De Russische autoriteiten lijken archive.today en de daaraan gelieerde domeinen te blokkeren. Het gaat onder meer om archive.ph, archive.is en archive.vn. De site wordt aangeprezen als archiveringswebsite, maar wordt in de praktijk vaak gebruikt om betaalmuren te omzeilen.
TechCrunch ontdekte dat de pagina's in het oosten van de Verenigde Staten op bepaalde apparaten niet bereikbaar zijn. Ook voor sommige Tweakers-redacteurs in Nederland zijn de websites slechts beperkt bereikbaar.
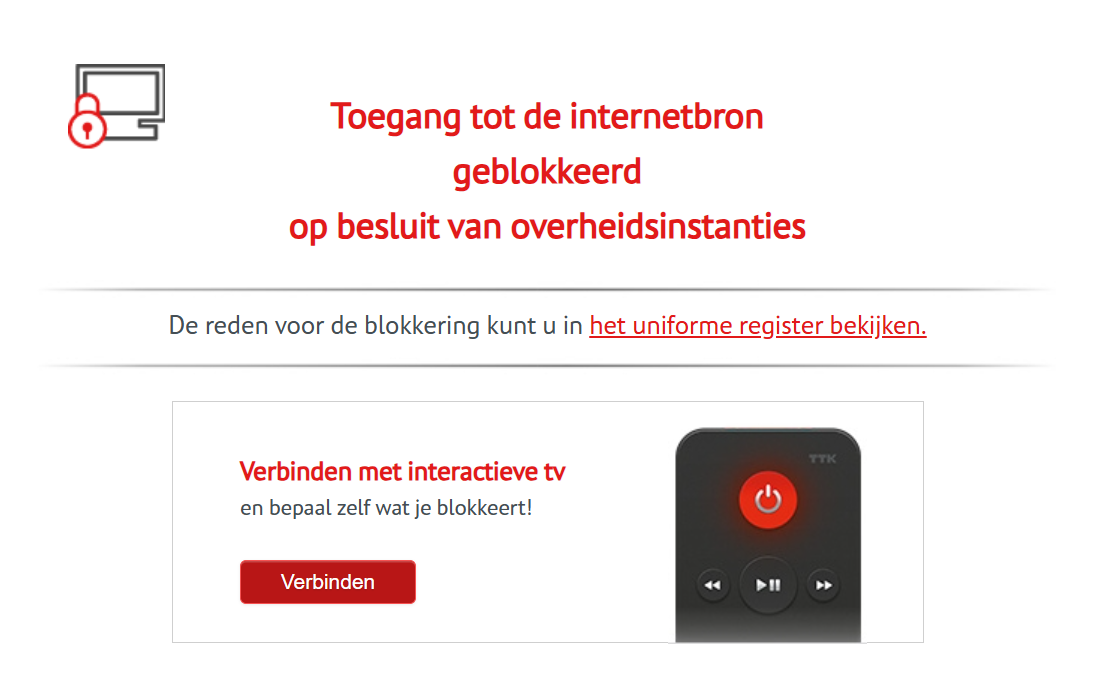
De pagina van archive.today toont op bepaalde apparaten een melding dat toegang tot de website 'op besluit van overheidsinstanties' is geblokkeerd. Daarbij verwijst de website naar een pagina van de Russische telecomautoriteit Roskomnadzor. Volgens TechCrunch geeft de toezichthouder aan dat de toegang tot archive.is beperkt is. Die melding verschijnt niet voor de website archive.today.
Het is niet duidelijk hoe uitgebreid de blokkade werkelijk is of waarom een Russische blokkade invloed heeft op Europese gebruikers. De website archive.ph is op sommige apparaten nog wel bereikbaar. Bovendien redirect archive.today in sommige gevallen naar archive.ph.
De websites liggen al langer onder vuur om hun vermogen om paywalls te omzeilen. Eind vorig jaar eiste de FBI nog dat de registrar van de domeinen de gegevens van de website-eigenaar overhandigde in het kader van een 'strafrechtelijk onderzoek'. Het is niet bekend of er een verband is tussen dit onderzoek en de blokkade. De Finse site Gyrovague deed in 2023 uitgebreid onderzoek naar de websites en stelde toen dat de kans groot is dat de eigenaar is gevestigd in Rusland. De websites staan geheel los van de Amerikaanse non-profit Internet Archive, dat het Archive.org-domein beheert.

:strip_exif()/i/2005085450.jpeg?f=fpa)
/i/2004642236.png?f=fpa)
/i/2007875684.png?f=fpa)
:strip_exif()/i/1392287741.jpeg?f=fpa)
/i/2005046258.png?f=fpa)
/i/2004677134.png?f=fpa)
:strip_exif()/i/1105355992.jpg?f=fpa)
:strip_exif()/u/57723/sgtmajorshutup.gif?f=community)
:strip_icc():strip_exif()/u/219282/crop65bfaacd66e4c_cropped.jpg?f=community)
/u/94596/crop643fb12fd4e6d.png?f=community)
:strip_icc():strip_exif()/u/277895/crop5eda5f3273e75_cropped.jpeg?f=community)
/u/1957000/crop696cfa35c73d9_cropped.png?f=community)
/u/99529/crop5db493c811c0d_cropped.png?f=community)
/u/452542/crop57b8a2dd1446b_cropped.png?f=community)
:strip_icc():strip_exif()/u/230241/crop5db74093e7dc1_cropped.jpeg?f=community)