Reactie op scali :
Ten eerste zou ik het plezierig vinden als je duidelijk maakt op wie je reageert :
Je quote me niet goed.
Ik heb jou niet gequote, en dat lijkt nu wel zo. Ik snap best wel hoe het zit, maar om nou te zeggen dat het
er allemaal duidelijker op wordt... nee dus.
Kijk, ik ben programmeur, en ik weet waar ik over praat
Ik ook. Hebben we dan allebei per defenitie gelijk?
Maarja, de meeste mensen hier hebben er niet echt verstand van, en begrijpen alleen die one-liners als "P4 heeft meer MHz en bandbreedte nodig dan een Athlon"... Ja, in de praktijk is dat vaak zo, maar zeker niet altijd, en wie weet er hoe en waarom?
Ik geloof dat ik in een vorige post reeds redelijk heb aangegeven hoe en waarom.
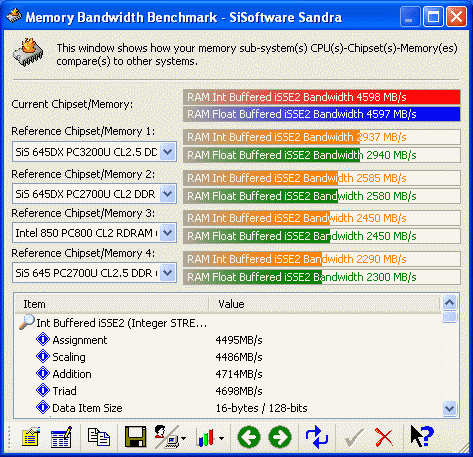
Vaak maar zeker niet altijd.... hoe vaak? Ik doe hier een voorzichtige schatting : 90%. Alleen SSE2 blaast alles weg.
Daar staat dan ook tegenover dat de classic FPU van de PIV echt HEEL ERG bedroevend is en deze ook op ALU gebied
in de Athlon zijn meerdere moet erkennen. Denk aan de barrel-shifting functie die de PIV mist, waardoor
ALLE voor PIII/Athlon geoptimaliseerde software enorm traag wordt met integer verminigvuldigingen.
Verder heb ik nergens een link gelegd tussen SSE2 en kloksnelheid. Ik heb alleen gezegd dat SSE2 een P4 beter kan laten presteren dan een Athlon op dezelfde kloksnelheid, en daar heeft de P4 dus een streepje voor.
Inderdaad. Als software SSE2 ondersteunt is een PIV ALTIJD sneller, zelfs met SDRAM, zelfs op dezelfde clocksnelheid.
Helaas is veel software dat niet, en ook LANG niet alle software die nu gemaakt wordt is dit. MSVC6/7 poepen zelfs
code uit die echt BEDROEVEND presteert op de PIV.
Verder vind ik een Athlon zeker wel achterhaald, toen ie uitkwam in 1999 was het al niet veel beter dan de PIII die in feite nog op de PPRO uit 1995 gebaseerd is.
En er is in die 3 jaar niet veel veranderd. SSE is de enige noemenswaardige verbetering.
Designtechnisch vind ik de Athlon VERUIT superieur aan de PIV. Dit in verband met de ogenschijnlijk 'stomme' bottlenecks die in de PIV zitten.
Zo kan een PIV maar 3 instructies/clock naar zn pipelines dispatchen, terwijl allen zn double-pumped ALU's er al 4 kunnen verwerken.
Ook is de l1 cache van de PIV gewoon te klein voor zo'n CPU.
Dat een athlon niet alle praktisch beschikbare bandbreedte zal benutten heeft dus niks met de efficiency van het geheugen te maken.
Wat is dit nu voor onzin? Geheugen heeft geen efficiency... Dat lees je gewoon, klaar.
Het gaat om het totale systeem. Hoe spreekt de CPU/chipset het geheugen aan? Hoe snel is de bus tussen CPU en geheugen?
En over de efficiency van dat subsystem hadden we het dus.
Het gaat hier om de efficiency van de geheugencontroller natuurlijk... (stom dat ik dat niet vermeld)
En die is dus wel degelijk belangrijk. Anders zou de chipset toch ook niet uitmaken voor je geheugenbandbreedte?
De CPU spreekt geheugen overigens niet direct aan. Dat doet dus de geheugen controller (in de chipset)
Verder is je verhaal over caches m.b.t. het hoofdgeheugen niet zo relevent, associativity/write back policies hebben invloed op de praktische bandbreedte van het cache geheugen, niet op die van het main memory.
Fout dus, cache leest uit mainmem en schrijft naar mainmem. Daar heeft het invloed op.
De manier waarop dat gebeurt, is heel belangrijk, namelijk voor burst-access naar het geheugen.
Maar goed, als je niet weet waar je over praat, dan geeft dat niet hoor. Dat heerst hier.
OK. Ten eerste : cache geheugen leest zelf NIKS!
De memory controller in de chipset regelt het zo dat als de CPU een 64bits datawoord opvraagt, de volgende 64bits datawoorden ook op worden gehaald en naar de cache van de processor worden gestuurd (cache line fill heet dat)
Het enige wat lees/schrijf operaties uitvoert zijn de controllers (main memory controller in chipset, cache memory controller in CPU)
Jouw burst-accesses zijn dus voor een deel automatisch in de access-strategy van de main memory controller
Een programma kan hier natuurlijk ook voor geoptimaliseerd zijn. Daardoor vermindert dan de latency van de reads.
