Google geeft gebruikers van zijn browser Chrome de mogelijkheid om Gemini-prompts op te slaan en vervolgens met een druk op de knop uit te voeren op een webpagina. Dat zou onder meer handig moeten zijn voor recepten, zegt de techgigant.
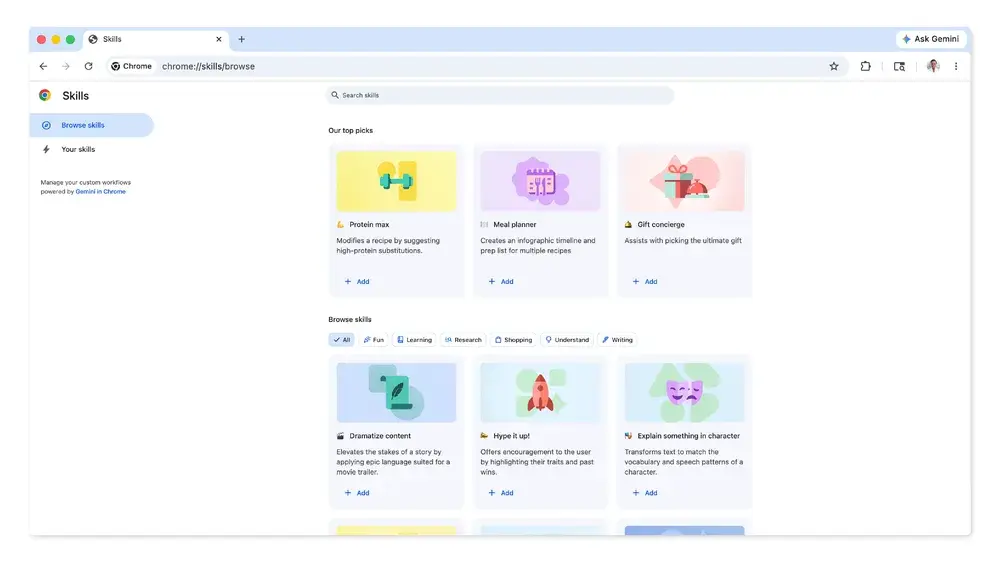
Google noemt die opgeslagen prompts Skills. Die zitten in de zijbalk van Chrome en gebruikers kunnen die op het huidige tabblad of op vooraf geselecteerde tabbladen uitvoeren. Dat moet het gebruik van de AI-tool in de browser sneller en handiger maken, zo redeneert de maker van Chrome en Gemini.
Als voorbeelden waarvoor dat handig kan zijn noemt Google onder meer het vegan maken van recepten of het toevoegen van meer eiwitten aan een recept. Ook zouden gebruikers door meerdere tabbladen te selecteren producten kunnen vergelijken met een enkele prompt. Andere voorbeelden zijn bijvoorbeeld het omzetten van elke tekst naar de tekst voor een filmtrailer en het helpen met uitzoeken van een cadeau.
De functie is vooralsnog beperkt tot gebruik op desktop. Dat werkt in Windows, macOS en ChromeOS. Ook moet de taal op Amerikaans Engels staan. Skills zijn te synchroniseren zolang de gebruiker met hetzelfde account op meerdere computers is ingelogd in de Chrome-browser. Er is ook een downloadwinkel voor al gemaakte Skills die Google beheert.
Of en wanneer de functie in andere talen en op mobiel beschikbaar komt, zegt Google niet. Wel bracht het bedrijf de Gemini-functie Personal Intelligence dinsdag voor het eerst buiten de VS uit. De functie, waarmee Gemini zich kan baseren op mails en kalenderitems van gebruikers, werkt nu ook in India.

:fill(white):strip_exif()/i/2002189289.jpeg?f=thumbmedium)
/i/2008163838.png?f=fpa)
/i/2007887364.png?f=fpa)
/i/2006593348.png?f=fpa)
:strip_exif()/i/2007940130.jpeg?f=fpa)
:strip_icc():strip_exif()/u/488232/domokun_small2.jpg?f=community)
/u/154493/Moderat_ii.png?f=community)
:strip_icc():strip_exif()/u/148932/crop654a13278f8cb_cropped.jpg?f=community)
:strip_icc():strip_exif()/u/112971/me.jpg?f=community)
:strip_icc():strip_exif()/u/295699/crop609bc9a510a14_cropped.jpg?f=community)
/u/427817/crop5e73d28a6dd87.png?f=community)
/u/12436/p1_normal.png?f=community)
/u/237439/cloudy-small-orange.png?f=community)
:strip_icc():strip_exif()/u/639254/crop59a9215b84db0_cropped.jpeg?f=community)