Het Duitse magazine PC Games heeft twee processors aan grafische benchmarks onderworpen en de resultaten vergeleken met die van twee videokaarten. Een cpu met vier kernen aan boord blijkt moeite te hebben om een gpu bij te benen.
PC Games wilde graag te weten komen of de taken van een gpu door een cpu overgenomen kunnen worden. Om hier achter te komen, werden de prestaties van een Intel Core 2 Quad Yorkfield en een Core 2 Duo Conroe aan de hand van verschillende benchmarks vergeleken met de prestaties van een Geforce 8500GT en een Geforce 8800GTX. De cpu's en gpu's werden getest in onder meer 3dMark 2001 SE, 3dMark05 en Crysis, waarbij de processors met behulp van Swiftshader dezelfde berekeningen konden uitvoeren als de videokaarten.
Swiftshader wordt door Transgaming ontwikkeld, het bedrijf dat ook verantwoordelijk is voor de ontwikkeling van Cedega. Het programma is een zogenoemde 'software rasterizer', waarmee processors als het ware de taak van gpu kunnen overnemen. Swiftshader is voorzien van een Direct3d 8- en 9-api en biedt daardoor ondersteuning voor onder meer Shader Model 2.0. Verder is het programma van sse-optimalisaties voorzien en is er ondersteuning voor multicoreprocessors aanwezig.
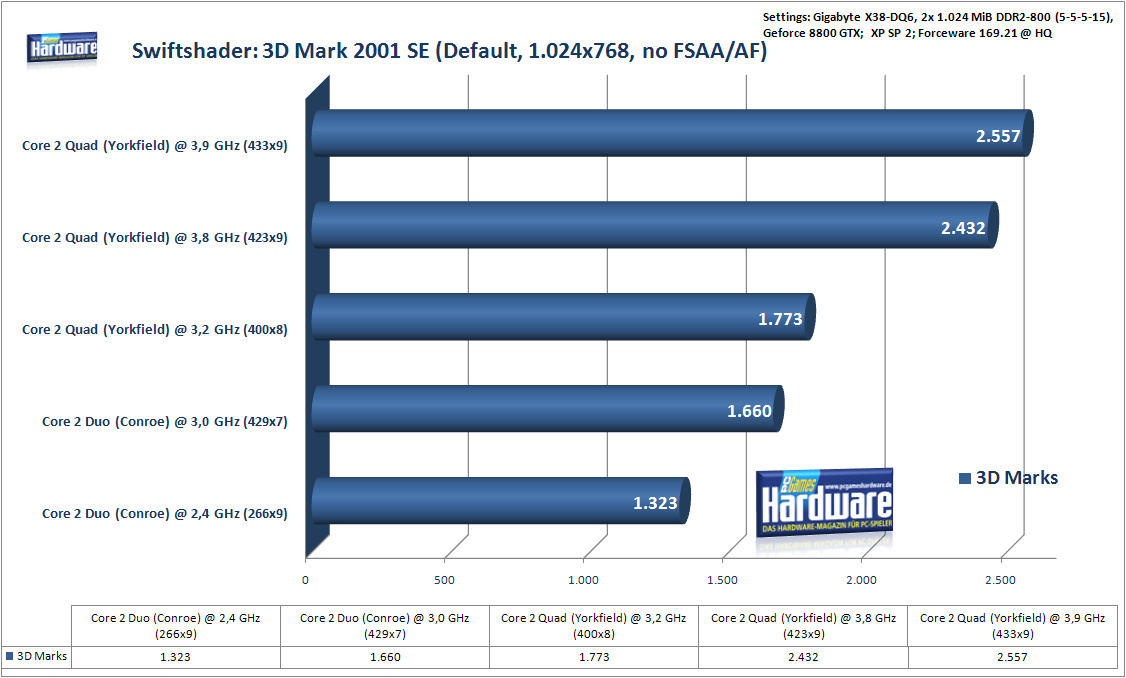
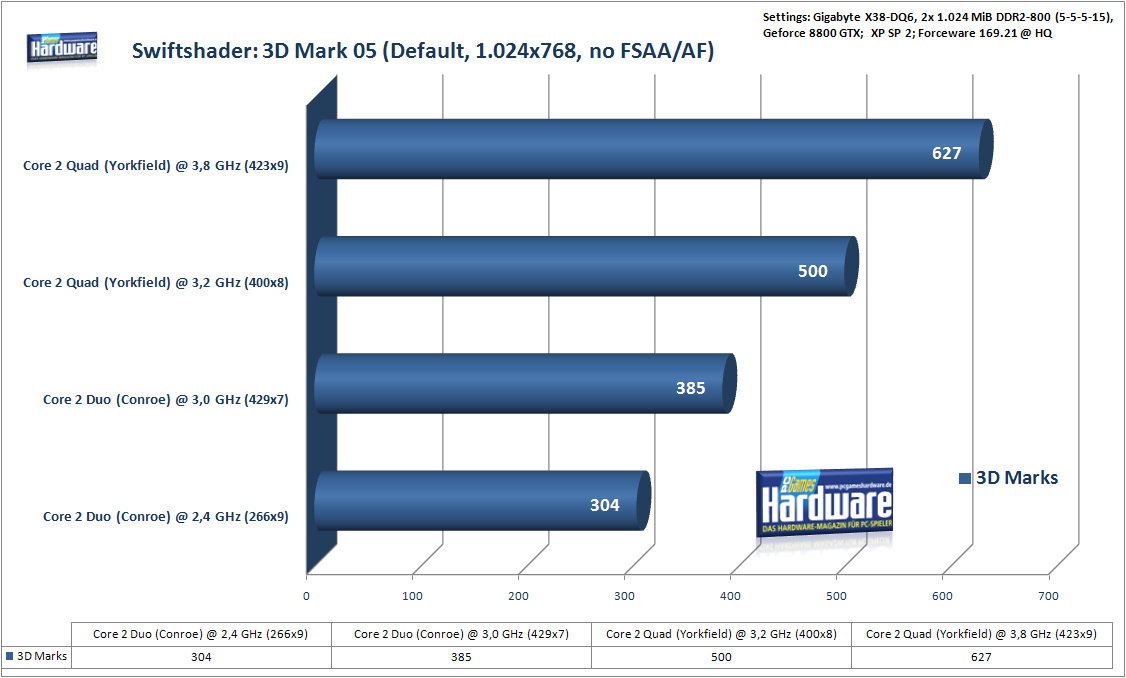
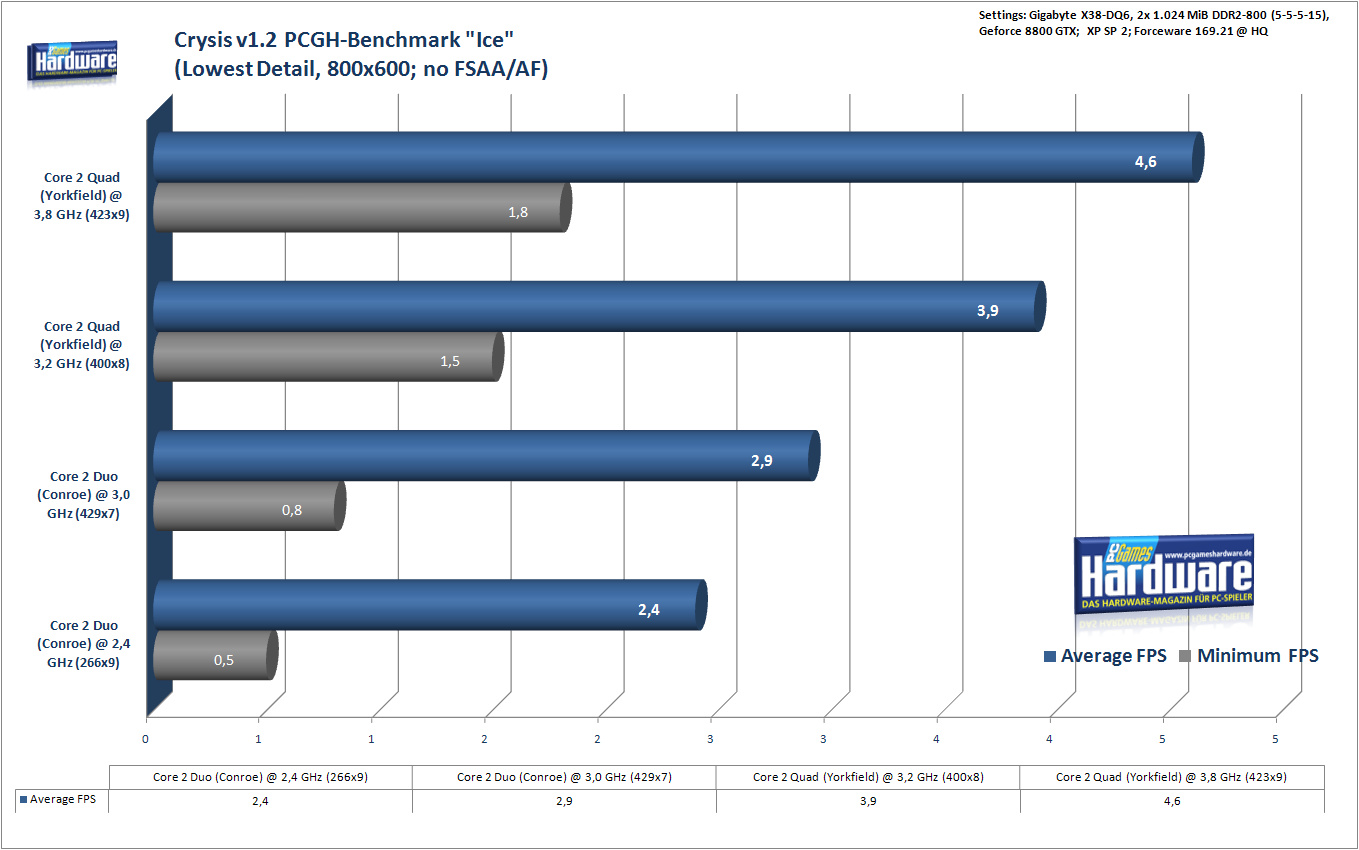
De eerste benchmarks die PC Games heeft gedraaid, was 3dMark 2001 SE waar de Yorkfield-cpu op getest werd. Op een resolutie van 1024 bij 768 pixels zonder fsaa/af zette de processor een score van 2432 punten neer. De Geforce 8800GTX behaalde een score van maar liefst 66.803 punten, bijna 28 keer zo veel als de cpu in zijn eentje. Het verschil tussen een cpu en een gpu wordt in Crysis kleiner: zo wist de Yorkfield een gemiddelde van 5fps in Crysis te behalen, terwijl de Geforce 8500GT 30fps renderde. Daarentegen wist de Conroe-processor net iets meer dan 2fps in Crysis neer te zetten.

/i/1205943054.png?f=fpa)
:strip_exif()/u/115767/needless_to_say.gif?f=community)
:strip_icc():strip_exif()/u/149883/crop57a462252fb63_cropped.jpeg?f=community)
/u/155722/Looneytunes.png?f=community)
/u/192742/crop6894a5b209b51_cropped.png?f=community)
/u/129550/crop56f4f43ec16da.png?f=community)
:strip_icc():strip_exif()/u/124220/Poes%252057x57.jpg?f=community)
/u/27682/icon2.png?f=community)
/u/214894/crop5baaa31f9c4ff_cropped.png?f=community)
/u/30520/crop63626c261c7cb_cropped.png?f=community)
:strip_icc():strip_exif()/u/193469/Popcorn1.jpg?f=community)
/u/11182/peertop.png?f=community)
:strip_icc():strip_exif()/u/54414/stalkerav3_2.jpg?f=community)
:strip_exif()/u/80778/43334.gif?f=community)