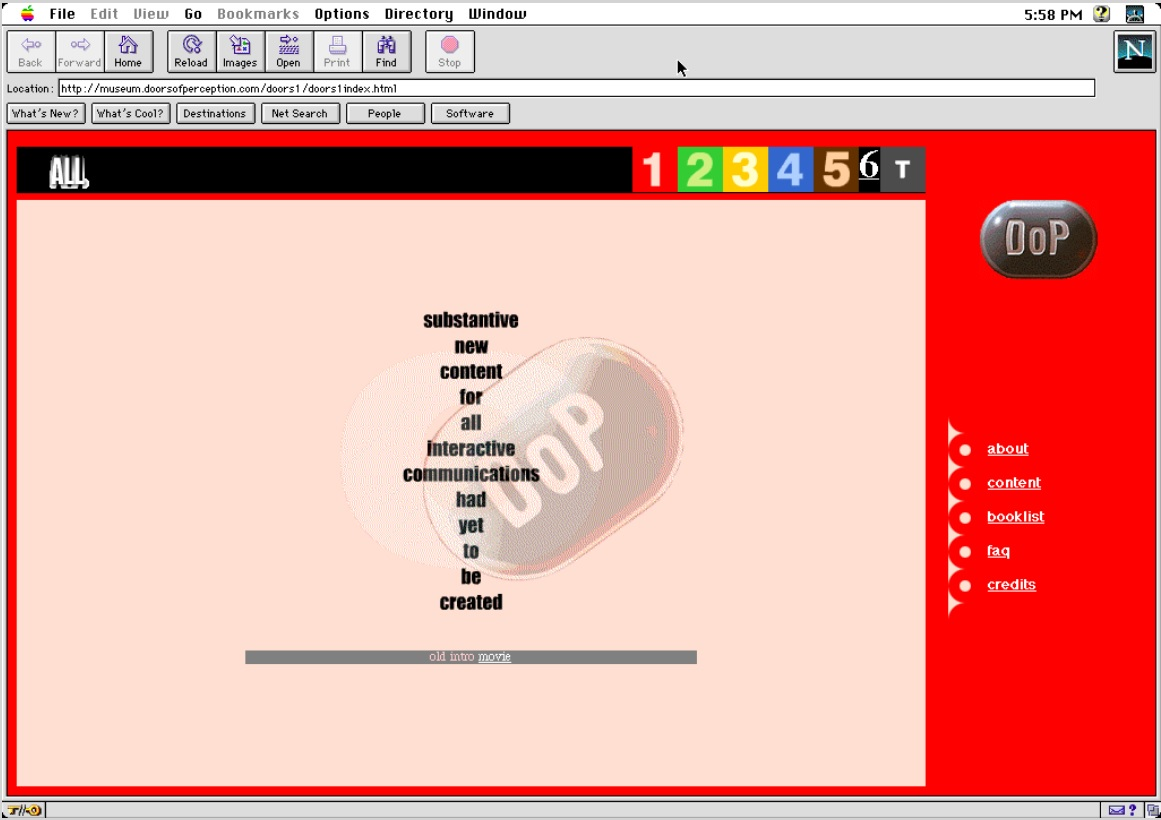
De eerste website die de KB archiveerde, was de website van het Thomas Instituut van de Universiteit van Tilburg, in 2007. Inmiddels is de hele collectie zo'n 70TB groot, een hoeveelheid data die de KB met de nodige back-ups heeft opgeslagen in een extern datacenter. "De collectie groeit exponentieel", legt De Bode uit. Aanroepen gebeurt via de Open Wayback Machine van het Internet Archive, die de KB gebruikt om de eigen collectie aan te roepen. Een aanzienlijk deel van die collectie is een verzameling van websites van XS4ALL uit de periode 1993 tot 2001, waarvan een groot deel 25 jaar na dato nog steeds online staat. "Dat is heel bijzonder, want een gemiddelde webpagina staat negentig dagen online", vertelt Teszelszky.
De KB begon in 2019 met het verzamelen van die websites, uit angst dat ze offline zouden gaan vanwege de overname van XS4ALL door KPN. De KB archiveerde ruim drieduizend pagina's van wat Teszelszky 'echte internetpioniers' noemt. Een voorbeeld daarvan is Liesbet Zikkenheimer. Zij maakte in 1995 de persoonlijke website Liesbet's Atelier. Die site is nog steeds online, maar niet alles werkt meer naar behoren. "Wij proberen om die website zo authentiek mogelijk op te slaan", legt De Bode uit. Daarom heeft De Bode, samen met Johan van der Knijff en anderen geprobeerd zoveel mogelijk van de site te repareren in de gearchiveerde versie.
/i/2005046272.png?f=imagenormal)
Coronacollectie
Begin april rondde de nationale bibliotheek haar meest recente collectie af: een verzameling websites over de coronapandemie. Dit is een speciale collectie met websites die tijdens de coronapandemie online stonden. Er zitten natuurlijk overheidswebsites in, zoals van de RIVM, de Tweede Kamer, de Belastingdienst, het UWV, het CBS en de RVO, maar ook veel andere sites die iets over de tijdgeest zeggen. "Denk aan websites over Koningsdag en de 5-meiviering die ineens niet doorgingen", zegt De Bode. "Maar ook aan sites als Thuisarts.nl, de sites van het Longfonds en de KNVB, en kritische sites als die van Viruswaarheid en GeenStijl."
