De computerstoring die vliegtuigen woensdag in de VS urenlang aan de grond hield, kwam niet door een cyberaanval. Dat zegt de Amerikaanse luchtvaartorganisatie FAA. De storing kwam vermoedelijk door een 'corrupt databasebestand', aldus de organisatie.
Behalve dat het gaat om een beschadigd bestand, zegt Federal Aviation Administration niets over de oorzaak in zijn statement. "De FAA gaat door met een onderzoek om de oorzaak van de storing in notice to air missions te bepalen. Wij werken hard door om verder te lokaliseren wat de oorzaken van het probleem waren en nemen alle noodzakelijke stappen om te voorkomen dat het nog een keer gebeurt."
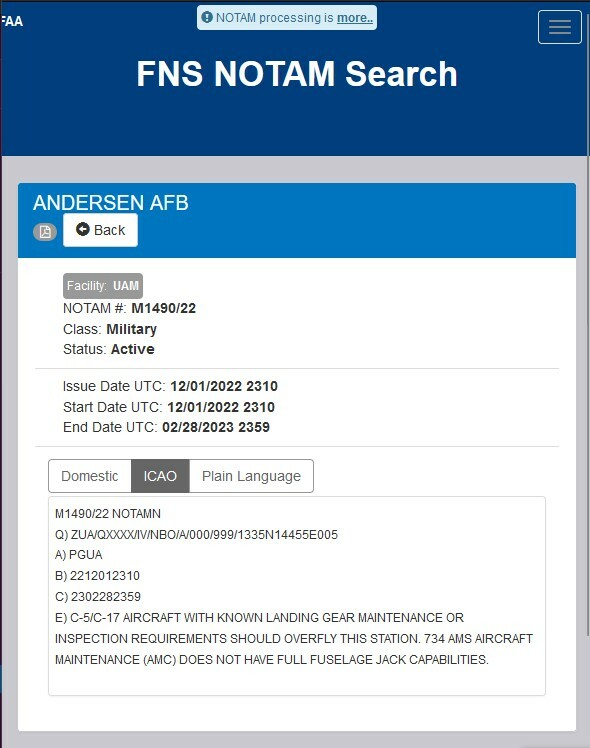
De storing zat in het notam-systeem, waarmee vluchtcrews en luchtvaartleiders op het laatste moment actuele informatie over een vlucht binnenkrijgen. Het gaat dan ook bijvoorbeeld over informatie van de vertrek- of aankomstvliegvelden, of over procedures en het weer op een route. De storing had woensdag tot gevolg dat vliegtuigen in de VS urenlang niet mochten opstijgen of landen.

:strip_exif()/i/2004648158.jpeg?f=fpa)
/i/1334836518.png?f=fpa)
:strip_icc():strip_exif()/u/122857/Ed.jpg?f=community)
:strip_icc():strip_exif()/u/33880/crop5ec3d2d5f2541_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/177406/crop5ca60c3b4a6c7_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/85689/crop65fb0c2ca2763_cropped.jpg?f=community)
:strip_icc():strip_exif()/u/71115/plus222.jpg?f=community)
/u/1190644/crop5ca933f2c3575_cropped.png?f=community)
/u/69680/crop5fd33cb788a9c_cropped.png?f=community)
/u/326977/crop64ca134a287fb_cropped.png?f=community)
:strip_icc():strip_exif()/u/253803/crop5bdafd26303ab_cropped.jpeg?f=community)
/u/12436/p1_normal.png?f=community)
/u/75323/5procentoog.JPG?f=community)
/u/349199/crop69f59caff1e30_cropped.png?f=community)
:strip_icc():strip_exif()/u/31989/skelet_1_60.jpg?f=community)
:strip_exif()/u/677/crop5e62ccc026e5a_cropped.gif?f=community)
:strip_icc():strip_exif()/u/249917/jaapschaap.jpg?f=community)
/u/62384/crop61891f444d6e9.png?f=community)
/u/41514/crop5c3b77c8badbf_cropped.png?f=community)
:strip_exif()/u/67404/C64.gif?f=community)
/u/94596/crop643fb12fd4e6d.png?f=community)
:strip_exif()/u/113834/crop5cf7d28f8e445_cropped.gif?f=community)
:strip_exif()/u/467778/crop5d7a5dd1f296a.gif?f=community)
:strip_exif()/u/269744/crop61a1397ea0399_cropped.gif?f=community)
:strip_icc():strip_exif()/u/64489/hoogtevorst.jpg?f=community)
:strip_exif()/u/477707/crop633ed00537753_cropped.gif?f=community)