En om mij nou maar gelijk te beschuldigen dat ik niet weet waarover ik praat : dat heb ik wel meer als mensen een discussie niet kunnen 'winnen'.
Een domme dooddoener dus, die helemaal niet nodig is en je post eigenlijk tot flamebait diskwalificeert.
Jij doet het lijken of SSE2 meer bandbreedte genereerd. Dat is dus gewoon klinkklare onzin. SSE2 heeft optimalisaties voor geheugenbenadering omdat de benodigde bandbreedte anders nooit leverbaar zou zijn.
Spreek je jezelf hier nu niet keihard tegen?
Nee. Niet geoptimaliseerde geheugenaccess vergroot de benodigde memory bandbreedte. Dat is dus NIET HETZELFDE ALS dat geoptimaliseerde access de geleverde bandbreedte verhoogt!
Als een CPU uit zn cache leest, doet ie dat met veel meer dan 2.7GB/sec. Is de bandbreedte van het geheugen dan ineens >2,7GB? Tuurlijk niet.
Hij heeft de hele bandbreedte van het geheugen dan niet eens NODIG. Dat wordt namelijk gewoon uberhaupt niet aangesproken.
DAT is wat ik zeg (en in vorige posts al eerder gezegd heb, maar daar trek jij je geloof ik niet zo
erg veel van aan).
Zie het maar zo : als ik belastingkorting krijg, betaal ik minder belasting, en is mijn netto-inkomen groter.
Daar wordt mijn bruto inkomen dus NIET hoger door!
Vervang nu belasting door optimalisatie, netto inkomen door "netto bandbreedte" en bruto inkomen door "praktische geheugenbandbreedte"
benodigde bandbreedte kan je splitsen in "netto bandbreedte" en "verspilling"
Door minder verspilling toe te passen daalt bij gelijkblijvende netto bandbreedte de benodigde bandbreedte. Simpel toch?
Voor programmeurs is het al jaren duidelijk dat handig gebruik van MMX/SSE/SSE2 extensies voor prefetch, write-through, aligned read/write de enige manier is om de geheugeninterface daadwerkelijk optimaal te benutten.
Voor programmeurs is het al jaren duidelijk dat optimalisatie op DIT niveau door de compiler dient te gebeuren!
Ook snijdt jouw argument dat de PIV code cache uit micro ops bestaat geen hout. De data waarop ik bewerkingen wil gaan uitvoeren zou bij een branch-miss ook wel eens ergens anders vandaan moeten kunnen komen.
Dat kost dus bandbreedte.
En als die hele caches zo weinig uit zouden mogen maken i.v.m. loops zoals jij stelt, waarom SPRONG de performance van de PIV dan
vooruit door de verdubbeling van de cache? Waarom zou 'ie dan uberhaupt traag zijn met SDRAM?
Dat jij niet begrijpt dat 3DNow geoptimaliseerde code sneller draait op een Athlon als op een PIV snap ik echt niet.
En het punt wat Carman probeert te maken is dus dat met processor specifieke optimalisaties je ALTIJD voordeel boekt.
En dat het dus een beetje een open deur is om te stellen dat voor de PIV geoptimaliseerde software veel sneller is
dan niet voor de Athlon geoptimaliseerde software.
Bovendien is zijn opmerking dat dit niks met geheugenbandbreedte te maken heeft gewoon waar.
Al met al begin ik het vermoeden te krijgen dat we het over nogal verschillende dingen hebben.
Geheugenbandbreedte is, zoals ik al vaker gesteld heb hier, in mijn optiek de praktisch benutbare
bandbreedte tussen main memory controller en in dit geval DDR333.
Het lijkt erop dat jij geheugen bandbreedte als netto-bandbreedte definieert naar de processor.
Die is natuurlijk wel afhankelijk van de access-patterns door de CPU. Wat overigens nog steeds
niet wegneemt dat de PIV in 'klassieke' software meer verspilling veroorzaakt en zodoende meer.
Zo verder wil ik er geen woord meer aan vuil maken. Als je verder wilt discussieren dan graag per mail : curunir@xs4all.nl
Ik moet bovendien weg


:strip_icc():strip_exif()/u/14521/usericon.jpg?f=community)
:strip_exif()/u/14387/Animation-2.gif?f=community)
:strip_icc():strip_exif()/u/55093/UPpharoah.jpg?f=community)
:strip_icc():strip_exif()/u/26020/senna_small.jpg?f=community)
:strip_exif()/u/2172/crop57acf4ac04e70.gif?f=community)
:strip_icc():strip_exif()/u/31860/ESL988.jpg?f=community)
:strip_icc():strip_exif()/u/23850/aquarius.jpg?f=community)
:strip_icc():strip_exif()/u/15516/crop68cbb0c0e9229_cropped.jpg?f=community)
:strip_icc():strip_exif()/u/14636/crop577420b0bec27_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/42999/kamikaze.jpg?f=community)
:strip_icc():strip_exif()/u/57581/forum40.jpg?f=community)
:strip_icc():strip_exif()/u/53543/NOSTRADAMUS_SMALL.jpg?f=community)
{kind=link}