Omdat we zoveel online waren tijdens de pandemie, zijn websites uit die periode belangrijk om een beeld te vormen van hoe we die tijd hebben ervaren, stelt Teszelszky. De KB begon in maart 2020 met verzamelen en sloot 1 april 2022 de collectie. "Dat betekent niet dat we stoppen met verzamelen, maar de aanwas zal beduidend afnemen", zegt De Bode. De sites die gearchiveerd zijn, zijn voorzien van context in de vorm van een collectiebeschrijving met daarin precies wanneer en waarom een bepaalde site aan de collectie is toegevoegd.
Veel van de sites uit de beginperiode zijn nu weer offline, of de tekst die bijvoorbeeld verwijst naar de lockdowns en de gevolgen van verschillende maatregelen voor delen van onze samenleving, is alweer verdwenen. "Denk aan onderwijssites en hoe die sector met de pandemie omging, maar ook aan sites van verzekeraars, kerken en initiatieven als help a local." Een voorbeeld van een site die tijdens de collectie veranderde, vertelt De Bode, is die van Viruswaarheid. "Precies in de vier weken waarin we website-eigenaren op de hoogte stellen van het feit dat we hun website aan de collectie willen toevoegen - en waarin die eigenaren kunnen weigeren - veranderde Viruswaanzin zijn naam in Viruswaarheid. De website van Viruswaanzin hebben wij daardoor niet. Dat is zonde."
Sociale media en betaalmuren
Tot grote spijt van Teszelszky en De Bode kan de KB niet alles archiveren. Het archiveren van socialemedia-sites is bijvoorbeeld onmogelijk, en dat geldt ook voor sites als Funda en webshops. Bovendien zorgen JavaScript en Flash voor problemen. "JavaScript kost ons soms de nek", zegt De Bode. "Flash-websites waren een gruwel, want je kunt niet doorklikken. We kunnen de swf-bestanden zien, maar ze niet afspelen. En Funda is een database met een schil eromheen. Die schil kunnen we bewaren, de database niet. Met Marktplaats net zo. Webshops zijn berucht. De webarchiveersoftware probeert alles dat een webshop verkoopt in het winkelwagentje te stoppen en genereert daardoor een oneindig aantal links." Teszelszky vult aan: "Daar komt bij dat een site als Bol.com een persoonlijk aanbod laat zien. Elke keer als we de website zouden benaderen, zouden we dus iets anders zien."
Het is technisch onmogelijk om Facebook vast te leggen, en met Twitter is het niet te doen om toestemming te regelen, vertelt Teszelszky. Daarbij is het veel te groot om op te slaan. "De Amerikaanse Library of Congress heeft geprobeerd alles van Twitter te bewaren, maar kreeg daar spijt van en is er in 2017 stilletjes mee gestopt. Nu bewaart het nog maar een selectie", vertelt Teszelszky.
/i/2001245141.png?f=imagegallery)
Daar is een recente belemmering bij gekomen: betaalmuren. "Ja, die zijn heel vervelend", zegt De Bode. "In feite komen we niet voorbij het inlogscherm. We hebben van twee uitgevers inloggegevens gekregen. Maar daarvoor moet je samenwerken met de website-eigenaar." En ja, zegt De Bode, dat is ook een probleem bij het archiveren van Tweakers. Nieuwsartikelen bewaren kan wel, Plus-artikelen niet.
"We hebben wel goed contact met de webbeheerder", legt De Bode uit. "Vorig jaar is het IP-adres van de crawler gewhitelist, omdat we tegen de firewall aanliepen." Met betrekking tot Tweakers is er een ander probleem: de site stopt niet. "We hebben de limiet op 50GB moeten zetten, want de archiveersoftware was anders nooit klaar. De aanwas van reacties is enorm; er blijven steeds nieuwe reacties onder artikelen komen, zodat de software gewoon niet stopt. We kunnen dagelijks zestien websites tegelijk archiveren, qua opslagcapaciteit en hardware- en softwarebeperkingen. Als we geen limiet in zouden stellen, zou Tweakers.net permanent een van die plekken innemen", zegt De Bode. Hetzelfde geldt overigens voor een site als het Viva-forum. "We hebben een versie van Tweakers.net, maar niet alles. Het is alsof Couperus blijft doorschrijven", zegt Teszelszky. "Op een gegeven moment moet je de archiefsoftware stoppen."
Het liefst zou de KB van Tweakers en andere sites bronbestanden krijgen om de site goed te kunnen opslaan. "Met archiveertechniek lopen we altijd achter op webtechniek en elke vorm van interactiviteit met de oorspronkelijke server is een probleem, omdat daar op een gegeven moment geen contact meer mee is", zegt De Bode. "We willen niet dat een site verdwijnt. Een boodschap aan website-eigenaren zou dan ook zijn: als je wil dat je site bewaard blijft, zorg dan dat hij archiveerbaar is", zegt Teszelszky. "Broken links are broken knowledge. Een website krijgt pas waarde als hij permanent is, en dus gearchiveerd."
Bannerfoto: onurdongel / Getty Images
:strip_exif()/i/2004634838.jpeg?f=fpa)
:strip_exif()/i/2004967972.jpeg?f=fpa)
:strip_exif()/i/1105355992.jpg?f=fpa)
/i/2004483692.png?f=fpa)
:strip_icc():strip_exif()/u/47442/hacktic.jpg?f=community)
:strip_icc():strip_exif()/u/606955/crop5fe33038848c1.jpeg?f=community)
:strip_exif()/u/119562/gunther.gif?f=community)
/u/2820/crop60efd54698630_cropped.png?f=community)
:strip_icc():strip_exif()/u/26132/boxer2.jpg?f=community)
/u/410743/crop5b6a8b5c57575_cropped.png?f=community)