Google gebruikt een nieuw akoestisch model voor de spraakherkenning van zijn Google-app op Android en iOS. Hierdoor zouden uitgesproken zoekopdrachten accurater en sneller herkend moeten worden, ook als er omgevingsgeluid is.
Google gebruikt voor de spraakherkenning nu het long short-term memory-type van recurrent neural networks. Dit type netwerken kan ook temporele inputs goed classificeren, verwerken en voorspellen als er lange-termijnafhankelijkheden een rol spelen. In de woorden van Google heet het dat de netwerken informatie langer kunnen 'onthouden' door gebruik van geheugencellen in de netwerken en geavanceerde gating-mechanismen.
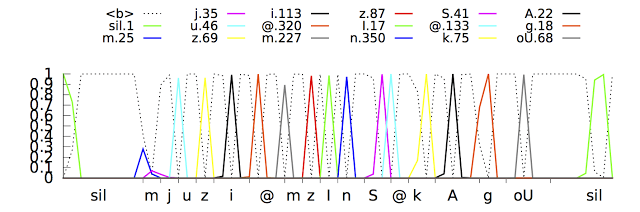
Het zoekbedrijf noemt als voorbeeld het woord 'museum' uitgesproken in het Engels. Dat woord wordt fonetisch gespeld als /m j u z i @ m/. Als de gebruikers de /u/ uitspreekt, is de klankproductie van de /j/ en de /m/ daar aan voorafgegaan door de bewegingen in de mond- en keelholte. De rnn zouden dit soort vloeiende overgangen kunnen detecteren.
Google moest voor deze 'vloeiende detectie' de modellen trainen om de fonemen of kleinste klankeenheden te herkennen, zonder dat ze voor elke tijdsinterval afzonderlijk een voorspelling hoefden te maken. Bij deze training maken de modellen een reeks pieken die de opeenvolgende fonetische eenheden in het spraaksignaal weergeven. Dit stelt het model in staat de fonemen verder van te voren en daardoor accurater te voorspellen. Het model zorgde ook voor een vertraging van 300 milliseconden, schrijft Google. Door verdere training heeft het bedrijf dit ongedaan weten te maken.
Niet alleen is de herkenning accurater en sneller, ook is de invloed van omgevingsgeluiden verminderd en vergt het model minder rekenkracht. Google publiceerde in juli al de onderzoeksresultaten van zijn verbeteringen bij het herkennen van spraak.

:strip_exif()/i/1399535558.jpeg?f=fpa)
/i/1245595122.png?f=fpa)
/i/1261488923.png?f=fpa)
/i/2000658159.png?f=fpa)
/i/1286620585.png?f=fpa)
/i/1369161125.png?f=fpa)
:strip_exif()/i/1345729991.gif?f=fpa)
/i/1292834694.png?f=fpa)
:strip_exif()/u/73/koelkast-lach.gif?f=community)
/u/12607/crop5fa30891b335d.png?f=community)
/u/152864/crop59af8ee117886_cropped.png?f=community)
:strip_icc():strip_exif()/u/224856/1181572371.jpg?f=community)
/u/398897/crop696ca88c265db_cropped.png?f=community)
:strip_icc():strip_exif()/u/302313/crop58766c1b38923_cropped.jpeg?f=community)
/u/117810/cupcake2.png?f=community)
/u/511203/crop56d5bbf018837.png?f=community)
/u/85011/crop65747d648e683_cropped.png?f=community)
:strip_icc():strip_exif()/u/41502/breezah.jpg?f=community)
:strip_icc():strip_exif()/u/436133/crop5cde7e483a487_cropped.jpeg?f=community)