De Talos-onderzoeksafdeling van Cisco heeft malware geanalyseerd die via dns communiceert. De zogenaamde Dnsmessenger-trojan kan zo PowerShell-scripts opvragen uit de txt-record om detectie te voorkomen.
In de analyse schrijven de onderzoekers dat de trojan op deze manier communiceert met de c2-server van de aanvallers. De malware is opvallend, omdat deze variant vergaande stappen neemt om verborgen te blijven. De trojan wordt verspreid door middel van een geïnfecteerd Word-document, dat de indruk wekt beveiligd te zijn met software van McAfee. Het bestand kan bijvoorbeeld door een phishing-e-mail naar een bepaald doelwit worden gestuurd.
De malware werkt met PowerShell om een backdoor aan te brengen in het systeem van het slachtoffer. Om dat te bereiken, controleert de kwaadaardige software eerst of er beheerderstoegang is en welke versie van PowerShell op het systeem draait. In de volgende fase maakt de Dnsmessenger-trojan gebruik van een willekeurige voorgeprogrammeerde domeinnaam voor dns-verzoeken. Door middel van het ophalen van de txt-record is het voor de aanvallers mogelijk om de trojan van verschillende commando's te voorzien.
De in de txt-records opgenomen PowerShell-commando's laten de aanvaller op die manier Windows-functies op het geïnfecteerde systeem aansturen. Ook is het mogelijk de gegenereerde output van applicaties vervolgens weer terug te sturen via een dns-verzoek. Volgens de onderzoekers is een dergelijke aanval moeilijk te detecteren, omdat organisaties vaak geen filters gebruiken voor dns. Daardoor is deze techniek geschikt voor doelgerichte aanvallen.
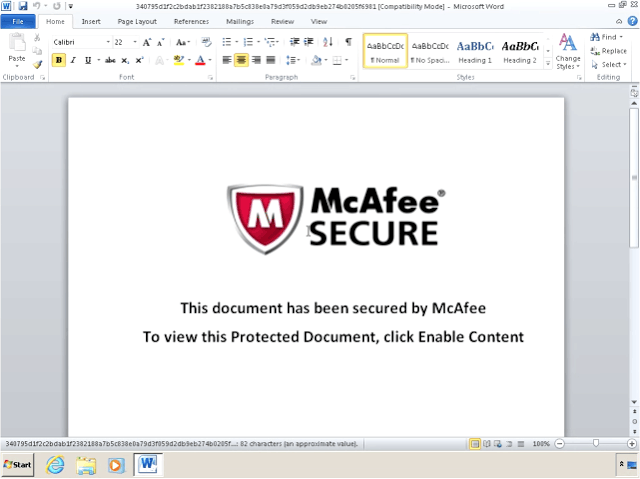 Het kwaadaardige Word-bestand
Het kwaadaardige Word-bestand

/i/2004804258.png?f=fpa)
/i/1289734951.png?f=fpa)
:strip_exif()/i/1096398313.jpg?f=fpa)
/i/1300720051.png?f=fpa)
/i/1277037256.png?f=fpa)
/i/1161959703.png?f=fpa)
/i/1323271799.png?f=fpa)
:strip_exif()/u/119419/candc-60px.gif?f=community)
/u/69397/crop5b20ed488c1d9_cropped.png?f=community)
:strip_exif()/u/655679/60x60falloutav-vb.gif?f=community)
/u/3626/front-kabels.png?f=community)
:strip_icc():strip_exif()/u/235816/crop596740581e453_cropped.jpeg?f=community)
/u/12436/p1_normal.png?f=community)
:strip_exif()/u/70496/glowmouse2.gif?f=community)
:strip_icc():strip_exif()/u/342772/switch2.jpg?f=community)
/u/298866/crop5ef045407bab9_cropped.png?f=community)
:strip_icc():strip_exif()/u/54320/crop66d223ef9f585_cropped.jpg?f=community)
:strip_icc():strip_exif()/u/174665/crop5f3505845c31b_cropped.jpeg?f=community)
/u/417613/crop5df91c60a28d2.png?f=community)
:strip_exif()/u/77058/tick.gif?f=community)
/u/94596/crop643fb12fd4e6d.png?f=community)
:strip_icc():strip_exif()/u/40508/loco.jpg?f=community)
/u/117492/crop5f8ef6919e9fc_cropped.png?f=community)
:strip_icc():strip_exif()/u/309482/crop59ababfec0ec7_cropped.jpeg?f=community)
{kind=link}